對“玩具數據集”進行異常檢測,并比較異常檢測算法?
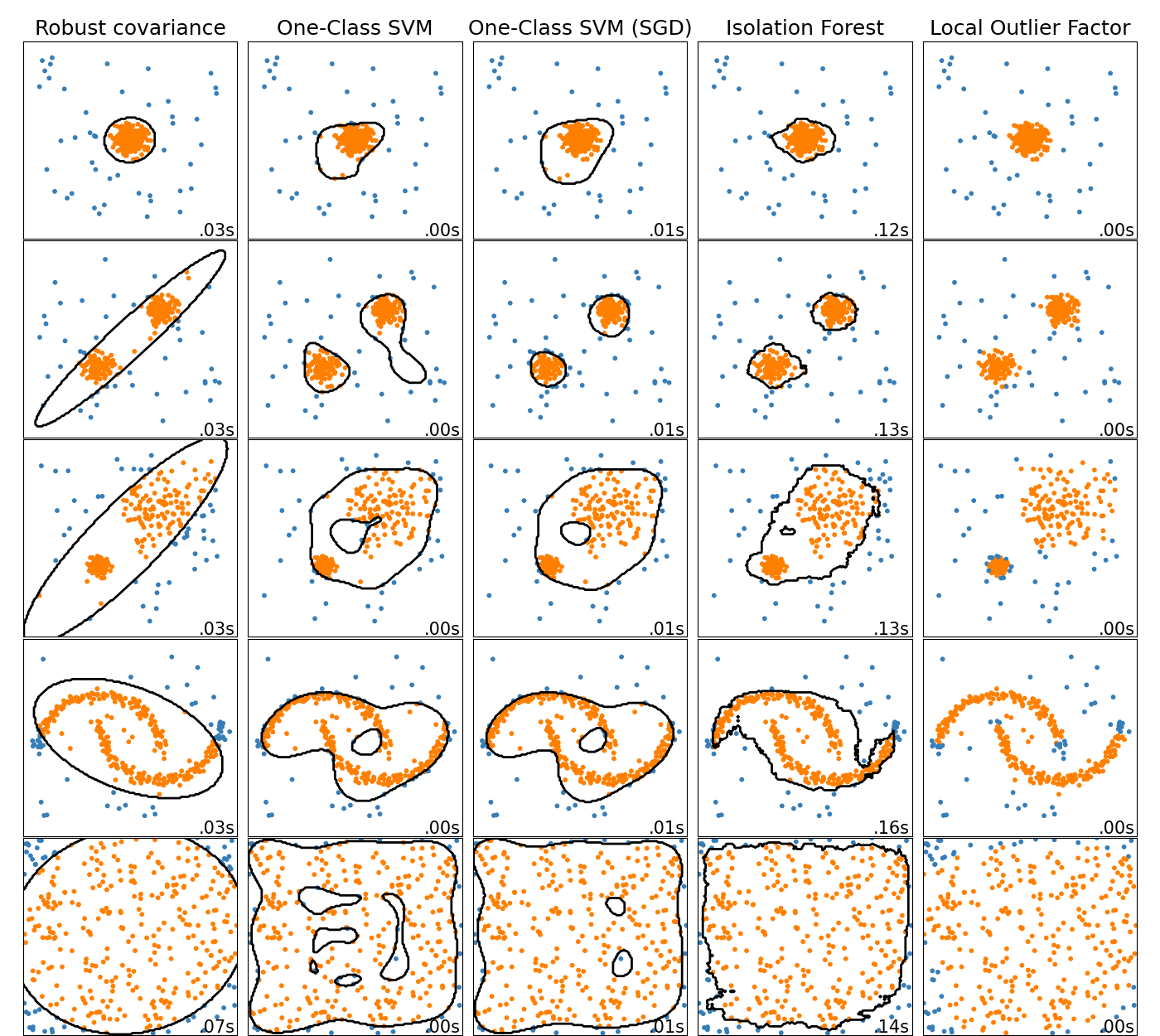
此示例顯示了二維數據集上不同異常檢測算法的特色。數據集包含一種或兩種模式(高密度區域),以說明算法處理多模式數據的能力。
對于每個數據集,將生成15%的樣本作為隨機均勻噪聲。該比例是為OneClassSVM的nu參數和其他異常值檢測算法的污染參數提供的值。離群值和離群值之間的決策邊界以黑色顯示,但局部離群值因子(LOF)除外,因為當用于離群值檢測時,它沒有適用于新數據的預測方法。
已知sklearn.svm.OneClassSVM對異常值敏感,因此在異常值檢測方面表現不佳。當訓練集不受異常值污染時,此估算器最適合新穎性檢測。也就是說,在高維中進行離群值檢測,或者不對基礎數據的分布進行任何假設,都是非常具有挑戰性的,一類SVM在這些情況下可能會根據其超參數的值給出有用的結果。
sklearn.covariance.EllipticEnvelope假定數據為高斯并學習一個橢圓。因此,當數據不是單峰時,它會降級。但是請注意,此估計量對異常值具有魯棒性。
對于多模式數據集,sklearn.ensemble.IsolationForest和sklearn.neighbors.LocalOutlierFactor的表現似乎相當不錯。對于第三個數據集,顯示了sklearn.neighbors.LocalOutlierFactor相對于其他估算器的優勢,其中兩個模式的密度不同。 LOF的局部方面解釋了這一優勢,這意味著它僅將一個樣本的異常評分與其鄰居的評分進行比較。
最后,對于最后一個數據集,很難說一個樣本比另一個樣本異常得多,因為它們均勻分布在超立方體中。除了sklearn.svm.OneClassSVM有點過擬合外,所有估算器都針對這種情況提供了不錯的解決方案。在這種情況下,明智的做法是仔細觀察樣本的異常分數,因為好的估算者應該為所有樣本分配相似的分數。
盡管這些示例給出了有關算法的一些直覺,但這種直覺可能不適用于非常高維的數據。
最后,請注意,此處已手動選擇了模型的參數,但實際上需要對其進行調整。在沒有標記數據的情況下,該問題是完全不受監督的,因此選擇模型可能是一個挑戰。
# 作者: Alexandre Gramfort <alexandre.gramfort@inria.fr>
# Albert Thomas <albert.thomas@telecom-paristech.fr>
# 執照: BSD 3 clause
import time
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_moons, make_blobs
from sklearn.covariance import EllipticEnvelope
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
print(__doc__)
matplotlib.rcParams['contour.negative_linestyle'] = 'solid'
# 設置基本參數
n_samples = 300
outliers_fraction = 0.15
n_outliers = int(outliers_fraction * n_samples)
n_inliers = n_samples - n_outliers
# 定義需要比較的異常值/離群值檢測方法
anomaly_algorithms = [
("Robust covariance", EllipticEnvelope(contamination=outliers_fraction)),
("One-Class SVM", svm.OneClassSVM(nu=outliers_fraction, kernel="rbf",
gamma=0.1)),
("Isolation Forest", IsolationForest(contamination=outliers_fraction,
random_state=42)),
