sklearn.cluster.estimate_bandwidth?
sklearn.cluster.estimate_bandwidth(X, *, quantile=0.3, n_samples=None, random_state=0, n_jobs=None)
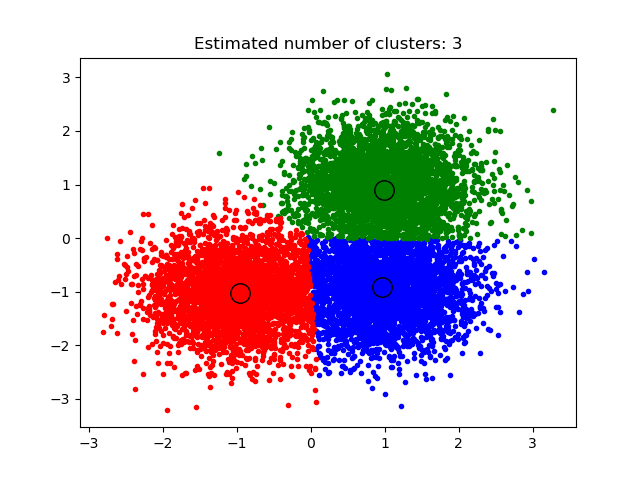
用Mean-Shift算法估計帶寬。
這個函數在所花費的時間至少是n_samples的二次方的。對于大型數據集,明智的做法是將該參數設置為一個小值。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 輸入點 |
| quantile | float, default=0.3 應介于[0,1]之間, 0.5意味著使用所有成對距離的中位數。 |
| n_samples | int, default=None 要使用的樣本數。如果沒有提供,則使用所有樣本。 |
| random_state | int, RandomState instance, default=None 用于從輸入點隨機選擇樣本的生成器用于帶寬估計。使用整數使隨機性確定性。見Glossary。 |
| n_jobs | int, default=None 要為鄰居搜索的并行作業數。 None意味1, 除非在joblib.parallel_backend環境中。-1指使用所有處理器。有關詳細信息,請參Glossary。 |
| 返回值 | 說明 |
|---|---|
| bandwidth | float 帶寬參數 |