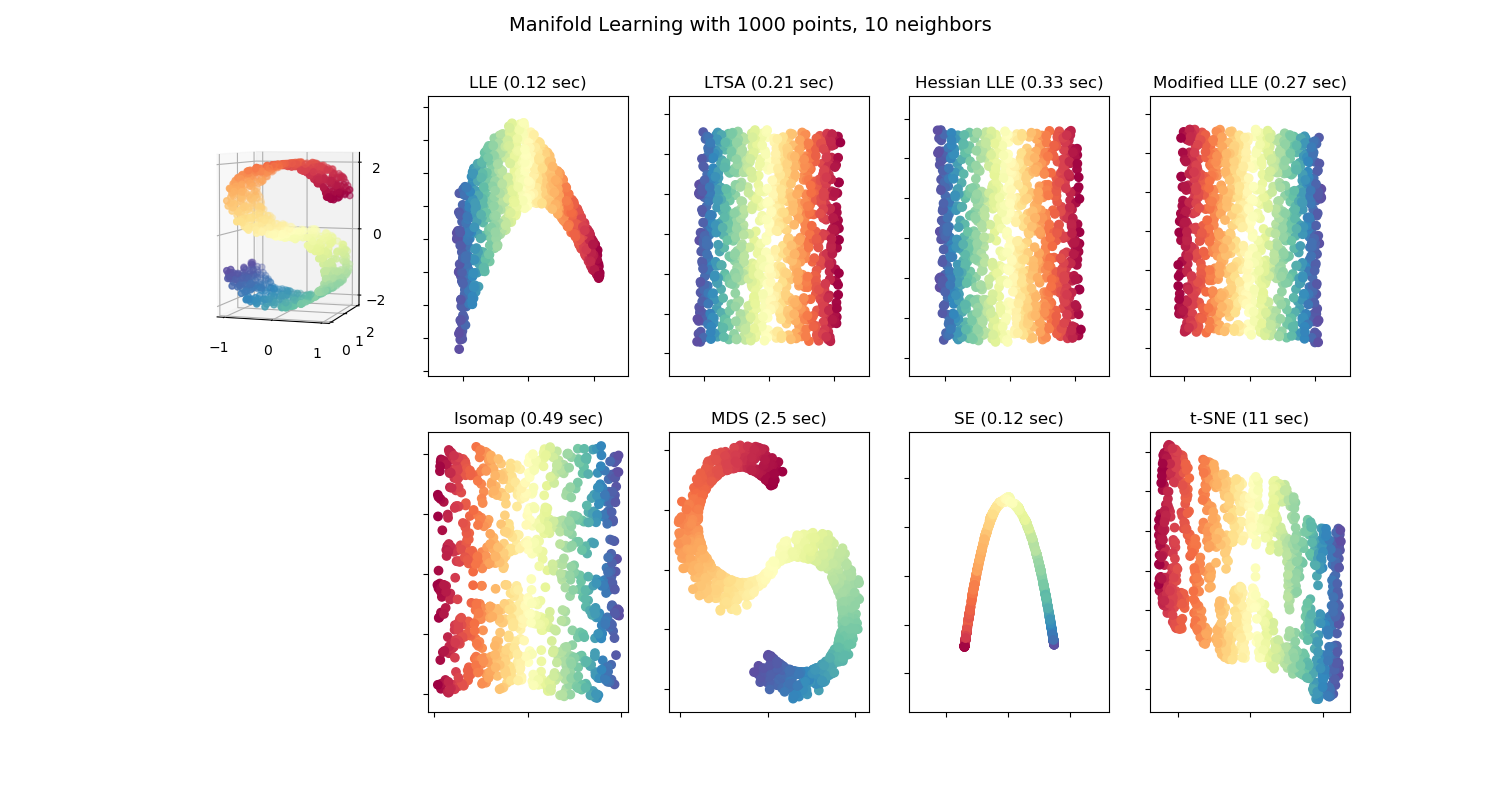
