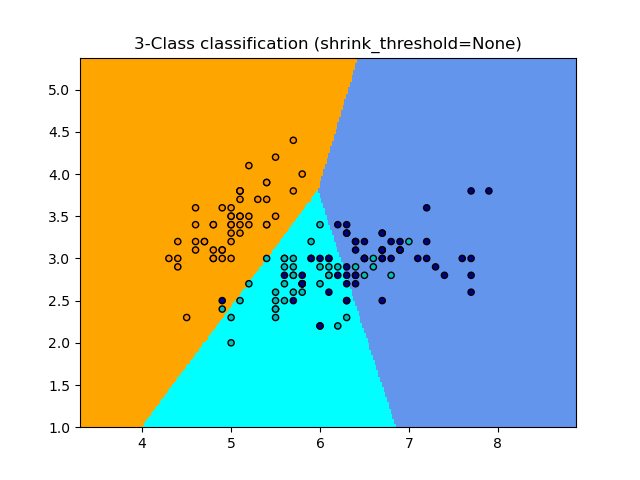
sklearn.neighbors.NearestCentroid?
class sklearn.neighbors.NearestCentroid(metric='euclidean', *, shrink_threshold=None)
[源碼]
最近的質心分類器。
每個類別均以其質心表示,測試樣本被分類為具有最接近質心的類別。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| metric | str or callable 計算要素陣列中實例之間的距離時使用的度量。 如果metric是字符串或可調用,則必須是metric參數的metrics.pairwise.pairwise_distances允許的選項之一。 對應于每個類別的樣本的質心是一個點,從該點可以使屬于該特定類別的所有樣本的距離之和(根據度量)最小化。 如果提供了“曼哈頓”度量標準,則此質心為中位數,對于所有其他度量標準,現在將質心設置為均值。 版本0.19中的更改:不建議使用metric ='precomputed',現在會引發錯誤 |
| shrink_threshold | float, default=None 縮小質心以刪除特征的閾值。 |
| 屬性 | 說明 |
|---|---|
| centroids_ | array-like of shape (n_classes, n_features) 每個類的質心。 |
| classes_ | array of shape (n_classes,) 唯一的類標簽。 |
另見:
sklearn.neighbors.KNeighborsClassifier
最近鄰分類器
聲明
當用于帶有tf-idf向量的文本分類時,此分類器也稱為Rocchio分類器
參考資料
Tibshirani, R., Hastie, T., Narasimhan, B., & Chu, G. (2002)。 通過基因表達的收縮質心診斷多種癌癥。 美國國家科學院院刊,99(10),6567-6572。 美國國家科學院
示例
>>> from sklearn.neighbors import NearestCentroid
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> y = np.array([1, 1, 1, 2, 2, 2])
>>> clf = NearestCentroid()
>>> clf.fit(X, y)
NearestCentroid()
>>> print(clf.predict([[-0.8, -1]]))
[1]
方法
| 方法 | 說明 |
|---|---|
fit(X, y) |
根據給定的訓練數據擬合NearestCentroid模型。 |
get_params([deep]) |
獲取此估計量的參數。 |
predict(X) |
對測試向量X進行分類 |
score(X, y[, sample_weight]) |
返回給定測試數據和標簽上的平均準確度。 |
set_params(**params) |
設置此估算器的參數。 |
__init__(metric='euclidean', *, shrink_threshold=None)
[源碼]
初始化, 請參閱help(type())以獲得準確的說明
fit(X, y)
[源碼]
根據給定的訓練數據擬合NearestCentroid模型
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 訓練向量,其中n_samples是樣本數,n_features是特征數。 注意,質心收縮不能與稀疏矩陣一起使用。 |
| y | array-like of shape (n_samples,) 目標值(整數) |
get_params(deep=True)
[源碼]
獲取此估計量的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和作為估算器的所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
predict(X)
[源碼]
對測試向量X進行分類。
返回X中每個樣本的預測類C。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) |
| 返回值 | 說明 |
|---|---|
| C | ndarray of shape (n_samples,) |
聲明
如果度量構造函數參數是“預先計算的”,則將X假定為要預測的數據與self.centroids_之間的距離矩陣。
score(X, y, sample_weight=None)
[源碼]
返回給定測試數據和標簽上的平均準確度。
在多標簽分類中,這是子集準確性,這是一個嚴格的指標,因為您需要為每個樣本正確預測每個標簽集
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 測試樣本 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真實標簽。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重 |
| 返回值 | 說明 |
|---|---|
| score | float self.predict(X) wrt. y.的平均準確度 |
set_params(**params)
[源碼]
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。 后者的參數格式為
| 參數 | 說明 |
|---|---|
| **params | dict 估算器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估算器實例 |