支持向量機:有權重的樣本?
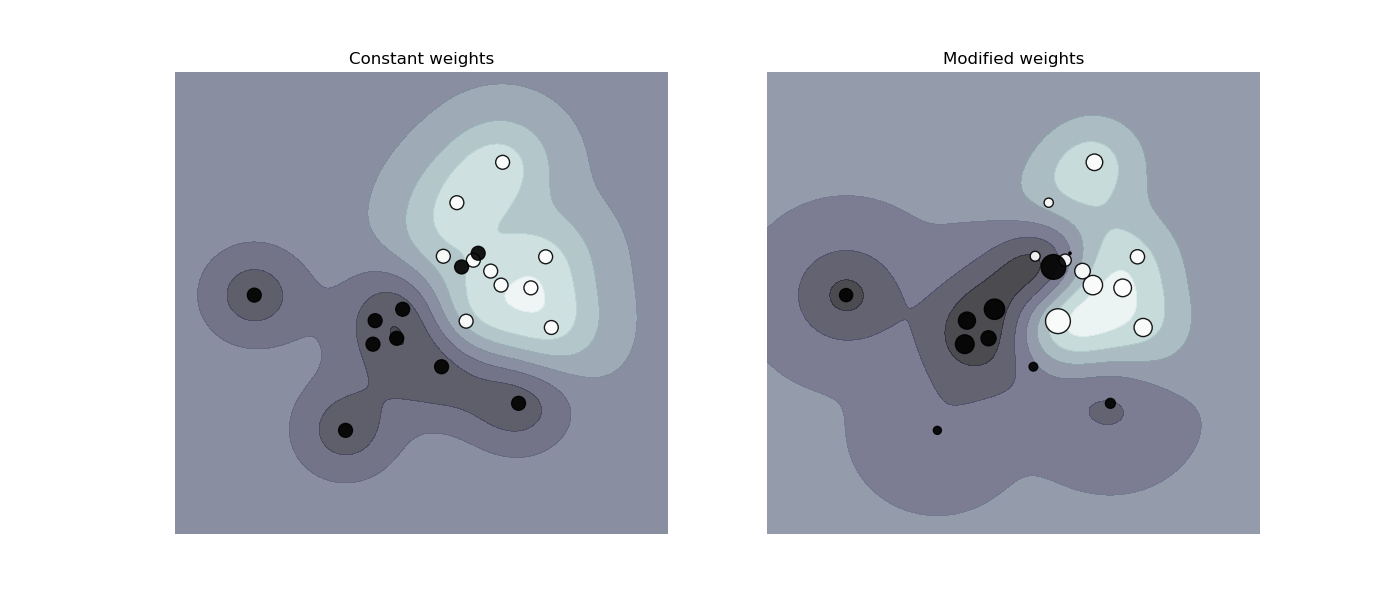
本案例繪制加權數據集的決策函數,其中點的大小與其權重成正比。
樣本加權會重新縮放C參數,這意味著分類器將更多的重點放在正確設置這些點上。 效果通常可能很微妙。為了強調此處的效果,我們特別加大了離群值的權重,使決策邊界的變形非常明顯。
輸出:
輸入:
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
def plot_decision_function(classifier, sample_weight, axis, title):
# 繪制決策邊界
xx, yy = np.meshgrid(np.linspace(-4, 5, 500), np.linspace(-4, 5, 500))
Z = classifier.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 繪制直線,點和最接近平面的向量
axis.contourf(xx, yy, Z, alpha=0.75, cmap=plt.cm.bone)
axis.scatter(X[:, 0], X[:, 1], c=y, s=100 * sample_weight, alpha=0.9,
cmap=plt.cm.bone, edgecolors='black')
axis.axis('off')
axis.set_title(title)
# 創建20個點
np.random.seed(0)
X = np.r_[np.random.randn(10, 2) + [1, 1], np.random.randn(10, 2)]
y = [1] * 10 + [-1] * 10
sample_weight_last_ten = abs(np.random.randn(len(X)))
sample_weight_constant = np.ones(len(X))
# 對離群值設置更大的權重
sample_weight_last_ten[15:] *= 5
sample_weight_last_ten[9] *= 15
# 供參考,首次擬合時我們不對樣本設置權重
# 擬合模型
clf_weights = svm.SVC(gamma=1)
clf_weights.fit(X, y, sample_weight=sample_weight_last_ten)
clf_no_weights = svm.SVC(gamma=1)
clf_no_weights.fit(X, y)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
plot_decision_function(clf_no_weights, sample_weight_constant, axes[0],
"Constant weights")
plot_decision_function(clf_weights, sample_weight_last_ten, axes[1],
"Modified weights")
plt.show()
腳本的總運行時間:(2分鐘59.930秒)