datasets.fetch_species_distributions?
sklearn.datasets.fetch_species_distributions(*, data_home=None, download_if_missing=True)
Phillips等人的物種分布數據集加載程序。 等 (2006年)
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| data_home | optional, default: None 為數據集指定另一個下載和緩存文件夾。 默認情況下,所有scikit-learn數據都存儲在“?/ scikit_learn_data”子文件夾中。 |
| download_if_missing | optional, True by default 如果為False,則在數據不在本地可用時引發IOError,而不是嘗試從源站點下載數據。 |
| 返回值 | 說明 |
|---|---|
| data | Bunch類字典對象,具有以下屬性。 - coverages:array, shape = [14, 1592, 1212] 這些代表在地圖網格的每個點測量的14個特征。 下面討論了網格的緯度/經度值。 缺少的數據由值-9999表示。 - trainrecord array, shape = (1624,) 數據的訓練點。 每個點都有三個字段: train ['species']是物種名稱 train ['dd long']是經度,以度為單位 train [‘dd lat’]是緯度,以度為單位 - testrecord array, shape = (620,) 數據的測試點。其格式與訓練數據相同。 - Nx, Ny:integers 網格中的經度(x)和緯度(y)數 - x_left_lower_corner, y_left_lower_cornerfloats 左下角的(x,y)位置,以度為單位 - grid_sizefloat 網格點之間的間距,以度為單位 |
注
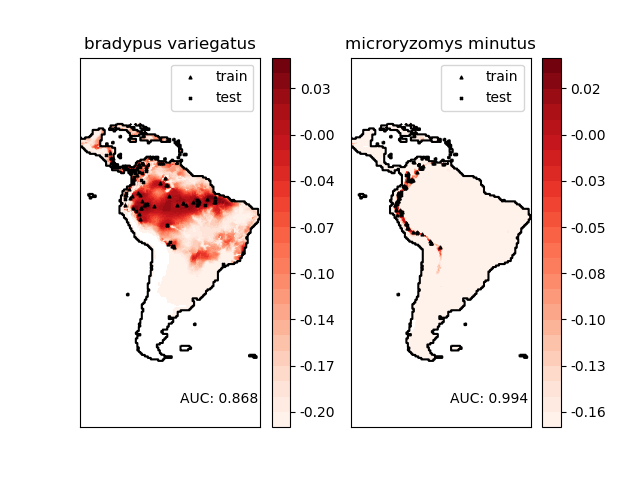
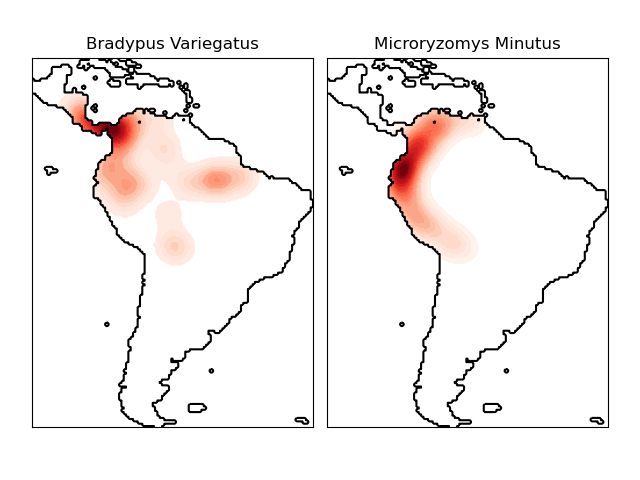
該數據集表示物種的地理分布。該數據集是由Phillips等提供(2006)。
這兩個物種是:
“Bradypus variegatus” ,褐喉樹懶。
“Microryzomys minutus”,也被稱為森林小老鼠大米,嚙齒動物,生活在秘魯,哥倫比亞,厄瓜多爾,秘魯和委內瑞拉。
有關將此數據集與scikit-learn一起使用的示例,請參見examples/applications/plot_species_distribution_modeling.py。
參考資料
“Maximum entropy modeling of species geographic distributions” S. J. Phillips, R. P. Anderson, R. E. Schapire - Ecological Modelling, 190:231-259, 2006。