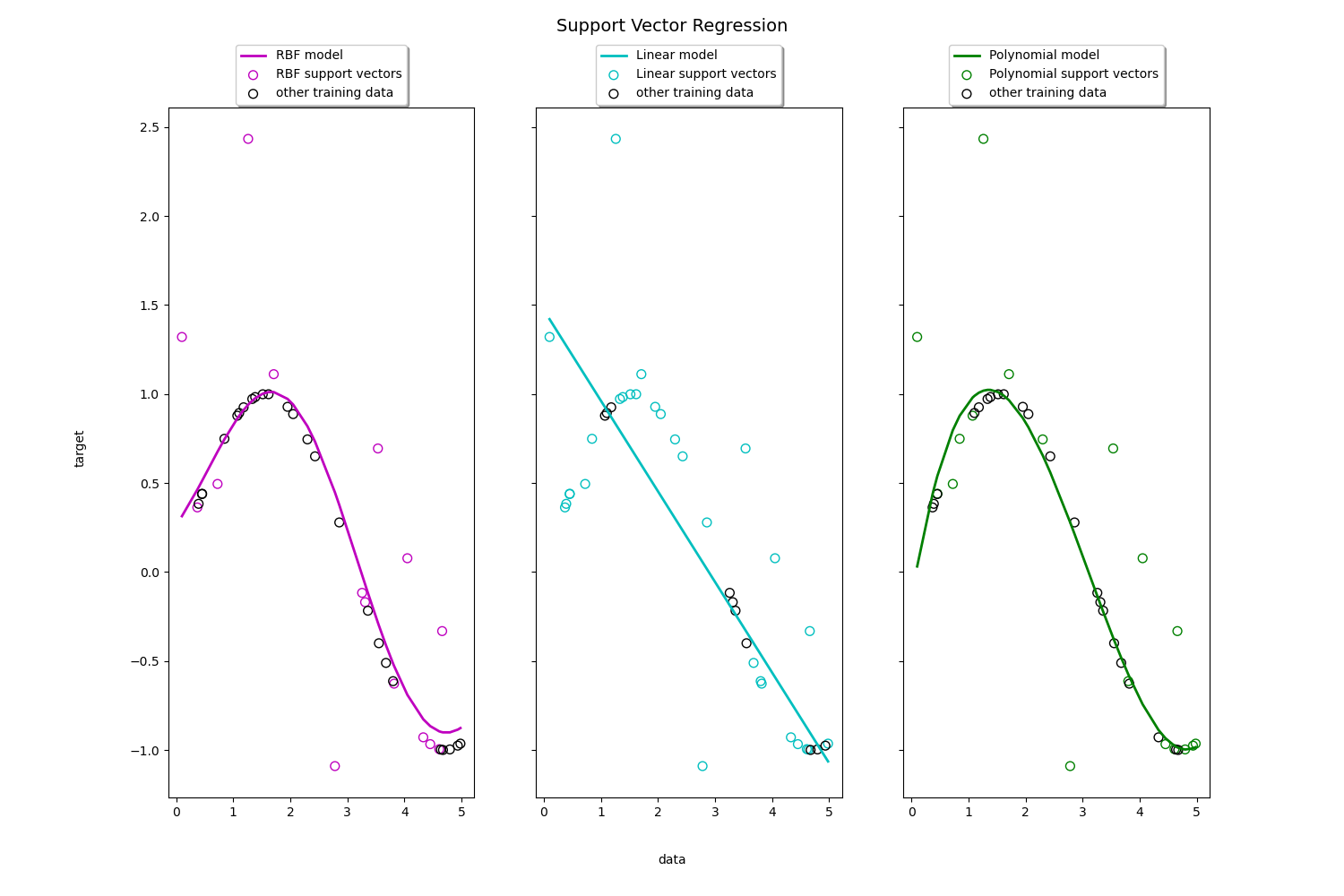
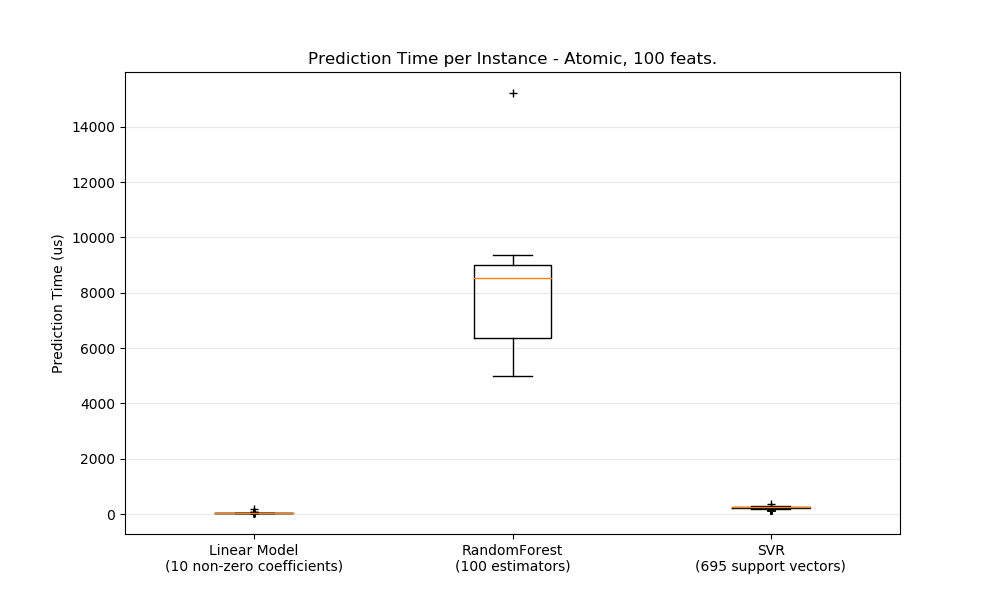
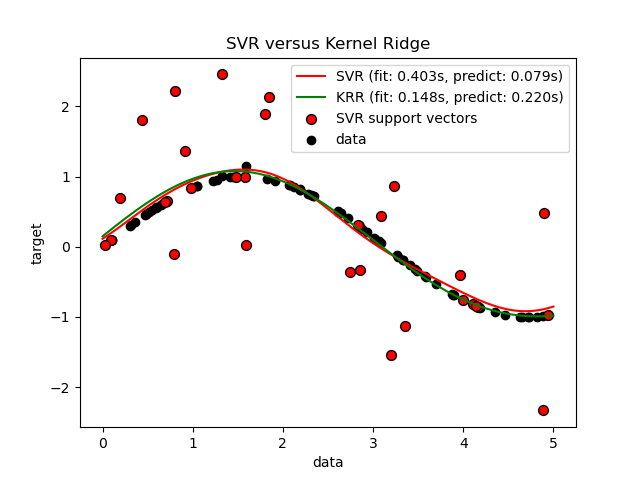
sklearn.svm.SVR?
class sklearn.svm.SVR(*, kernel='rbf', degree=3, gamma='scale', coef0=0.0, tol=0.001, C=1.0, epsilon=0.1, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
Epsilon支持向量回歸。
模型中的自由參數是C和epsilon。
該實現基于libsvm。
擬合時間的復雜度是樣本數量的兩倍以上,這使得很難擴展到具有多個10000個樣本的數據集。對于大型數據集,可以考慮在使用了 sklearn.kernel_approximation.Nystroem 后,用sklearn.svm.LinearSVR或sklearn.linear_model.SGDRegressor替代。
更多信息請參閱 用戶指南
| 參數 | 說明 |
|---|---|
| kernel | {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, 默認=’rbf’ 指定算法中使用的內核類型。它必須是“linear”,“poly”,“rbf”,“sigmoid”,“precomputed”或者“callable”中的一個。如果沒有給出,將默認使用“rbf”。如果給定了一個可調用函數,則用它來預先計算核矩陣。 |
| degree | 整數型,默認=3 多項式核函數的次數(' poly ')。將會被其他內核忽略。 |
| gamma | 浮點數或者{‘scale’, ‘auto’} , 默認=’scale’ 核系數包含‘rbf’, ‘poly’ 和‘sigmoid’ |
| coef0 | 浮點數,默認=0.0 核函數中的獨立項。它只在' poly '和' sigmoid '中有意義。 |
| tol | 浮點數,默認=1e-3 殘差收斂條件。 |
| C | 浮點數,默認= 1.0 正則化參數。正則化的強度與C成反比。必須嚴格為正。此懲罰系數是l2懲罰系數的平方 |
| epsilon | 浮點數, 默認= 0.1 epsilon-SVR模型中的Epsilon。它指定了在訓練損失函數中預測值與實際值之間距離為epsilon的epsilon-tube。 |
| shrinking | 布爾值,默認=True 是否使用縮小啟發式,參見使用指南. |
| cache_size | 浮點數,默認=200 指定內核緩存的大小(以MB為單位)。 |
| verbose | 布爾值,默認=False 是否啟用詳細輸出。請注意,此參數針對liblinear中運行每個進程時設置,如果啟用,則可能無法在多線程上下文中正常工作。 |
| max_iter | 整數型,默認=-1 對求解器內的迭代進行硬性限制,或者為-1(無限制時)。 |
| 屬性 | 說明 |
|---|---|
| support_ | 形如(n_SV,)的數組 支持向量的指標。 |
| support_vectors_ | 形如(n_SV, n_features)的數組 支持向量 |
| n_support_ | 形如(n_class)的數組,dtype=int32 每個類別的支持向量數量。 |