("Local Outlier Factor", LocalOutlierFactor(
n_neighbors=35, contamination=outliers_fraction))]
# 定義數據集
blobs_params = dict(random_state=0, n_samples=n_inliers, n_features=2)
datasets = [
make_blobs(centers=[[0, 0], [0, 0]], cluster_std=0.5,
**blobs_params)[0],
make_blobs(centers=[[2, 2], [-2, -2]], cluster_std=[0.5, 0.5],
**blobs_params)[0],
make_blobs(centers=[[2, 2], [-2, -2]], cluster_std=[1.5, .3],
**blobs_params)[0],
4. * (make_moons(n_samples=n_samples, noise=.05, random_state=0)[0] -
np.array([0.5, 0.25])),
14. * (np.random.RandomState(42).rand(n_samples, 2) - 0.5)]
# 在給定的設定下,比較分類器
xx, yy = np.meshgrid(np.linspace(-7, 7, 150),
np.linspace(-7, 7, 150))
plt.figure(figsize=(len(anomaly_algorithms) * 2 + 3, 12.5))
plt.subplots_adjust(left=.02, right=.98, bottom=.001, top=.96, wspace=.05,
hspace=.01)
plot_num = 1
rng = np.random.RandomState(42)
for i_dataset, X in enumerate(datasets):
# 增加離群值
X = np.concatenate([X, rng.uniform(low=-6, high=6,
size=(n_outliers, 2))], axis=0)
for name, algorithm in anomaly_algorithms:
t0 = time.time()
algorithm.fit(X)
t1 = time.time()
plt.subplot(len(datasets), len(anomaly_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
# 擬合數據并標記出離群值
if name == "Local Outlier Factor":
y_pred = algorithm.fit_predict(X)
else:
y_pred = algorithm.fit(X).predict(X)
# 繪制等高線以及點
if name != "Local Outlier Factor": # LOF不執行預測
Z = algorithm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='black')
colors = np.array(['#377eb8', '#ff7f00'])
plt.scatter(X[:, 0], X[:, 1], s=10, color=colors[(y_pred + 1) // 2])
plt.xlim(-7, 7)
plt.ylim(-7, 7)
plt.xticks(())
plt.yticks(())
plt.text(.99, .01, ('%.2fs' % (t1 - t0)).lstrip('0'),
transform=plt.gca().transAxes, size=15,
horizontalalignment='right')
plot_num += 1
plt.show()
輸出:
腳本的總運行時間:(0分鐘7.474秒)