縮放SVC的正則化參數?
這個案例展示了當我們使用支持向量機做分類時,對正則化參數進行縮放時的效果。在進行支持向量機分類時,我們對以下等式的風險最小化很感興趣:
其中:
被用來設置正則項的數量 是樣本和模型參數的損失函數 是模型參數的懲罰函數
如果我們將損失函數視為每個樣本的個體誤差,那么隨著我們添加更多樣本,數據擬合項或每個樣本的誤差之和將增加。但是,懲罰項卻不會增加。
例如,當使用交叉驗證來設置C的正則化量時,在主要問題(未進行交叉驗證的全部數據集)和交叉驗證過程中較小的問題(使用交叉驗證分割后較小的數據集)之間將存在不同數量的樣本。
由于損失函數取決于樣本量,后者將影響C的選定值。現在出現的問題是,如何最佳地調整C以考慮不同數量的訓練樣本?
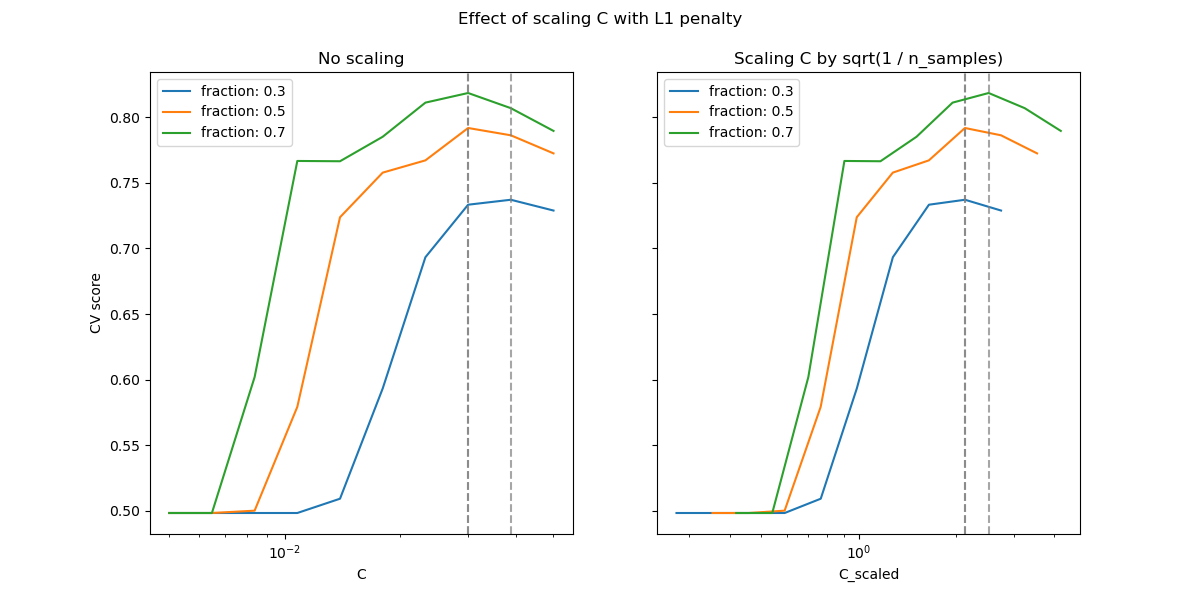
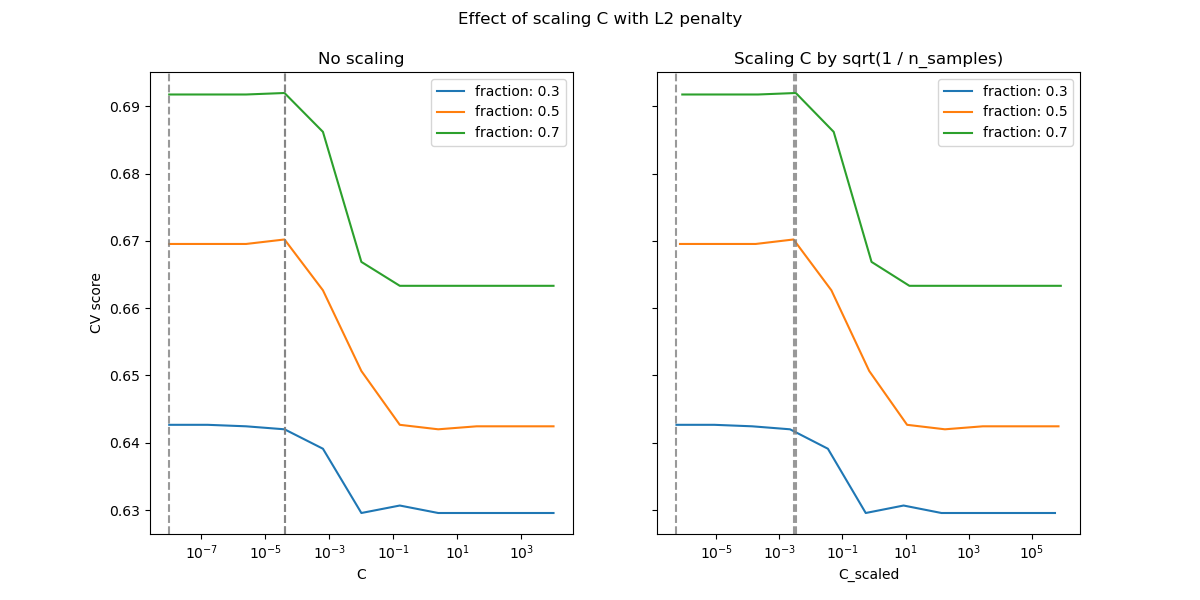
下圖用于說明在使用l1罰分和l2罰分的情況下,縮放C以補償樣本數量變化的效果。
L1懲罰項的情況
在l1的情況下,理論認為由于l1的偏差,預測一致性(即,在給定的假設下,估算器能夠學會預測并建立出一個知道數據真實分布的模型)是不可能的。但是,理論也確實認為,可以通過縮放來在找到正確的非零參數集及其符號方面實現模型一致性。
L2懲罰項的情況
理論認為,為了實現預測的一致性,懲罰參數應隨著樣本數量的增長而保持恒定。
模擬
針對生成的數據集的幾個不同部分,本案例在下面兩張圖繪制了的值(X軸)及交叉驗證分數(y軸)。
如第一個圖所示,在L1的情況下,當我們依照樣本量對進行縮放時,交叉驗證錯誤和測試錯誤有極高的關聯性。
在L2的情況下,當不對進行縮放時結果是最好的。
注意:
兩個圖像使用了不同的數據集。這樣做的理由是:L1懲罰項實際上在稀疏矩陣上效果更好,而L2更適合于不稀疏的矩陣。
輸入:
# 作者: Andreas Mueller <amueller@ais.uni-bonn.de>
# Jaques Grobler <jaques.grobler@inria.fr>
# 執照: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import LinearSVC
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import GridSearchCV
from sklearn.utils import check_random_state
from sklearn import datasets
rnd = check_random_state(1)
# 設置數據集
n_samples = 100
n_features = 300
# L1情況下使用的數據集(僅有5個信息特征)
X_1, y_1 = datasets.make_classification(n_samples=n_samples,
n_features=n_features, n_informative=5,
