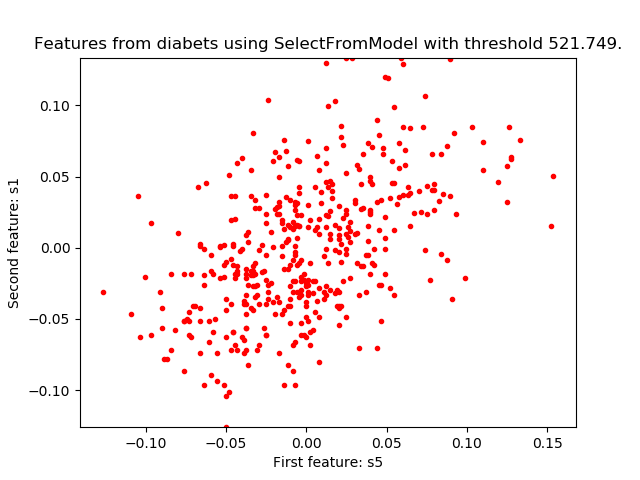
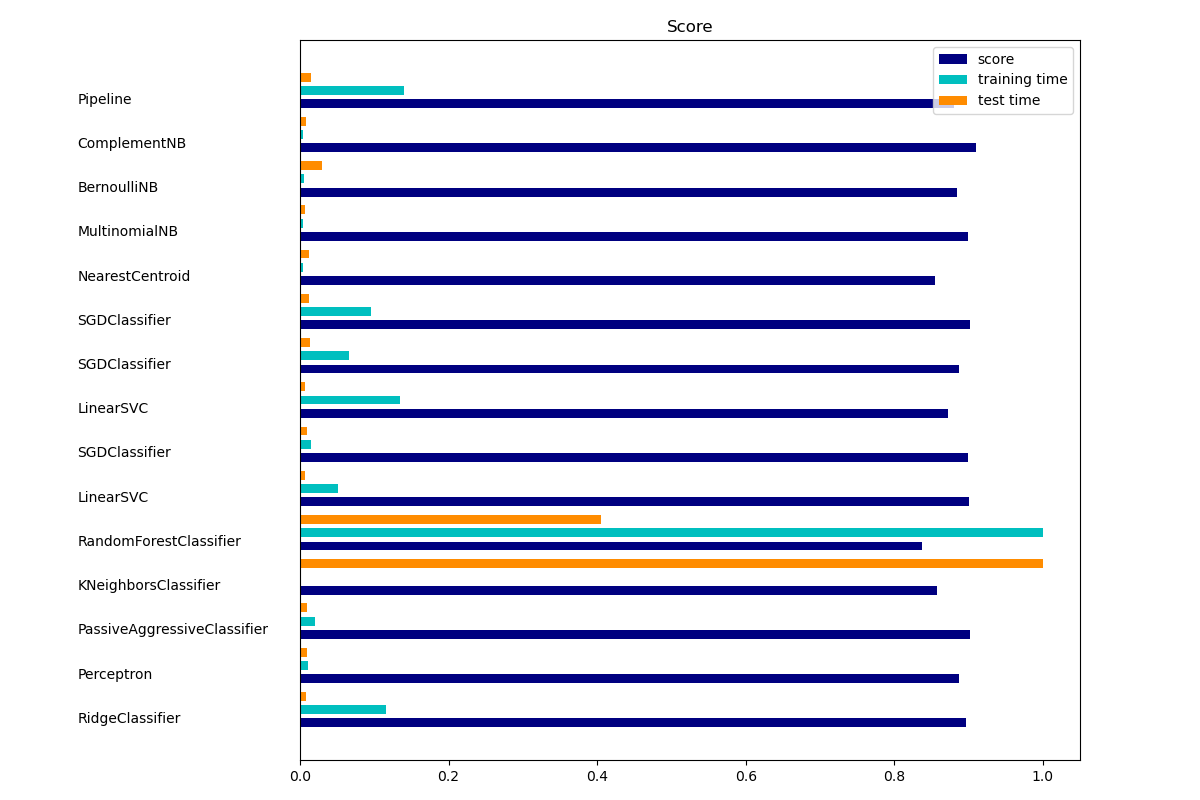
sklearn.feature_selection.SelectFromModel?
