sklearn.cluster.DBSCAN?
class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
從向量數組或距離矩陣執行DBSCAN聚類
DBSCAN-基于密度的帶噪聲應用空間聚類。發現高密度的核心樣本并從中膨脹團簇。對于包含類似密度的簇的數據來說是很好的。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| eps | float, default=0.5 輸入數據。兩個樣本之間的最大距離,其中一個被視為另一個樣本的鄰域內。這并不是一個簇內點之間距離的最大界限。。這是為數據集和距離函數適當選擇的最重要的dbscan參數。 |
| min_samples | int, default=5 一個點被視為核心點的鄰域內的樣本數(或總權重)。這包括要該點本身 |
| metric | string, or callable, default=’euclidean’ 在計算特征數組中實例之間的距離時使用的度量。如果度量是字符串或可調用的,則它必須是 sklearn.metrics.pairwise_distances為其度量參數所允許的選項之一。如果度量是“precomputed”,則假定X是距離矩陣,并且必須是平方的。X可能是Glossary,在這種情況下,只有“非零”元素可以被視為DBSCAN的鄰居。新版本0.17中:度量預計算以接受預先計算的稀疏矩陣。 |
| metric_params | dict, default=None 度量函數的附加關鍵字參數 新版本0.19中 |
| algorithm | {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’ NearestNeighbors模塊用于計算點態距離和尋找最近鄰的算法。有關詳細信息,請參閱NearestNeighbors模塊文檔。 |
| p | float, default=None 用于計算點間距離的Minkowski度量的冪。 |
| n_jobs | int, default=None 要運行的并行數。 None意味1, 除非在joblib.parallel_backend環境中。-1指使用所有處理器。有關詳細信息,請參Glossary。 |
| 屬性 | 說明 |
|---|---|
| core_sample_indices_ | ndarray of shape (n_core_samples,) 核心樣本的索引。 |
| components_ | ndarray of shape (n_core_samples, n_features) 通過訓練找到的每個核心樣本的副本 |
| labels_ | ndarray of shape (n_samples) 提供fit()的數據集中每個點的聚類標簽。有噪聲的樣本被賦予標簽-1。 |
另見:
在EPS的多個值上進行類似的聚類。我們的實現是為內存使用而優化的。
注
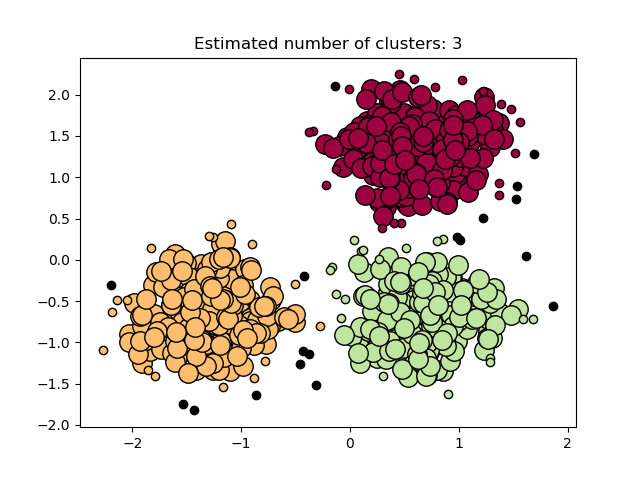
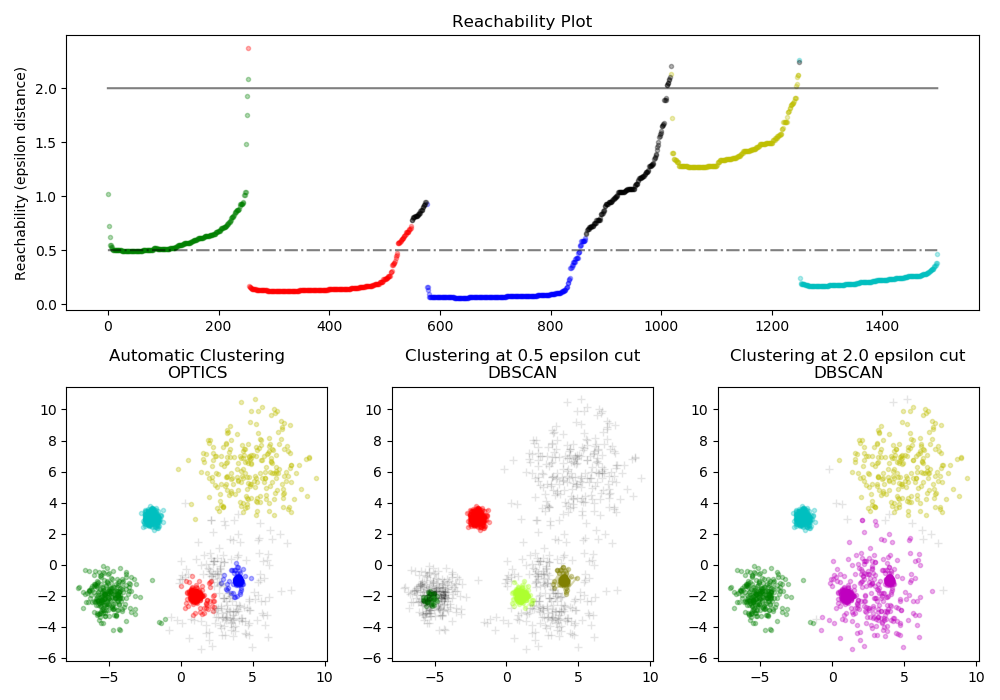
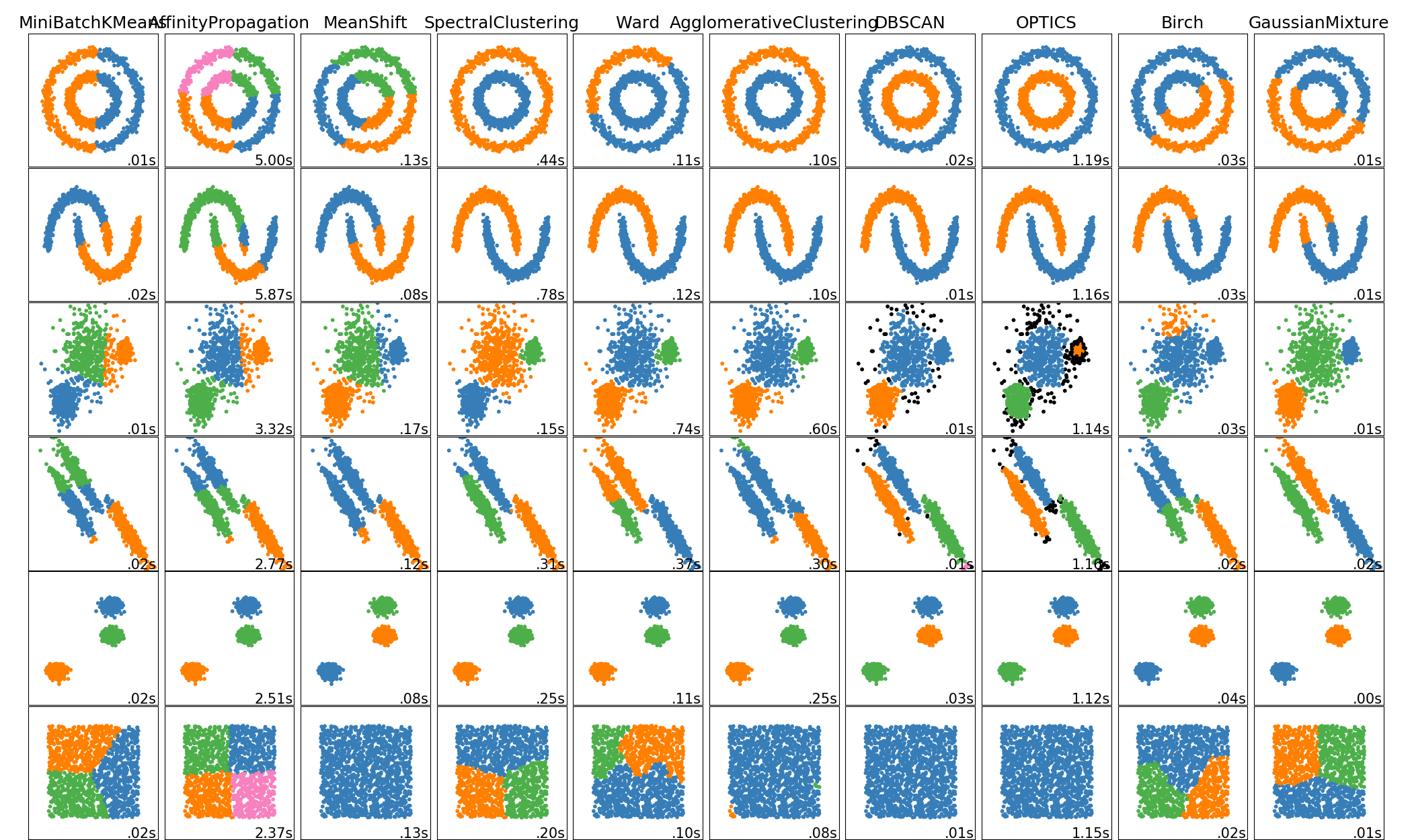
有關示例,請看examples/cluster/plot_dbscan.py.