| dual_coef_ | 形如(n_class-1, n_SV)的數組 決策函數中支持向量的系數。 |
| coef_ | 形如(n_class * (n_class-1) / 2, n_features)的數組 分配給特征的權重(原始問題的系數),僅在線性內核的情況下可用。coef_是一個繼承自raw_coef_的只讀屬性,它遵循liblinear的內部存儲器布局。 |
| fit_status_ | 整數型 如果擬合無誤,則為0;否則為1(將會引發警告) |
| intercept_ | 形如(n_class * (n_class-1) / 2,)的數組 決策函數中的常量。 |
另見:
支持向量機的回歸使用libsvm實現,使用一個參數來控制支持向量的數量。
可擴展線性支持向量機使用liblinear進行分類。
參考文獻:
示例:
>>> from sklearn.svm import SVR
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> import numpy as np
>>> n_samples, n_features = 10, 5
>>> rng = np.random.RandomState(0)
>>> y = rng.randn(n_samples)
>>> X = rng.randn(n_samples, n_features)
>>> regr = make_pipeline(StandardScaler(), SVR(C=1.0, epsilon=0.2))
>>> regr.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('svr', SVR(epsilon=0.2))])
方法:
fit(X, y[, sample_weight]) |
根據給定的訓練數據擬合支持向量機模型。 |
|---|---|
get_params([deep]) |
獲取這個估計器的參數。 |
predict(X) |
在X中對樣本進行分類 |
score(X, y[, sample_weight]) |
返回預測的決定系數R^2。 |
set_params(**params) |
設置這個估計器的參數。 |
__init__(*, kernel='rbf', degree=3, gamma='scale', coef0=0.0, tol=0.001, C=1.0, epsilon=0.1, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
初始化self。請參閱help(type(self)獲取準確的說明。
fit(X, y, sample_weight=None)
根據給定的訓練數據擬合支持向量機模型。
| 參數 | 說明 |
|---|---|
| X | 形如(n_samples, n_features) 或者 (n_samples, n_samples)的數組或者稀疏矩陣 訓練向量,其中n_samples為樣本數量,n_features為特征數量。對于kernel= " precomputed ", X的期望形狀為(n_samples, n_samples)。 |
| y | 形如(n_samples,)的數組 目標值(分類中的類標簽,回歸中的實數) |
| sample_weight | 形如(n_samples,)的數組,默認=None 樣本的權重。每個樣品重新定標C。較高的權重將使分類器更加注重這些樣本點。 |
