sklearn.cluster.AffinityPropagation?
class sklearn.cluster.AffinityPropagation(*, damping=0.5, max_iter=200, convergence_iter=15, copy=True, preference=None, affinity='euclidean', verbose=False, random_state='warn')
執行數據的親和傳播聚類。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| damping | float, default=0.5 阻尼系數(0.5到1之間)是當前值相對于傳入值(加權1-阻尼)保持的程度。這是為了在更新這些值(消息)時避免數值振蕩。 |
| max_iter | int, default=200 最大迭代次數 |
| convergence_iter | int, default=15 停止收斂時, 估計的聚類數目不再變化時的迭代次數 |
| copy | bool, default=True 做一個輸入數據的副本 |
| preference | array-like of shape (n_samples,) or float, default=None 每個點的偏好值越大,就越有可能被選擇作為樣本。樣本數,聚類的數目, 受輸入偏好值的影響。如果偏好不是作為參數傳遞,它們將被設置為輸入相似性的中位數。 |
| affinity | {‘euclidean’, ‘precomputed’}, default=’euclidean’ 用哪種親和。目前支持‘precomputed’和 euclidean。‘euclidean’使用點之間的負平方歐幾里德距離。 |
| verbose | bool, default=False 是否冗長 |
| random_state | int or np.random.RandomStateInstance, default: 0 偽隨機數生成器控制起動狀態。對跨函數調用的可重復結果使用int。See the Glossary 新版本0.23:此參數以前被硬編碼為0。 |
| 屬性 | 說明 |
|---|---|
| cluster_centers_indices_ | ndarray of shape (n_clusters,) 聚類中心的索引 |
| cluster_centers_ | ndarray of shape (n_clusters, n_features) 聚類中心(if affinity != precomputed) |
| labels_ | ndarray of shape (n_samples,) 每個點的標簽 |
| affinity_matrix_ | ndarray of shape (n_samples, n_samples) 儲存在 fit中使用的親和矩陣。 |
| n_iter_ | int 用于收斂的迭代次數 |
注:
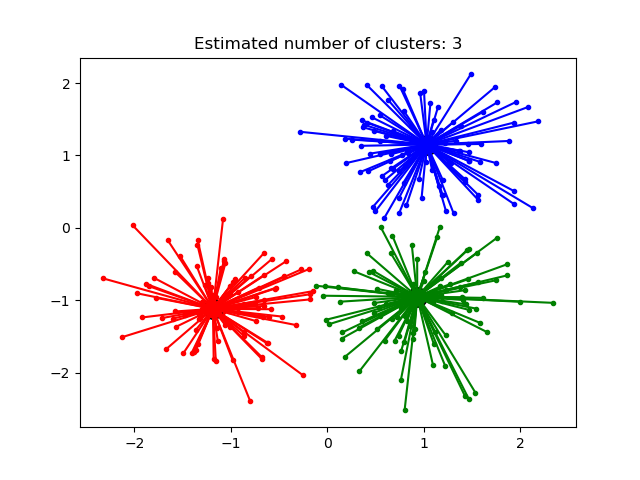
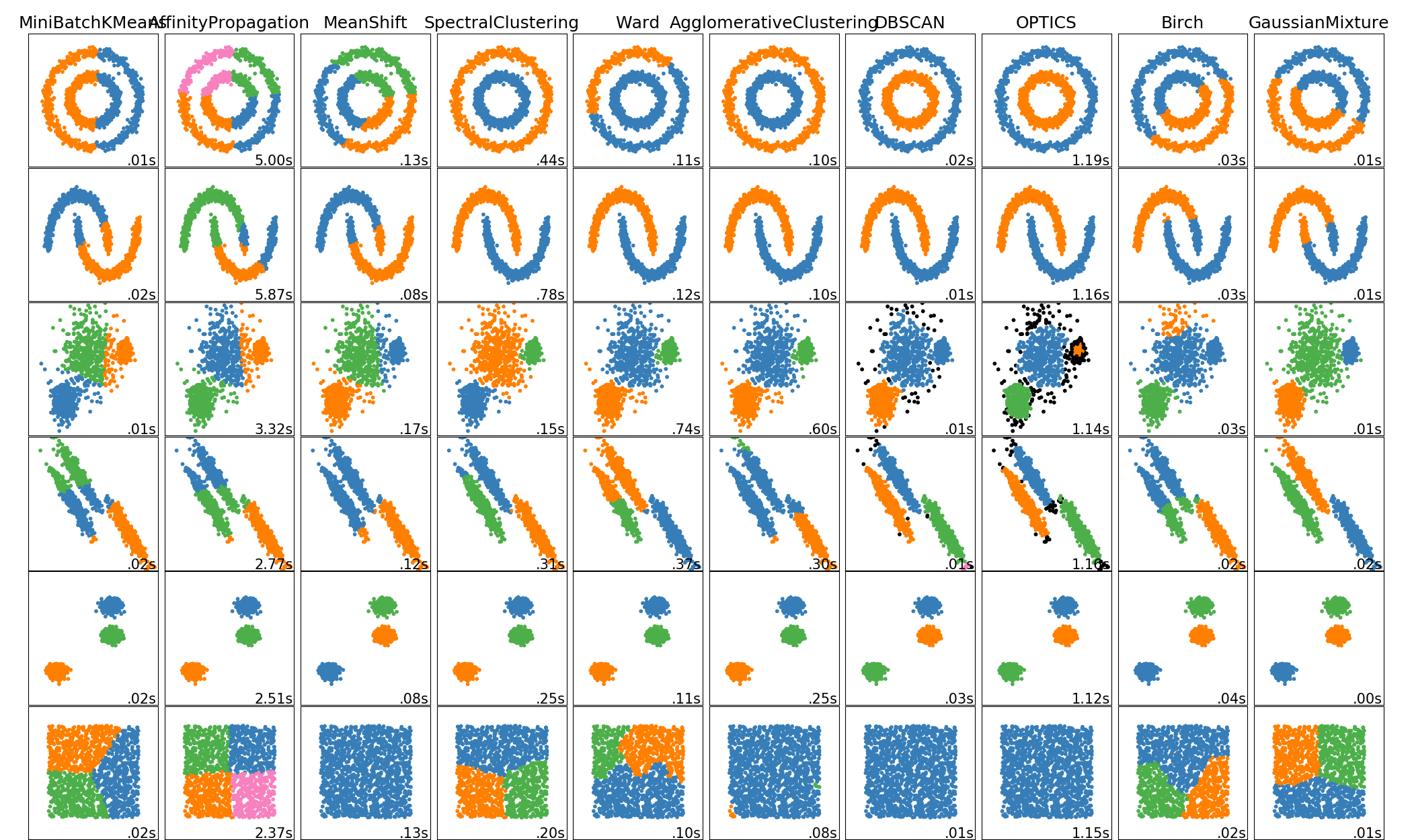
一個例子: examples/cluster/plot_affinity_propagation.py.