此實現批量計算所有鄰域查詢,這會將內存復雜度增加到O(n.d),其中d是鄰居的平均數量,而原始DBSCAN的內存復雜度為O(n)。根據algorithm的不同,在查詢這些最近的鄰域時,它可能會吸引更高的內存復雜度。
避免查詢復雜性的一種方法是使用 NearestNeighbors.radius_neighbors_graph并設置 mode='distance',預先計算塊中的稀疏鄰域,然后在這里使用 metric='precomputed' 。
另一種減少內存和計算時間的方法是刪除(接近)重復點,并且使用 sample_weight 代替。
參考
Ester, M., H. P. Kriegel, J. Sander, and X. Xu, “A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise”. In: Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, pp. 226-231. 1996
Schubert, E., Sander, J., Ester, M., Kriegel, H. P., & Xu, X. (2017). DBSCAN revisited, revisited: why and how you should (still) use DBSCAN. ACM Transactions on Database Systems (TODS), 42(3), 19.
示例
>>> from sklearn.cluster import DBSCAN
>>> import numpy as np
>>> X = np.array([[1, 2], [2, 2], [2, 3],
... [8, 7], [8, 8], [25, 80]])
>>> clustering = DBSCAN(eps=3, min_samples=2).fit(X)
>>> clustering.labels_
array([ 0, 0, 0, 1, 1, -1])
>>> clustering
DBSCAN(eps=3, min_samples=2)
方法
| 方法 | 說明 |
|---|---|
fit(self, X[, y, sample_weight]) |
從特征或距離矩陣執行DBSCAN聚類 |
fit_predict(self, X[, y, sample_weight]) |
從特征或距離矩陣執行DBSCAN聚類,并返回聚類標簽。 |
get_params(self[, deep]) |
獲取此估計器的參數 |
set_params(self, **params) |
設置此估計器的參數 |
__init__(self, eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
初始化self。請參閱help(type(self))以獲得準確的說明。
fit(self, X, y=None, sample_weight=None)
從特征或距離矩陣執行DBSCAN聚類。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features), or (n_samples, n_samples) 要聚類的訓練實例,或實例之間的距離, 如果 metric='precomputed'。如果提供稀疏矩陣,則將其轉換為稀疏csr_matrix。 |
| sample_weight | array-like of shape (n_samples,), default=None 每個樣本的權重,例如一個權重至少為 min_samples的樣本本身就是一個核心樣本;一個負權重的樣本可能會抑制它的EPS-鄰居成為核心。注意,權重是絕對的,默認為1。 |
| y | Ignored 未使用,在此按約定呈現為API一致性。 |
| 返回值 | 說明 |
|---|---|
| self | - |
fit_predict(self, X, y=None, sample_weight=None)
從特征或距離矩陣執行DBSCAN聚類,并返回聚類標簽。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features), or (n_samples, n_samples) 要聚類的訓練實例,或實例之間的距離, 如果 metric='precomputed'。如果提供稀疏矩陣,則將其轉換為稀疏csr_matrix。 |
| sample_weight | array-like of shape (n_samples,), default=None 每個樣本的權重,例如一個權重至少為 min_samples的樣本本身就是一個核心樣本;一個負權重的樣本可能會抑制它的EPS-鄰居成為核心。注意,權重是絕對的,默認為1。 |
| y | Ignored 未使用,在此按約定呈現為API一致性。 |
| 返回值 | 說明 |
|---|---|
| labels | ndarray, shape (n_samples,) 聚類標簽。有噪音的樣本被標為-1。 |
get_params(self, deep=True)
獲取此估計器的參數
| 表格 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估計器的參數和所包含的作為估計量的子對象。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 映射到其值的參數名稱 |
set_params(self, **params)
設置此估計器的參數
該方法適用于簡單估計器以及嵌套對象(例如pipelines)。后者具有表單的 <component>__<parameter>參數,這樣就可以更新嵌套對象的每個組件。
| 表格 | 說明 |
|---|---|
| **params | dict 估計器參數 |
| 返回值 | 說明書 |
|---|---|
| self | object 估計器實例 |