| 返回值 | 說明 |
|---|---|
| self | object |
注:
如果X和y不是C-ordered,并且np.float64和X的連續數組不是scipy.sparse.csr_matrix,則可以復制X或y。
如果X是一個連續數組,則其他方法將不支持將稀疏矩陣作為輸入。
get_params(deep=True)
| 參數 | 說明 |
|---|---|
| deep | bool, default = True 如果為真,則將返回此估計量和作為估計量的所包含子對象的參數 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名被映射至他們的值 |
predict(X)
對X中的樣本執行分類。
對于返回值為+1或-1的one-class模型
| 參數 | 說明 |
|---|---|
| X | 形如(n_samples, n_features) 或者 (n_samples_test, n_samples_train)的數組或者稀疏矩陣 對于內核=“precomputed”,X的預期形狀為(n_samples_test,n_samples_train)。 |
| 返回值 | 說明 |
|---|---|
| y_pred | 形如(n_sample, )的數組 X中樣本的類別標簽。 |
score(X, y, sample_weight=None)
返回預測的決定系數R^2。
定義決定系數R^2為(1 - u/v),其中u為(y_true - y_pred) ** 2).sum()的殘差平方和,v為(y_true - y_true.mean()) ** 2).sum()的平方和。最好的分數可能是1.0,同時它可能是負的(因為模型可以任意地更糟)。一個常數模型總是預測y的期望值,而不考慮輸入特征,得到的R^2值為0.0。
| 參數 | 說明 |
|---|---|
| X | 形如 (n_samples, n_features)的數組 測試樣本。對于某些估計器,這可能是一個預先計算的內核矩陣或一列通用對象,而不是形狀為(n_samples, n_samples_fitting)的數組,其中n_samples_fitting是用于擬合估計器的樣本數量。 |
| y | 形如(n_samples,) 或者 (n_samples, n_outputs)的數組 X中結果為真的標簽 |
| sample_weight | 形如(n_samples,)的數組,默認=None 樣本的權重 |
| 返回值 | 說明 |
|---|---|
| score | 浮點數 self.predict(X) wrt. y的R^2 |
注:
調用回歸變量上的score時,使用的R2 score(0.23版本)中的multioutput='uniform_average'來保持與r2_score的默認值一致。這影響了所有多輸出回歸的score方法(除了 MultiOutputRegressor)。
set_params(**params)
設置此估算器的參數。
該方法適用于簡單估計器和嵌套對象(如管道)。后者具有形式為 <component>__<parameter>的參數,這樣就可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| params | 字典 估算器參數 |
| 返回值 | 說明 |
|---|---|
| self | object 估算器實例 |