在cross_val_score和GridSearchCV上進行多指標評估的演示?
在本案例中,我們通過將評分參數(scoring)設置為多個評估指標的列表、或將評估指標名稱映射到評分器可調用項的字典,來執行多個評估指標的搜索。
所有的打分器都在cv_results_字典中,并且可以使用以'_ <scorer_name>'結尾的鍵(“ mean_test_precision”,“ rank_test_precision”等)進行調用和獲取。
best_estimator_,best_index_,best_score_和best_params_對應于設置為refit屬性的打分器(鍵)。
# 作者: Raghav RV <rvraghav93@gmail.com>
# 執照: BSD
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_hastie_10_2
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
print(__doc__)
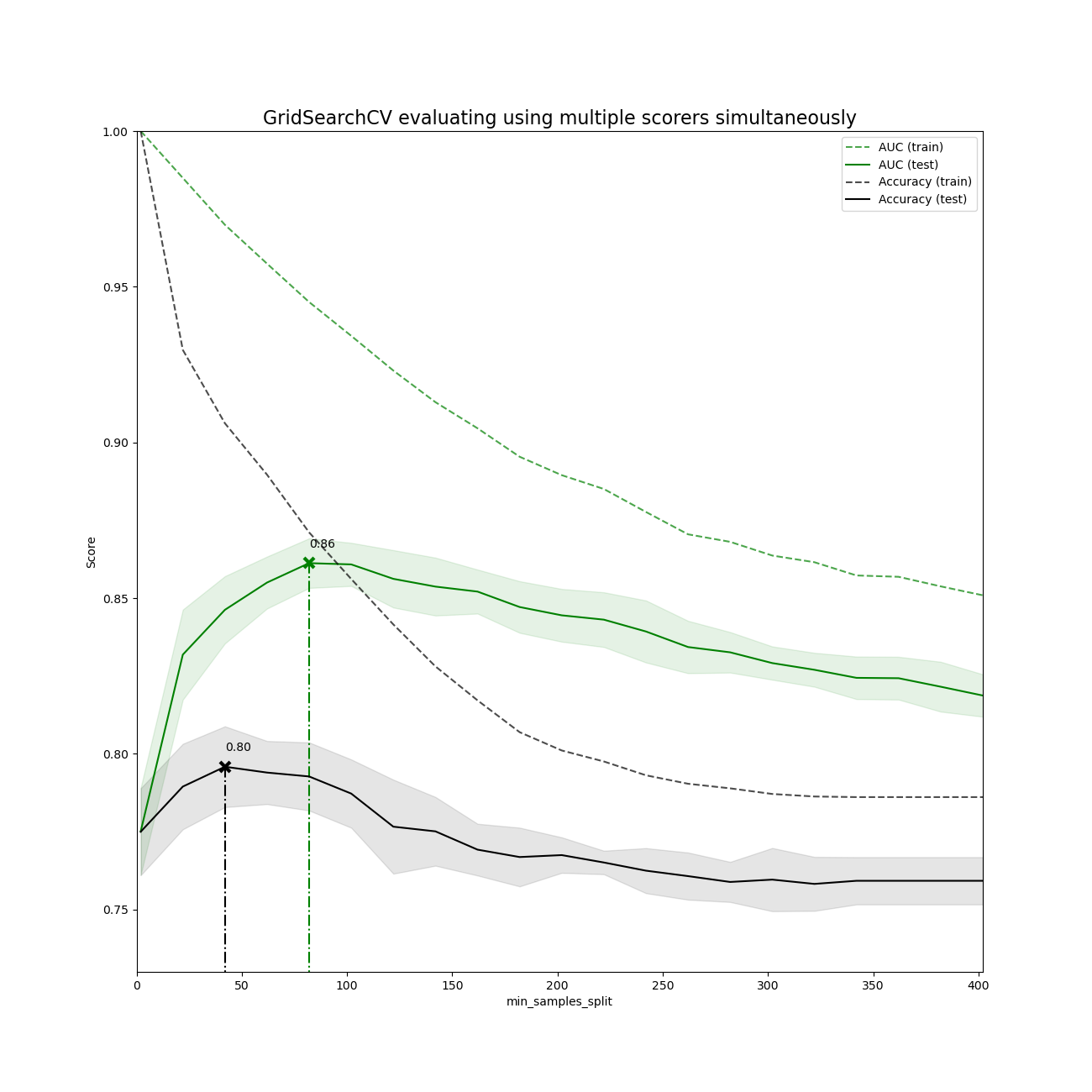
使用多個評估指標運行GridSearchCV
X, y = make_hastie_10_2(n_samples=8000, random_state=42)
# 評分器可以是預定義的度量標準字符串之一,也可以是可調用的評分器,例如make_scorer返回的評分器
scoring = {'AUC': 'roc_auc', 'Accuracy': make_scorer(accuracy_score)}
'''
設置refit ='AUC',使用具有最佳交叉驗證AUC得分的參數設置重新擬合整個數據集上的估算器
可以在gs.best_estimator_處獲得該估算器,還可以使用gs.best_score_,gs.best_params_和gs.best_index_獲得參數
'''
gs = GridSearchCV(DecisionTreeClassifier(random_state=42),
param_grid={'min_samples_split': range(2, 403, 10)},
scoring=scoring, refit='AUC', return_train_score=True)
gs.fit(X, y)
results = gs.cv_results_
繪制結果
plt.figure(figsize=(13, 13))
plt.title("GridSearchCV evaluating using multiple scorers simultaneously",
fontsize=16)
plt.xlabel("min_samples_split")
plt.ylabel("Score")
ax = plt.gca()
ax.set_xlim(0, 402)
ax.set_ylim(0.73, 1)
# 從MaskedArray獲取常規的numpy數組
X_axis = np.array(results['param_min_samples_split'].data, dtype=float)
for scorer, color in zip(sorted(scoring), ['g', 'k']):
for sample, style in (('train', '--'), ('test', '-')):
sample_score_mean = results['mean_%s_%s' % (sample, scorer)]
sample_score_std = results['std_%s_%s' % (sample, scorer)]
ax.fill_between(X_axis, sample_score_mean - sample_score_std,
sample_score_mean + sample_score_std,
alpha=0.1 if sample == 'test' else 0, color=color)
ax.plot(X_axis, sample_score_mean, style, color=color,
alpha=1 if sample == 'test' else 0.7,
label="%s (%s)" % (scorer, sample))
best_index = np.nonzero(results['rank_test_%s' % scorer] == 1)[0][0]
best_score = results['mean_test_%s' % scorer][best_index]
# 在以叉(x)標記的那個最佳評估指標的最佳得分上繪制一條垂直虛線
ax.plot([X_axis[best_index], ] * 2, [0, best_score],
linestyle='-.', color=color, marker='x', markeredgewidth=3, ms=8)
# 注釋該得分手的評估指標
ax.annotate("%0.2f" % best_score,
(X_axis[best_index], best_score + 0.005))
plt.legend(loc="best")
plt.grid(False)
plt.show()
輸出:
腳本的總運行時間:(0分鐘27.117秒)