混合型列式轉換器?
本示例說明了如何使用sklearn.compose.ColumnTransformer將不同的預處理和特征提取管道應用于特征的不同子集。 這對于包含異構數據類型的數據集特別方便,因為我們可能要縮放數字特征并對分類特征進行獨熱編碼。
在此示例中,數字數據在均值輸入后進行標準縮放,而分類數據在使用新類別(“缺失”)插入缺失值后進行一次熱編碼。
此外,我們展示了兩種不同的方式將列分配給特定的預處理器:按列名稱和按列數據類型。
最后,使用sklearn.pipeline.Pipeline以及簡單的分類模型將預處理管道集成到完整的預測管道中。
# 作者: Pedro Morales <part.morales@gmail.com>
#
# 執照: BSD 3 clause
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.datasets import fetch_openml
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, GridSearchCV
np.random.seed(0)
# 從網站https://www.openml.org/d/40945加載數據
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
# 另外,X和y可以直接從frame屬性獲得:
# X = titanic.frame.drop('survived', axis=1)
# y = titanic.frame['survived']
通過按名稱選擇列來使用ColumnTransformer
我們將使用以下功能訓練分類器:
數值特征:
年齡:浮點數;
票價:浮點數。
分類特征:
出發:編碼為字符串{'C','S','Q'}的類別;
性別:編碼為字符串{'female','male'}的類別;
pclass:有序整數{1、2、3}。
我們為數字和分類數據創建預處理管道。
numeric_features = ['age', 'fare']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_features = ['embarked', 'sex', 'pclass']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# 將分類器追加到預處理管道。
# 現在我們有了完整的預測管道。
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression())])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
clf.fit(X_train, y_train)
print("model score: %.3f" % clf.score(X_test, y_test))
輸出:
model score: 0.790
Pipeline的HTML表示
在Jupyter notebook中打印管道時,估算器的HTML表示將顯示如下:
from sklearn import set_config
set_config(display='diagram')
clf
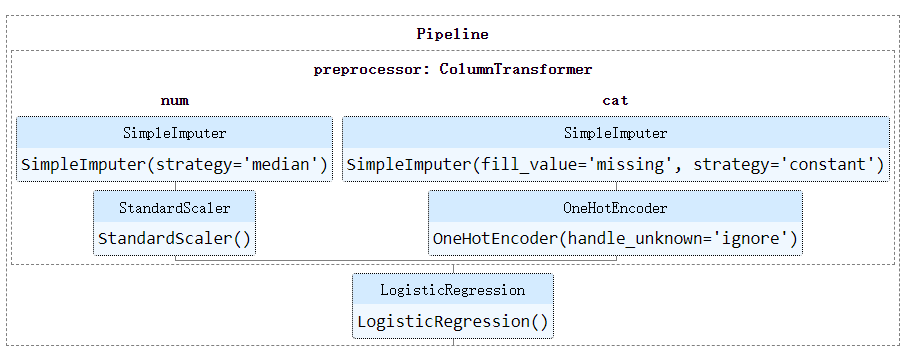 通過按數據類型選擇列來使用ColumnTransformer
通過按數據類型選擇列來使用ColumnTransformer
在處理清理的數據集時,可以通過使用列的數據類型來決定是否將列視為數字或分類特征來自動進行預處理。 sklearn.compose.make_column_selector提供了這種可能性。 首先,為了簡化示例,我們僅選擇列的子集。
subset_feature = ['embarked', 'sex', 'pclass', 'age', 'fare']
X = X[subset_feature]
然后,我們內省有關每種列數據類型的信息。
X.info()
輸出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 embarked 1307 non-null category
1 sex 1309 non-null category
2 pclass 1309 non-null float64
3 age 1046 non-null float64
4 fare 1308 non-null float64
dtypes: category(2), float64(3)
memory usage: 33.6 KB
我們可以觀察到,在使用fetch_openml加載數據時,將embarked和sex列標記為category列。 因此,我們可以使用此信息將分類列分派給categorical_transformer,將其余列分派給numeric_transformer。
注意實際上,您將必須處理自己的列數據類型。 如果要將某些列視為類別,則必須將它們轉換為類別列。 如果您使用的是熊貓,則可以參考其有關分類數據的文檔。
from sklearn.compose import make_column_selector as selector
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, selector(dtype_exclude="category")),
('cat', categorical_transformer, selector(dtype_include="category"))
])
# 重現相同的匹配/得分過程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
clf.fit(X_train, y_train)
print("model score: %.3f" % clf.score(X_test, y_test))
輸出:
model score: 0.794
在網格搜索中使用預測管道
網格搜索還可以在ColumnTransformer對象中定義的不同預處理步驟以及作為管道的一部分的分類器的超參數中執行。 我們將使用sklearn.model_selection.GridSearchCV搜索數值預處理的不當策略和邏輯回歸的正則化參數。
param_grid = {
'preprocessor__num__imputer__strategy': ['mean', 'median'],
'classifier__C': [0.1, 1.0, 10, 100],
}
grid_search = GridSearchCV(clf, param_grid, cv=10)
grid_search.fit(X_train, y_train)
print(("best logistic regression from grid search: %.3f"
% grid_search.score(X_test, y_test)))
輸出:
best logistic regression from grid search: 0.794
腳本的總運行時間:(0分鐘3.461秒)