class sklearn.feature_selection.SelectFromModel(estimator, *, threshold=None, prefit=False, norm_order=1, max_features=None)
Meta-transformer用于根據重要度選擇特征。
0.17版中的新功能。
| 參數 | 說明 |
|---|---|
| estimator | object 用來構建transformer的基本估計器。既可以是擬合的(如果 prefit設置為True),也可以是不擬合的估計器。這個估計器擬合之后必須具有 feature_importances_或coef_屬性。 |
| threshold | string, float, optional default None 用于特征選擇的閾值。保留重要性更高或相等的特征,而其他特征則被丟棄。如果為“median”(或“mean”),則該 threshold值為要素重要性的中位數(或均值)。也可以使用縮放因子(例如,“ 1.25 *平均值”)。如果為None(無),并且估計器的參數懲罰顯式或隱式設置為L1(例如Lasso),則使用的閾值為1e-5。否則,默認使用“mean”。 |
| prefit | bool, default False 預設模型是否直接傳遞給構造函數。如果為True, transform必須直接調用并且SelectFromModel不能使用cross_val_score, GridSearchCV和與此估計類似的實用程序。否則,使用訓練模型fit,然后transform進行特征選擇。 |
| norm_order | non-zero int, inf, -inf, default 1 在估算器 threshold的coef_屬性為維度2 的情況下,用于過濾以下系數向量的范數的階數。 |
| max_features | int or None, optional 要選擇的最大特征數。若要僅基于 max_features選擇,請設置threshold=-np.inf。0.20版中的新功能。 |
| 屬性 | 說明 |
|---|---|
| estimator_ | an estimator 用來構建transformer的基估計器。僅當將非擬合估計量傳遞給 SelectFromModel時(即,當prefit為False時)才存儲。 |
| threshold_ | float 用于特征選擇的閾值。 |
注
如果基礎估算器也可以輸入,則允許NaN / Inf。
示例
>>> from sklearn.feature_selection import SelectFromModel
>>> from sklearn.linear_model import LogisticRegression
>>> X = [[ 0.87, -1.34, 0.31 ],
... [-2.79, -0.02, -0.85 ],
... [-1.34, -0.48, -2.55 ],
... [ 1.92, 1.48, 0.65 ]]
>>> y = [0, 1, 0, 1]
>>> selector = SelectFromModel(estimator=LogisticRegression()).fit(X, y)
>>> selector.estimator_.coef_
array([[-0.3252302 , 0.83462377, 0.49750423]])
>>> selector.threshold_
0.55245...
>>> selector.get_support()
array([False, True, False])
>>> selector.transform(X)
array([[-1.34],
[-0.02],
[-0.48],
[ 1.48]])
方法
| 方法 | 說明 |
|---|---|
fit(X[, y]) |
擬合SelectFromModel元轉換器。 |
fit_transform(X[, y]) |
擬合數據,然后對其進行轉換。 |
get_params([deep]) |
獲取此估計器的參數。 |
get_support([indices]) |
獲取所選特征的掩碼或整數索引。 |
inverse_transform(X) |
反向轉換操作 |
partial_fit(X[, y]) |
僅擬合SelectFromModel元轉換器一次。 |
set_params(**params) |
設置此估計器的參數。 |
transform(X) |
將X縮小為選定的特征。 |
__init__(estimator, *, threshold=None, prefit=False, norm_order=1, max_features=None)
初始化self,參見help(type(self))獲取更多信息。
fit(X, y=None, **fit_params)
擬合SelectFromModel元轉換器。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 訓練輸入樣本。 |
| y | array-like of shape (n_samples,) 目標值(與分類中的類對應的整數,回歸中的真實值)。 |
| **fit_params | Other estimator specific parameters |
| 返回值 | 說明 |
|---|---|
| self | object |
fit_transform(X, y=None, **fit_params)
擬合數據,然后對其進行轉換。
使用可選參數fit_params將轉換器擬合到X和y,并返回X的轉換值。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目標值 |
| **fit_params | dict 其他擬合參數。 |
| 返回值 | 說明 |
|---|---|
| X_new | ndarray array of shape (n_samples, n_features_new) 轉換后的數組。 |
get_params(deep=True)
獲取此估計器的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
get_support(indices=False)
獲取所選特征的掩碼或整數索引。
| 參數 | 說明 |
|---|---|
| indices | boolean (default False) 如果為True,則返回值將是一個整數數組,而不是布爾掩碼。 |
| 返回值 | 說明 |
|---|---|
| support | array 從特征向量中選擇保留特征的索引。如果 indices為False,則為形狀為[#輸入特征]的布爾數組,其中元素為True時(如果已選擇其對應的特征進行保留)。如果indices為True,則這是一個形狀為[#輸出特征]的整數數組,其值是輸入特征向量的索引。 |
inverse_transform(X)
反向轉換操作。
| 參數 | 說明 |
|---|---|
| X | array of shape [n_samples, n_selected_features] 輸入樣本。 |
| 返回值 | 說明 |
|---|---|
| X_r | array of shape [n_samples, n_original_features]X中插入的列名為零的特征將被transform刪除。 |
partial_fit(X, y=None, **fit_params)
僅擬合SelectFromModel元轉換器一次。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 訓練輸入樣本。 |
| y | array-like, shape (n_samples,) 目標值(與分類中的類對應的整數,回歸中的真實值)。 |
| **fit_params | Other estimator specific parameters |
| 返回值 | 說明 |
|---|---|
| self | object |
set_params(**params)
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。后者具有<component>__<parameter>形式的參數, 以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估計器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估計器實例。 |
transform(X)
將X縮小為選定的特征。
| 參數 | 說明 |
|---|---|
| X | array of shape [n_samples, n_features] 輸入樣本。 |
| 返回值 | 說明 |
|---|---|
| X_r | array of shape [n_samples, n_selected_features] 僅具有所選特征的輸入樣本。 |