親和傳播的算法復雜度在點數上是二次型的。
當fit不收斂時 cluster_centers_ 變成一個空數組,所有訓練樣本都被標記為-1。此外,預測將標記每個樣本為-1。
當所有訓練樣本具有相同的相似性和相同的偏好時,聚類中心和標簽的分配取決于偏好。如果偏好小于相似點,則fit將導致單個聚類中心,并為每個樣本標記0。否則,每個訓練樣本都會成為自己的聚類中心,并被分配一個唯一的標簽。
參考
Brendan J. Frey and Delbert Dueck, “Clustering by Passing Messages Between Data Points”, Science Feb. 2007
示例
>>> from sklearn.cluster import AffinityPropagation
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [4, 2], [4, 4], [4, 0]])
>>> clustering = AffinityPropagation(random_state=5).fit(X)
>>> clustering
AffinityPropagation(random_state=5)
>>> clustering.labels_
array([0, 0, 0, 1, 1, 1])
>>> clustering.predict([[0, 0], [4, 4]])
array([0, 1])
>>> clustering.cluster_centers_
array([[1, 2],
[4, 2]])
方法
| 方法 | 說明 |
|---|---|
fit(self, X[, y]) |
根據特征或親和矩陣對聚類進行擬合。 |
fit_predict(self, X[, y]) |
根據特征或親和矩陣對聚類進行擬合,并返回聚類標簽。 |
get_params(self[, deep]) |
獲取此估計器的參數 |
predict(self, X) |
預測X中每個樣本所屬的最接近的聚類 |
set_params(self, **params) |
設置此估計器的參數 |
__init__(self, *, damping=0.5, max_iter=200, convergence_iter=15, copy=True, preference=None, affinity='euclidean', verbose=False, random_state='warn')
初始化self。請參閱help(type(self))以獲得準確的說明。
fit(self, X, y=None)
根據特征或親和矩陣進行聚類。
| 參數 | 說明 |
|---|---|
| X | array-like or sparse matrix, shape (n_samples, n_features), or array-like, shape (n_samples, n_samples) 對實例進行聚類訓練,如果 affinity='precomputed',訓練實例之間的相似性/親和關系。如果提供的是一個稀疏矩陣,將會收斂成csr_matrix。 |
| y | Ignored 未使用,在此按約定呈現為API一致性。 |
| 返回值 | 說明 |
|---|---|
| self | - |
fit_predict(self, X, y=None)
根據特征或親和矩陣對聚類進行擬合,并返回聚類標簽。
| 參數 | 說明 |
|---|---|
| X | array-like or sparse matrix, shape (n_samples, n_features), or array-like, shape (n_samples, n_samples) 對實例進行聚類訓練,如果 affinity='precomputed',訓練實例之間的相似性/親和關系。如果提供的是一個稀疏矩陣,將會收斂成csr_matrix。 |
| y | Ignored 未使用,在此按約定呈現為API一致性。 |
| 返回值 | 說明 |
|---|---|
| labels | ndarray, shape (n_samples,) 聚類標簽 |
get_params(self, deep=True)
獲取此估計器的參數
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估計器的參數和所包含的作為估計器的子對象。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 映射到其值的參數名稱 |
predict(self, X)
預測X中每個樣本所屬的最接近的聚類
| 參數 | 列表 |
|---|---|
| X | array-like or sparse matrix, shape (n_samples, n_features) 要預測的新數據。如果提供稀疏矩陣,則將其轉換為稀疏 csr_matrix。 |
| 返回值 | 說明 |
|---|---|
| labels | ndarray, shape (n_samples,) 聚類標簽 |
set_params(self, **params)
設置此估計器的參數
該方法適用于簡單估計器以及嵌套對象(例如pipelines)。后者具有表單的 <component>__<parameter>參數,這樣就可以更新嵌套對象的每個組件。
| 表格 | 說明 |
|---|---|
| **params | dict 估計器參數 |
| 返回值 | 說明書 |
|---|---|
| self | object 估計器實例 |