sklearn.datasets.make_gaussian_quantiles?
sklearn.datasets.make_gaussian_quantiles(*, mean=None, cov=1.0, n_samples=100, n_features=2, n_classes=3, shuffle=True, random_state=None)
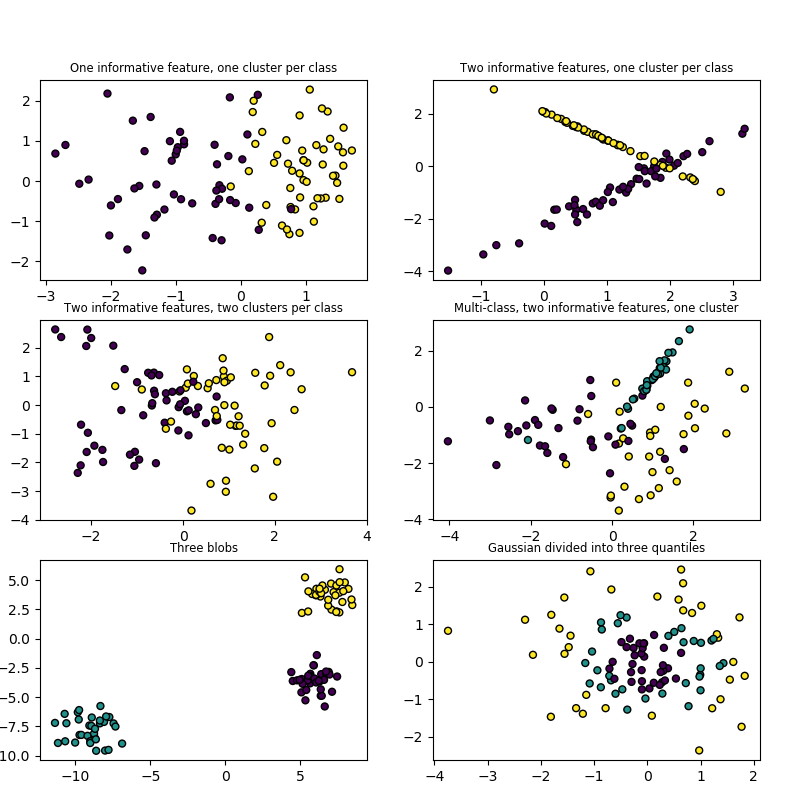
通過分位數生成各向同性的高斯并標記樣本
通過采用多維標準正態分布并定義由嵌套的同心多維球體分隔的類,以使每個類中的樣本數量大致相等(分配)。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| mean | array of shape [n_features], optional (default=None) 多維正態分布的均值。如果為None,則使用原點(0,0,…)。 |
| cov | float, optional (default=1.) 協方差矩陣將是該值乘以單位矩陣。該數據集僅產生對稱正態分布。 |
| n_samples | int, optional (default=100) 總點數在各類之間平均分配。 |
| n_features | int, optional (default=2) 每個樣本的特征數量。 |
| n_classes | int, optional (default=3) 類的數量。 |
| shuffle | boolean, optional (default=True) shuffle樣本。 |
| random_state | int, RandomState instance, default=None 確定用于生成數據集的隨機數生成。 為多個函數調用傳遞可重復輸出的int值。 請參閱詞匯表。 |
| 返回值 | 說明 |
|---|---|
| X | array of shape [n_samples, n_features] 生成的樣本。 |
| y | array of shape [n_samples] 每個樣本的分位數隸屬關系的整數標簽。 |
注
數據集來自Zhu等人[1]。
參考
1
Zhu, H. Zou, S. Rosset, T. Hastie, “Multi-class AdaBoost”, 2009.