增量PCA?
當要分解的數據集太大,無法適應內存時,通常使用增量主成分分析(IPCA)代替主成分分析(PCA)。它仍然依賴于輸入數據的特征,但是更改批處理的大小可以控制內存的使用。
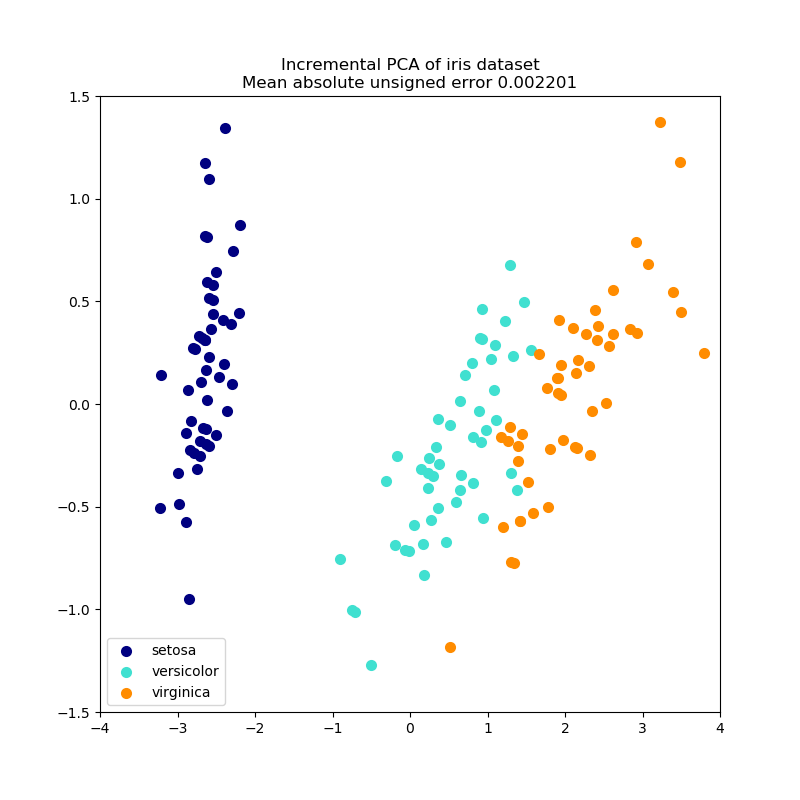
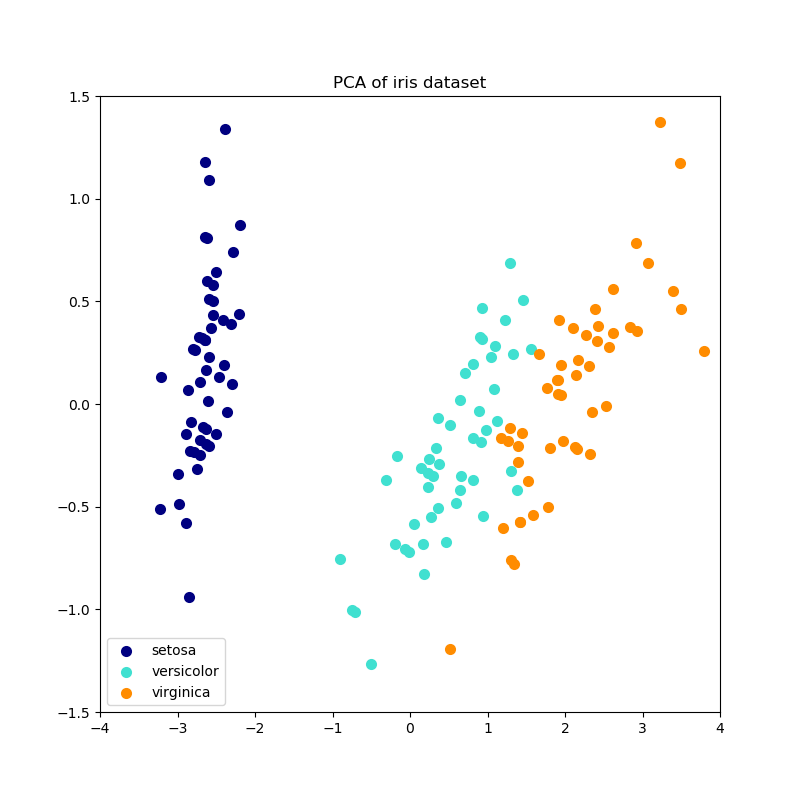
此示例可用作視覺檢查,以確保IPCA能夠找到與PCA類似的數據投影(到符號翻轉),同時一次只處理幾個樣本。這可以被看作是一個“玩具示例”,因為IPCA是針對不適合主內存的大型數據集的,需要增量方法。
print(__doc__)
# Authors: Kyle Kastner
# License: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA, IncrementalPCA
iris = load_iris()
X = iris.data
y = iris.target
n_components = 2
ipca = IncrementalPCA(n_components=n_components, batch_size=10)
X_ipca = ipca.fit_transform(X)
pca = PCA(n_components=n_components)
X_pca = pca.fit_transform(X)
colors = ['navy', 'turquoise', 'darkorange']
for X_transformed, title in [(X_ipca, "Incremental PCA"), (X_pca, "PCA")]:
plt.figure(figsize=(8, 8))
for color, i, target_name in zip(colors, [0, 1, 2], iris.target_names):
plt.scatter(X_transformed[y == i, 0], X_transformed[y == i, 1],
color=color, lw=2, label=target_name)
if "Incremental" in title:
err = np.abs(np.abs(X_pca) - np.abs(X_ipca)).mean()
plt.title(title + " of iris dataset\nMean absolute unsigned error "
"%.6f" % err)
else:
plt.title(title + " of iris dataset")
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.axis([-4, 4, -1.5, 1.5])
plt.show()
腳本的總運行時間:(0分0.232秒)