物種分布的核密度估計?
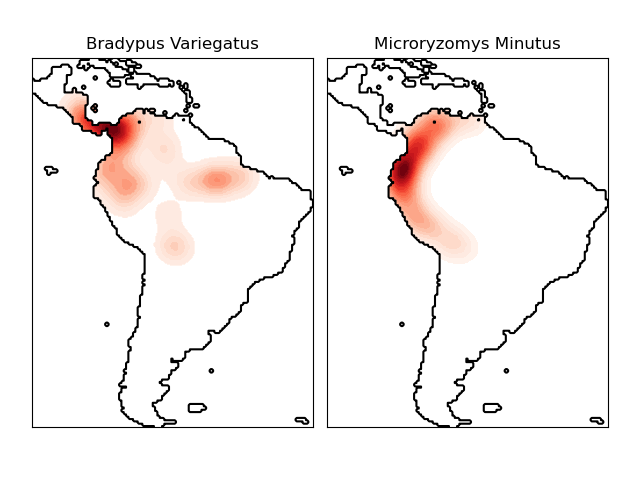
在這里展示的是一個基于最近鄰查詢的案例,該案例使用基于Haversine距離度量(即,經度/緯度上的點的距離)構建的球樹(Ball Tree),對地理空間數據進行最近鄰查詢(尤其是內核密度估計)。數據集由Phillips等人在2006年發表的論文中提供。 如果可以,該案例將使用basemap庫繪制南美的海岸線和國家邊界。
本案例不對數據進行任何學習(有關基于此數據集中屬性的分類示例,請參閱物種分布建模)。 它僅顯示了地理空間坐標中觀察到的數據點的核密度估計。
這兩種生物是:
“Bradypus variegatus”,一種棕喉樹懶
“ Microryzomys minutus”,也稱為森林小稻鼠,一種生活在秘魯,哥倫比亞,厄瓜多爾,秘魯和委內瑞拉的嚙齒動物。
引用
“Maximum entropy modeling of species geographic distributions” S. J. Phillips, R. P. Anderson, R. E. Schapire - Ecological Modelling, 190:231-259, 2006.
輸出:
- computing KDE in spherical coordinates
- plot coastlines from coverage
- computing KDE in spherical coordinates
- plot coastlines from coverage
輸入:
# 作者: Jake Vanderplas <jakevdp@cs.washington.edu>
#
# 執照: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_species_distributions
from sklearn.neighbors import KernelDensity
# 如果basemap庫可用,我們可以使用它:
# 否則,我們之后在看看如何處理
try:
from mpl_toolkits.basemap import Basemap
basemap = True
except ImportError:
basemap = False
def construct_grids(batch):
"""從批處理對象構造地圖網格
參數
----------
batch : 批處理對象
功能 :func:`fetch_species_distributions`返回的對象
輸出
-------
(xgrid, ygrid) : 1維數組
對應于batch.coverages中的值的網格
"""
# 角單元的x,y坐標
xmin = batch.x_left_lower_corner + batch.grid_size
xmax = xmin + (batch.Nx * batch.grid_size)
ymin = batch.y_left_lower_corner + batch.grid_size
ymax = ymin + (batch.Ny * batch.grid_size)
# 網格單元的x坐標
xgrid = np.arange(xmin, xmax, batch.grid_size)
# 網格單元的y坐標
ygrid = np.arange(ymin, ymax, batch.grid_size)
return (xgrid, ygrid)
# 獲取物種ID和位置的矩陣/數組
data = fetch_species_distributions()
species_names = ['Bradypus Variegatus', 'Microryzomys Minutus']
Xtrain = np.vstack([data['train']['dd lat'],
data['train']['dd long']]).T
ytrain = np.array([d.decode('ascii').startswith('micro')
for d in data['train']['species']], dtype='int')
Xtrain *= np.pi / 180. # Convert lat/long to radians
# 設置等高線圖的數據網格
xgrid, ygrid = construct_grids(data)
X, Y = np.meshgrid(xgrid[::5], ygrid[::5][::-1])
land_reference = data.coverages[6][::5, ::5]
land_mask = (land_reference > -9999).ravel()
xy = np.vstack([Y.ravel(), X.ravel()]).T
xy = xy[land_mask]
xy *= np.pi / 180.
# 繪制南美洲的地圖,每種物種的分布
fig = plt.figure()
fig.subplots_adjust(left=0.05, right=0.95, wspace=0.05)
for i in range(2):
plt.subplot(1, 2, i + 1)
# 構造分布的核密度估計
print(" - computing KDE in spherical coordinates")
kde = KernelDensity(bandwidth=0.04, metric='haversine',
kernel='gaussian', algorithm='ball_tree')
kde.fit(Xtrain[ytrain == i])
# 僅在陸地上評估:-9999表示海洋
Z = np.full(land_mask.shape[0], -9999, dtype='int')
Z[land_mask] = np.exp(kde.score_samples(xy))
Z = Z.reshape(X.shape)
# 繪制密度等高線
levels = np.linspace(0, Z.max(), 25)
plt.contourf(X, Y, Z, levels=levels, cmap=plt.cm.Reds)
if basemap:
print(" - plot coastlines using basemap")
m = Basemap(projection='cyl', llcrnrlat=Y.min(),
urcrnrlat=Y.max(), llcrnrlon=X.min(),
urcrnrlon=X.max(), resolution='c')
m.drawcoastlines()
m.drawcountries()
else:
print(" - plot coastlines from coverage")
plt.contour(X, Y, land_reference,
levels=[-9998], colors="k",
linestyles="solid")
plt.xticks([])
plt.yticks([])
plt.title(species_names[i])
plt.show()
腳本的總運行時間:(0分鐘7.247秒)