分類器鏈?
我們看在多標簽數據集上使用分類器鏈的示例。
在此示例中,我們將使用酵母數據集,其中包含2417個數據點,每個數據點具有103個特征和14個可能的標簽。每個數據點至少具有一個標簽。作為基線,我們首先為14個標簽中的每個標簽訓練邏輯回歸分類器。為了評估這些分類器的性能,我們對保留的測試集進行了預測,并計算了每個樣本的jaccard得分。
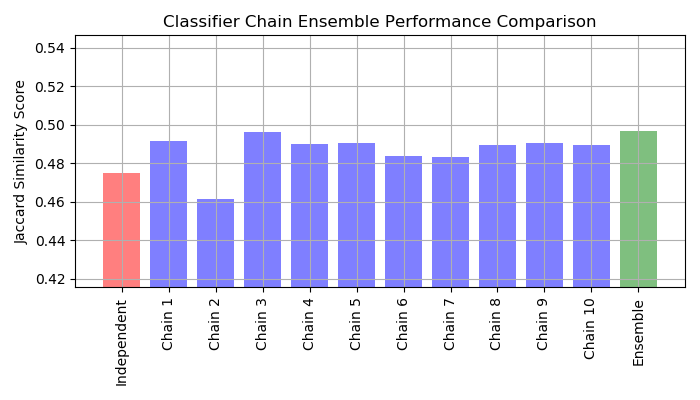
接下來,我們創建10個分類器鏈。每個分類器鏈包含14個標簽中每個標簽的邏輯回歸模型。每個鏈中的模型都是隨機排序的。除了數據集中的103個要素外,每個模型還將鏈中先前模型的預測作為要素(請注意,默認情況下,在訓練時,每個模型都將真實標簽作為要素)。這些附加功能允許每個鏈利用類之間的相關性。每條鏈的Jaccard相似性得分往往要高于所設置的獨立邏輯模型的得分。
因為每個鏈中的模型都是隨機排列的,所以鏈之間的性能存在顯著差異。大概鏈中的類有最佳排序,這將產生最佳性能。但是,我們不知道先驗順序。相反,我們可以通過平均分類器鏈的二進制預測并應用閾值0.5來構建分類器鏈的投票合奏。集成的Jaccard相似度得分高于獨立模型的Jaccard相似度得分,并且往往超過集成中每個鏈的得分(盡管隨機排序的鏈不能保證這一點)。
輸入:
# 作者: Adam Kleczewski
# 執照: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.multioutput import ClassifierChain
from sklearn.model_selection import train_test_split
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import jaccard_score
from sklearn.linear_model import LogisticRegression
print(__doc__)
# 從頁面https://www.openml.org/d/40597導入一個多標簽的數據集
X, Y = fetch_openml('yeast', version=4, return_X_y=True)
Y = Y == 'TRUE'
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.2,
random_state=0)
# 使用OneVsRestClassifie打包的方式,為每個標簽類別擬合一個獨立的邏輯回歸模型
base_lr = LogisticRegression()
ovr = OneVsRestClassifier(base_lr)
ovr.fit(X_train, Y_train)
Y_pred_ovr = ovr.predict(X_test)
ovr_jaccard_score = jaccard_score(Y_test, Y_pred_ovr, average='samples')
# 擬合邏輯回歸分類器鏈的集合,并對所有鏈進行平均預測
chains = [ClassifierChain(base_lr, order='random', random_state=i)
for i in range(10)]
for chain in chains:
chain.fit(X_train, Y_train)
Y_pred_chains = np.array([chain.predict(X_test) for chain in
chains])
chain_jaccard_scores = [jaccard_score(Y_test, Y_pred_chain >= .5,
average='samples')
for Y_pred_chain in Y_pred_chains]
Y_pred_ensemble = Y_pred_chains.mean(axis=0)
ensemble_jaccard_score = jaccard_score(Y_test,
Y_pred_ensemble >= .5,
average='samples')
model_scores = [ovr_jaccard_score] + chain_jaccard_scores
model_scores.append(ensemble_jaccard_score)
model_names = ('Independent',
'Chain 1',
'Chain 2',
'Chain 3',
'Chain 4',
'Chain 5',
'Chain 6',
'Chain 7',
'Chain 8',
'Chain 9',
'Chain 10',
'Ensemble')
x_pos = np.arange(len(model_names))
# 繪制獨立模型,計算每個鏈和集合的Jaccard相似度得分
#(請注意,此圖的垂直軸并非始于0)。
fig, ax = plt.subplots(figsize=(7, 4))
ax.grid(True)
ax.set_title('Classifier Chain Ensemble Performance Comparison')
ax.set_xticks(x_pos)
ax.set_xticklabels(model_names, rotation='vertical')
ax.set_ylabel('Jaccard Similarity Score')
ax.set_ylim([min(model_scores) * .9, max(model_scores) * 1.1])
colors = ['r'] + ['b'] * len(chain_jaccard_scores) + ['g']
ax.bar(x_pos, model_scores, alpha=0.5, color=colors)
plt.tight_layout()
plt.show()
輸出:
 腳本的總運行時間:(0分鐘6.911秒)。
腳本的總運行時間:(0分鐘6.911秒)。