欠擬合與過擬合?
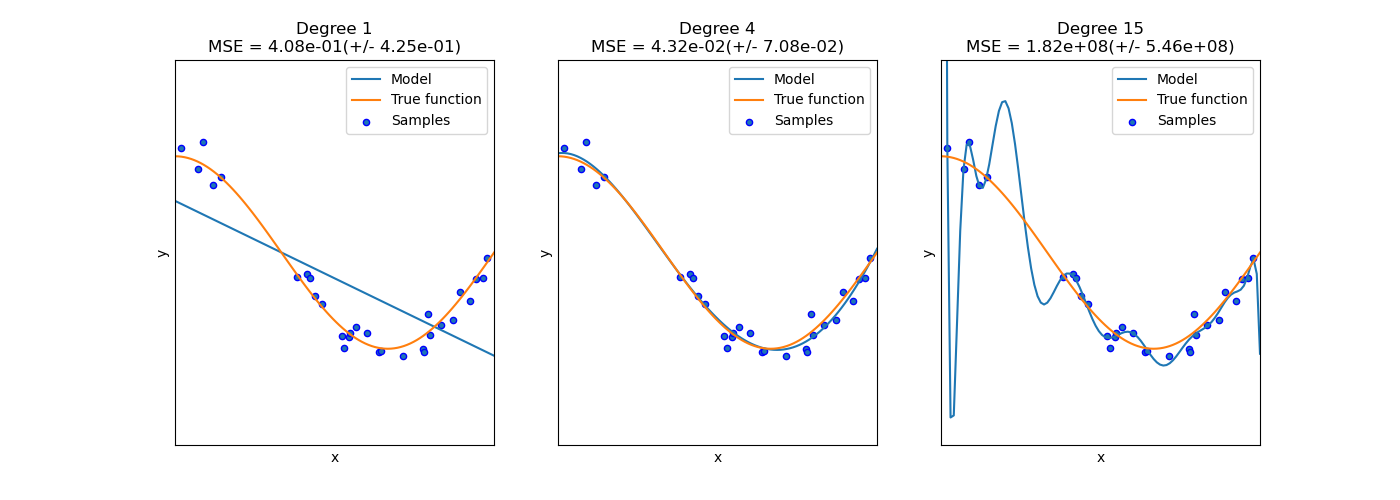
此案例展現了擬合不足和擬合過度的問題,以及如何使用具有多項式特征的線性回歸來估計非線性函數。該圖顯示了我們要估計的函數,它是余弦函數的一部分。 此外,還將顯示來自真實函數的樣本以及不同模型的近似值。這些模型具有不同程度的多項式特征。我們可以看到線性函數(階數為1的多項式)不足以擬合訓練樣本。 這稱為欠擬合。4次多項式幾乎完美地逼近了真實的函數。但是,對于較高的次數,模型將過度擬合訓練數據,即模型會學習訓練數據的噪聲。我們通過使用交叉驗證來定量評估過度擬合/不足擬合。我們在驗證集上計算均方誤差(MSE),該誤差越高,模型從訓練數據正確擬合、學到真實函數的可能性就越小。
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
def true_fun(X):
return np.cos(1.5 * np.pi * X)
np.random.seed(0)
n_samples = 30
degrees = [1, 4, 15]
X = np.sort(np.random.rand(n_samples))
y = true_fun(X) + np.random.randn(n_samples) * 0.1
plt.figure(figsize=(14, 5))
for i in range(len(degrees)):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
polynomial_features = PolynomialFeatures(degree=degrees[i],
include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([("polynomial_features", polynomial_features),
("linear_regression", linear_regression)])
pipeline.fit(X[:, np.newaxis], y)
# Evaluate the models using crossvalidation
scores = cross_val_score(pipeline, X[:, np.newaxis], y,
scoring="neg_mean_squared_error", cv=10)
X_test = np.linspace(0, 1, 100)
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), label="True function")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x")
plt.ylabel("y")
plt.xlim((0, 1))
plt.ylim((-2, 2))
plt.legend(loc="best")
plt.title("Degree {}\nMSE = {:.2e}(+/- {:.2e})".format(
degrees[i], -scores.mean(), scores.std()))
plt.show()
腳本的總運行時間:(0分鐘0.229秒)