嵌套與非嵌套交叉驗證?
本案例在鳶尾花數據集的分類器上比較了非嵌套和嵌套的交叉驗證策略。嵌套交叉驗證(CV)通常用于訓練還需要優化超參數的模型。嵌套交叉驗證估計基礎模型及其(超)參數搜索的泛化誤差。選擇最大化非嵌套交叉驗證結果的參數會使模型偏向數據集,從而產生過于樂觀的得分。
沒有嵌套CV的模型選擇使用相同的數據來調整模型參數并評估模型性能。因此,信息可能會“滲入”模型并過擬合數據。這種影響的大小主要取決于數據集的大小和模型的穩定性。有關這些問題的分析,請參見Cawley and Talbot(引用1)。
為避免此問題,嵌套CV有效地使用了一系列訓練/驗證/測試集拆分。在內部循環(在此由GridSearchCV執行)中,通過將模型擬合到每個訓練集來近似最大化分數,然后在驗證集上選擇(超)參數時直接將其最大化。在外部循環中(此處為cross_val_score),通過對幾個數據集拆分中的測試集得分求平均值來估計泛化誤差。
下面的示例使用帶有非線性核的支持向量分類器,通過網格搜索構建具有優化超參數的模型。通過比較非嵌套和嵌套CV策略得分之間的差異,我們可以比較它們的效果。
同時查看:
引用:
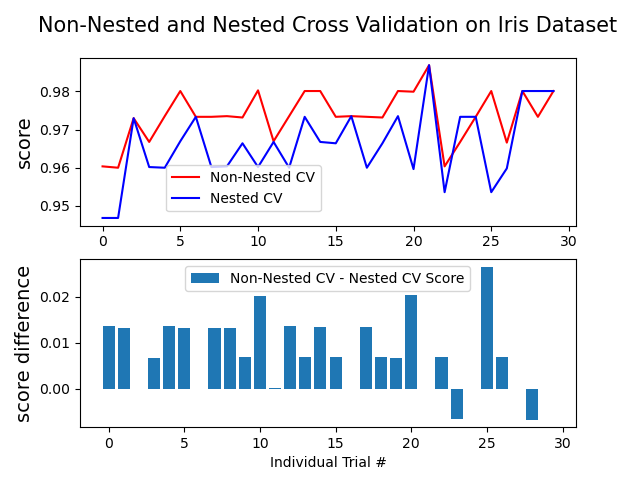
輸出:
Average difference of 0.007581 with std. dev. of 0.007833.
輸入:
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV, cross_val_score, KFold
import numpy as np
print(__doc__)
# 隨機試驗次數
NUM_TRIALS = 30
# 導入數據集
iris = load_iris()
X_iris = iris.data
y_iris = iris.target
# 設置參數的可能值以優化
p_grid = {"C": [1, 10, 100],
"gamma": [.01, .1]}
# 我們將使用帶有“ rbf”內核的支持向量分類器
svm = SVC(kernel="rbf")
# 存儲分數的數組
non_nested_scores = np.zeros(NUM_TRIALS)
nested_scores = np.zeros(NUM_TRIALS)
# 每次試用循環
for i in range(NUM_TRIALS):
# 獨立于數據集,為內部和外部循環選擇交叉驗證技術。
# 例如“ GroupKFold”,“ LeaveOneOut”,“ LeaveOneGroupOut”等。
inner_cv = KFold(n_splits=4, shuffle=True, random_state=i)
outer_cv = KFold(n_splits=4, shuffle=True, random_state=i)
# 非嵌套參數搜索和評分
clf = GridSearchCV(estimator=svm, param_grid=p_grid, cv=inner_cv)
clf.fit(X_iris, y_iris)
non_nested_scores[i] = clf.best_score_
# 帶有參數優化的嵌套簡歷
nested_score = cross_val_score(clf, X=X_iris, y=y_iris, cv=outer_cv)
nested_scores[i] = nested_score.mean()
score_difference = non_nested_scores - nested_scores
print("Average difference of {:6f} with std. dev. of {:6f}."
.format(score_difference.mean(), score_difference.std()))
# 嵌套和非嵌套CV在每個試驗中的得分
plt.figure()
plt.subplot(211)
non_nested_scores_line, = plt.plot(non_nested_scores, color='r')
nested_line, = plt.plot(nested_scores, color='b')
plt.ylabel("score", fontsize="14")
plt.legend([non_nested_scores_line, nested_line],
["Non-Nested CV", "Nested CV"],
bbox_to_anchor=(0, .4, .5, 0))
plt.title("Non-Nested and Nested Cross Validation on Iris Dataset",
x=.5, y=1.1, fontsize="15")
# Plot bar chart of the difference.
plt.subplot(212)
difference_plot = plt.bar(range(NUM_TRIALS), score_difference)
plt.xlabel("Individual Trial #")
plt.legend([difference_plot],
["Non-Nested CV - Nested CV Score"],
bbox_to_anchor=(0, 1, .8, 0))
plt.ylabel("score difference", fontsize="14")
plt.show()
腳本的總運行時間:(0分鐘6.053秒)