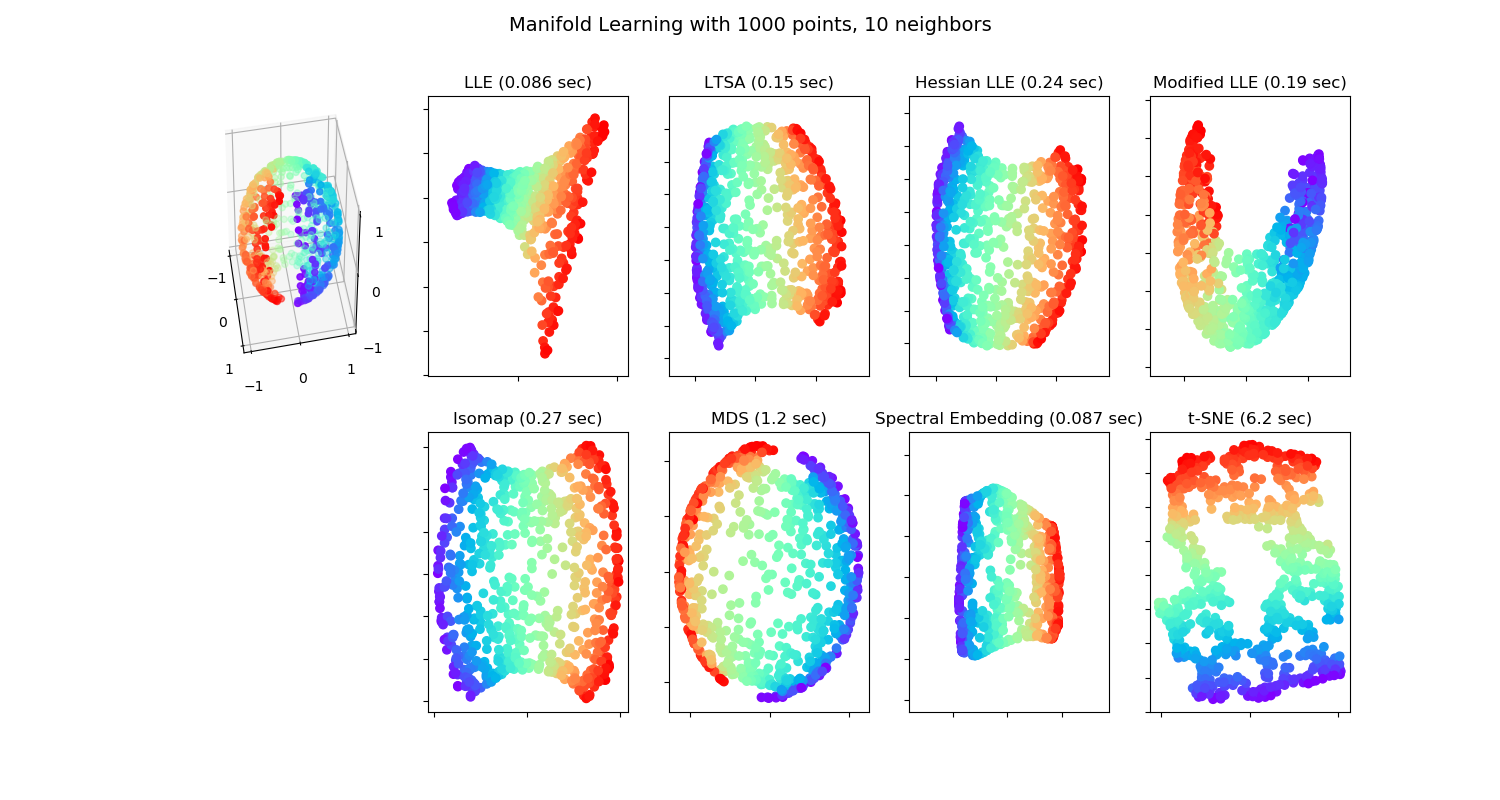
sklearn.manifold.SpectralEmbedding?
