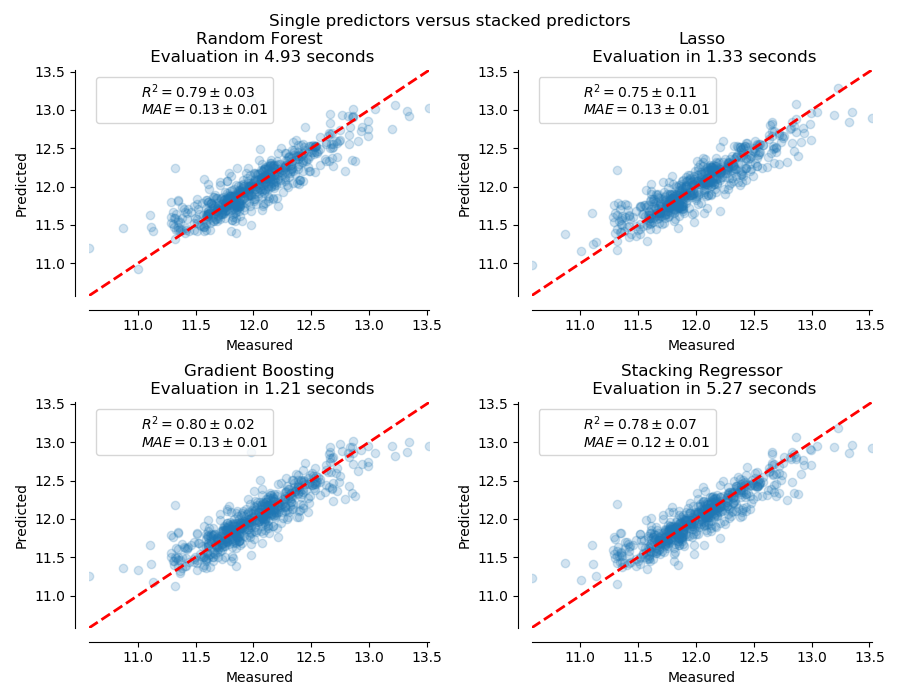
sklearn.compose.make_column_transformer?
sklearn.compose.make_column_transformer(*transformers, **kwargs)
從給定的轉換器構造一個列轉換器。
這是ColumnTransformer構造的縮寫;它不需要也不允許命名轉換器。相反,它們將根據其類型自動命名。它也不允許使用transformer_weights進行加權。
在用戶指南中閱讀更多內容.
| 參數 | 說明 |
|---|---|
| *transformers | tuples 指定要應用于數據子集的轉換器對象的表單(轉換器、列)的元組 |
| transformer | {‘drop’, ‘passthrough’} or estimator 估計器必須支持fit和transform。特殊大小寫的字符串‘drop’和‘passthrough’也被接受,分別表示要刪除列或將它們傳遞給未轉換的列。 |
| columns | str, array-like of str, int, array-like of int, slice, array-like of bool or callable 在其第二軸上索引數據。整數被解釋為位置列,而字符串可以按名稱引用DataFrame列。應該使用標量字符串或int,如果 transformer期望X是一維數組類(向量),否則2d數組將傳遞給轉換器。可調用傳遞輸入數據X,并可以返回上述任何內容。若要按名稱或dtype選擇多列,可以使用make_column_selector。 |
| remainder | {‘drop’, ‘passthrough’} or estimator, default=’drop’ 默認情況下,只有 transformers中的指定列在輸出中轉換和組合,而非指定列被刪除。(默認‘drop’)。通過指定remainder='passthrough',所有未在transformers中指定的其余列都將自動通過。這個列的子集與的transformers輸出連接在一起。通過將remainder設置為估計器,其余未指定的列將使用remainder估計器。估計器必須支持fit和transform。請注意,使用此特性需要在fit和transform中輸入的DataFrame列具有相同的順序。 |
| sparse_threshold | float, default=0.3 如果不同的轉換器輸出含有稀疏矩陣,則如果總密度低于此值,則將這些矩陣疊加為稀疏矩陣。使用 sparse_threshold=0來始終返回稠密。當轉換后的輸出由所有密集數據組成時,疊加的結果將是密集的,而這個關鍵字將被忽略。 |
| n_jobs | int, default=None 要運行的并行數。 None意味1, 除非在joblib.parallel_backend環境中。-1指使用所有處理器。有關詳細信息,請參Glossary。 |
| verbose | bool, default=False 如果是True,擬合每個變壓器所需的時間將在完成時打印出來。 |
| 返回值 | 說明 |
|---|---|
| ct | ColumnTransformer |
另見
sklearn.compose.ColumnTransformer該類允許將數據列子集上使用的多個轉換器對象的輸出組合到單個要素空間中。
示例
>>> from sklearn.preprocessing import StandardScaler, OneHotEncoder
>>> from sklearn.compose import make_column_transformer
>>> make_column_transformer(
... (StandardScaler(), ['numerical_column']),
... (OneHotEncoder(), ['categorical_column']))
ColumnTransformer(transformers=[('standardscaler', StandardScaler(...),
['numerical_column']),
('onehotencoder', OneHotEncoder(...),
['categorical_column'])])