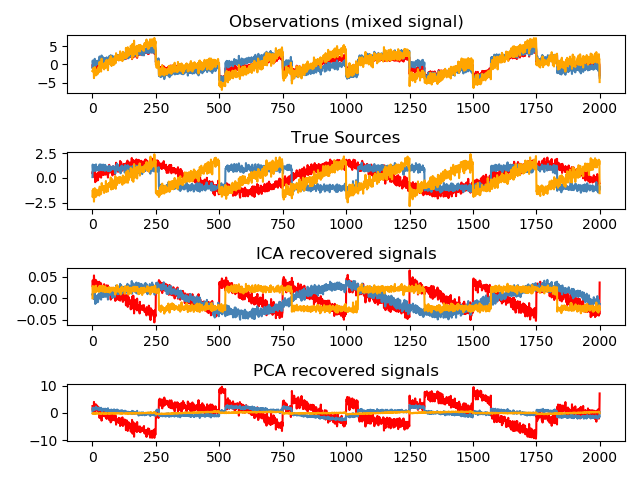
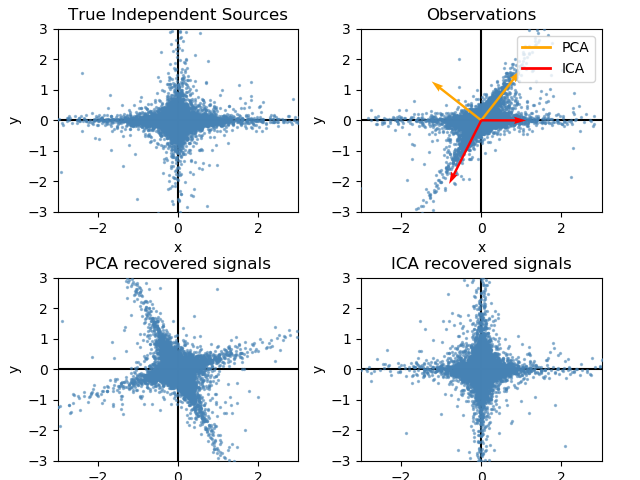
sklearn.decomposition.FastICA?
class sklearn.decomposition.FastICA(n_components=None, *, algorithm='parallel', whiten=True, fun='logcosh', fun_args=None, max_iter=200, tol=0.0001, w_init=None, random_state=None)
FastICA:獨立分量分析的快速算法。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| n_components | int, optional 要使用的樣本數量。如果沒有傳遞,則使用全部。 |
| algorithm | {‘parallel’, ‘deflation’} 應用平行或偏轉算法。 |
| whiten | boolean, optional 如果白化為假,則認為該數據已經被白化,并且不執行白化。 |
| fun | string or function, optional. Default: ‘logcosh’ 用來近似負熵的G函數的函數形式。可以是' logcosh ' ' exp '或' cube '您還可以提供自己的功能。它應該返回一個元組,其中包含函數的值及其在點中的導數。例子: def my_g (x): return x ** 3, (3 * x ** 2).mean(axis=-1) |
| fun_args | dictionary, optional 要發送到函數形式的參數。如果為空,如果fun= ' logcosh ', fun_args將取值{' alpha ': 1.0}。 |
| max_iter | int, optional fit期間的最大迭代次數。 |
| tol | float, optional 對每次迭代更新的容忍度。 |
| w_init | None of an (n_components, n_components) ndarray 混合矩陣用于初始化算法。 |
| random_state | int, RandomState instance, default=None 用于初始化未指定的w_init,使用正態分布。傳遞一個int,以便在多個函數調用中得到可重復的結果。詳見術語表。 |
| 屬性 | 說明 |
|---|---|
| components_ | 2D array, shape (n_components, n_features) 將線性算子應用于數據得到獨立的源。它等于解混矩陣當白化為假時,等于np。當白化為真時,點(unmixing_matrix, self。whitening_)。 |
| mixing_ | array, shape (n_features, n_components) components_的偽逆。它是將獨立的源映射到數據的線性操作符。 |
| mean_ | array, shape(n_features) 特征的平均值。只有當self時才設置。白化是正確的。 |
| n_iter_ | int 如果算法是“通縮”, n_iter是在所有組件上運行的最大迭代次數。否則它們就是收斂所需的迭代次數。 |
| whitening_ | array, shape (n_components, n_features) 只有在白化為“真”時才設置。這是將數據投影到第一個 n_components主成分上的預白化矩陣。 |
注意
Implementation based on A. Hyvarinen and E. Oja, Independent Component Analysis: Algorithms and Applications, Neural Networks, 13(4-5), 2000, pp. 411-430
示例
>>> from sklearn.datasets import load_digits
>>> from sklearn.decomposition import FastICA
>>> X, _ = load_digits(return_X_y=True)
>>> transformer = FastICA(n_components=7,
... random_state=0)
>>> X_transformed = transformer.fit_transform(X)
>>> X_transformed.shape
(1797, 7)
方法
| 方法 | 說明 |
|---|---|
fit(self, X[, y]) |
將模型擬合到X。 |
fit_transform(self, X[, y]) |
擬合模型并從X中恢復源。 |
get_params(self[, deep]) |
獲取這個估計器的參數。 |
inverse_transform(self, X[, copy]) |
設置這個估計器的參數。 |
set_params(self, **params) |
Set the parameters of this estimator. |
transform(self, X[, copy]) |
從X中恢復源(應用分離矩陣)。 |
__init__(self, n_components=None, *, algorithm='parallel', whiten=True, fun='logcosh', fun_args=None, max_iter=200, tol=0.0001, w_init=None, random_state=None)[source]
初始化self. See 請參閱help(type(self))以獲得準確的說明。
fit(self, X, y=None)
將模型擬合到X。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 訓練數據,其中n_samples為樣本數量,n_features為特征數量。 |
| y | Ignored |
| 返回值 |
|---|
| self |
fit_transform(self, X, y=None)
擬合模型并從X中恢復源。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 訓練數據,其中n_samples為樣本數量,n_features為特征數量。 |
| y | Ignored |
| 返回值 | 說明 |
|---|---|
| X_new | array-like, shape (n_samples, n_components) |
inverse_transform(self, X, copy=True)
將源轉換回混合數據(應用混合矩陣)。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 其中n_samples是樣本的數量,n_components是組件的數量。 |
| copy | bool (optional) 如果為False,傳遞給fit的數據將被覆蓋。默認值為True。 |
| 返回值 | 說明 |
|---|---|
| X_new | array-like, shape (n_samples, n_features) |
set_params(self, **params)
設置這個估計器的參數。
該方法適用于簡單估計器和嵌套對象(如管道)。后者具有形式為 <component>__<parameter> 的參數,這樣就可以更新嵌套對象的每個樣本。
| 參數 | 說明 |
|---|---|
| **params | dict 估計參數 |
| 返回值 | 說明 |
|---|---|
| self | object: 估計距離 |
transform(self, X, copy=True)
從X中恢復源(應用分離矩陣)。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 其中n_samples是樣本的數量,n_components是組件的數量。 |
| copy | bool (optional) 如果為False,傳遞給fit的數據將被覆蓋。默認值為True。 |