random_state=1)
# L2情況下使用的數據集:非稀疏,但有更少的特征
y_2 = np.sign(.5 - rnd.rand(n_samples))
X_2 = rnd.randn(n_samples, n_features // 5) + y_2[:, np.newaxis]
X_2 += 5 * rnd.randn(n_samples, n_features // 5)
clf_sets = [(LinearSVC(penalty='l1', loss='squared_hinge', dual=False,
tol=1e-3),
np.logspace(-2.3, -1.3, 10), X_1, y_1),
(LinearSVC(penalty='l2', loss='squared_hinge', dual=True),
np.logspace(-4.5, -2, 10), X_2, y_2)]
colors = ['navy', 'cyan', 'darkorange']
lw = 2
for clf, cs, X, y in clf_sets:
# 對每個回歸器設置圖像
fig, axes = plt.subplots(nrows=2, sharey=True, figsize=(9, 10))
for k, train_size in enumerate(np.linspace(0.3, 0.7, 3)[::-1]):
param_grid = dict(C=cs)
# 為了獲得良好的曲線,我們需要進行大量的迭代以減小方差
grid = GridSearchCV(clf, refit=False, param_grid=param_grid,
cv=ShuffleSplit(train_size=train_size,
test_size=.3,
n_splits=250, random_state=1))
grid.fit(X, y)
scores = grid.cv_results_['mean_test_score']
scales = [(1, 'No scaling'),
((n_samples * train_size), '1/n_samples'),
]
for ax, (scaler, name) in zip(axes, scales):
ax.set_xlabel('C')
ax.set_ylabel('CV Score')
grid_cs = cs * float(scaler) # scale the C's
ax.semilogx(grid_cs, scores, label="fraction %.2f" %
train_size, color=colors[k], lw=lw)
ax.set_title('scaling=%s, penalty=%s, loss=%s' %
(name, clf.penalty, clf.loss))
plt.legend(loc="best")
plt.show()
腳本的總運行時間:(0分鐘25.111秒)