class sklearn.manifold.SpectralEmbedding(n_components=2, *, affinity='nearest_neighbors', gamma=None, random_state=None, eigen_solver=None, n_neighbors=None, n_jobs=None)
[源碼]
頻譜嵌入用于非線性降維。
形成指定函數給定的親和矩陣,并將光譜分解應用于相應的圖拉普拉斯圖。對于每個數據點,通過特征向量的值來給出結果轉換。
注意:拉普拉斯特征圖是此處實現的實際算法。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| n_components | integer, default: 2 降維到的維數 |
| affinity | string or callable, default How to construct the affinity matrix. - 'nearest_neighbors':通過計算最近鄰圖構造親和矩陣。 - ‘rbf’ :通過計算徑向基函數(RBF)內核來構造親和矩陣。 - 'precompulated':將X解釋為預計算的親和矩陣。 - 'precomputed_nearest_neighbors':將X解釋為預計算最近鄰的稀疏圖,并通過選擇 n_neighbors最近鄰來構造親和力矩陣。- callable:使用傳入函數作為關聯函數函數接受數據矩陣(n_samples, n_features)和返回關聯矩陣(n_samples, n_samples)。 |
| gamma | float, optional, default rbf核的核系數。 |
| random_state | int, RandomState instance, default=None 當 solver=='amg' 時,確定用于lobpcg特征向量初始化的隨機數生成器。在多個函數調用之間傳遞int以獲得可重復的結果。請參閱:term: Glossary <random_state>. |
| eigen_solver | {None, ‘arpack’, ‘lobpcg’, or ‘amg’} 采用特征值分解策略。AMG要求安裝pyamg。在非常大的,稀疏的問題上它可以更快。 |
| n_neighbors | int, default 最近鄰圖構建的最近鄰數。 |
| n_jobs | int or None, optional (default=None) 用于進行計算的CPU數量。 如果使用多個初始化( n_init),則算法的每次運行都是并行計算的。None除非在joblib.parallel_backend環境中,否則表示1 。 undefined表示使用所有處理器。有關更多詳細信息,請參見詞匯表。 |
| 屬性 | 說明 |
|---|---|
| embedding_ | array, shape = (n_samples, n_components) 訓練矩陣的頻譜嵌入。 |
| affinity_matrix_ | array, shape = (n_samples, n_samples) 由樣本或預計算的親和矩陣。 |
| n_neighbors_ | int 有效使用的最近鄰的數量。 |
參考文獻
1 A Tutorial on Spectral Clustering, 2007 Ulrike von Luxburg http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.165.9323
2 On Spectral Clustering: Analysis and an algorithm, 2001 Andrew Y. Ng, Michael I. Jordan, Yair Weiss http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.19.8100
3 Normalized cuts and image segmentation, 2000 Jianbo Shi, Jitendra Malik http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.160.2324
實例
>>> from sklearn.datasets import load_digits
>>> from sklearn.manifold import SpectralEmbedding
>>> X, _ = load_digits(return_X_y=True)
>>> X.shape
(1797, 64)
>>> embedding = SpectralEmbedding(n_components=2)
>>> X_transformed = embedding.fit_transform(X[:100])
>>> X_transformed.shape
(100, 2)
| 方法 | 說明 |
|---|---|
fit(X[, y]) |
根據X中的數據擬合模型。 |
fit_transform(X[, y]) |
根據X中的數據擬合模型并轉換X。 |
get_params([deep]) |
獲取此估計量的參數。 |
set_params(**params) |
設置此估算量的參數。 |
__init__(n_components=2, *, affinity='nearest_neighbors', gamma=None, random_state=None, eigen_solver=None, n_neighbors=None, n_jobs=None)
[源碼]
初始化self, 請參閱help(type(self))以獲得準確的說明。
fit(X, y=None)
[源碼]
根據X中的數據擬合模型。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix}, shape (n_samples, n_features) 訓練向量,其中n_samples是樣本數,n_features是特征數。 如果affinity(親和度)是“預先計算的” X : {array-like, sparse matrix},shape (n_samples, n_samples),則將X解釋為根據樣本計算得出的預先計算的鄰接圖。 |
| 返回值 | 說明 |
|---|---|
| self | object 返回實例本身。 |
fit_transform(X, y=None)
[源碼]
根據X中的數據擬合模型并轉換X。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix}, shape (n_samples, n_features) 訓練向量,其中n_samples是樣本數,n_features是特征數。 如果affinity(親和度)是“預先計算的” X : {array-like, sparse matrix},shape (n_samples, n_samples),則將X解釋為根據樣本計算得出的預先計算的鄰接圖。 |
| 返回值 | 說明 |
|---|---|
| X_new | array-like, shape (n_samples, n_components) |
get_params(deep=True)
[源碼]
獲取此估計量的參數
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算量和作為估算量的包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 映射到其值的參數名。 |
set_params(**params)
[源碼]
設置此估算量的參數。
該方法適用于簡單估計量以及嵌套對象(例如pipelines)。后者具有形式的參數。<component>__<parameter>以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估算量參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估算量實例。 |