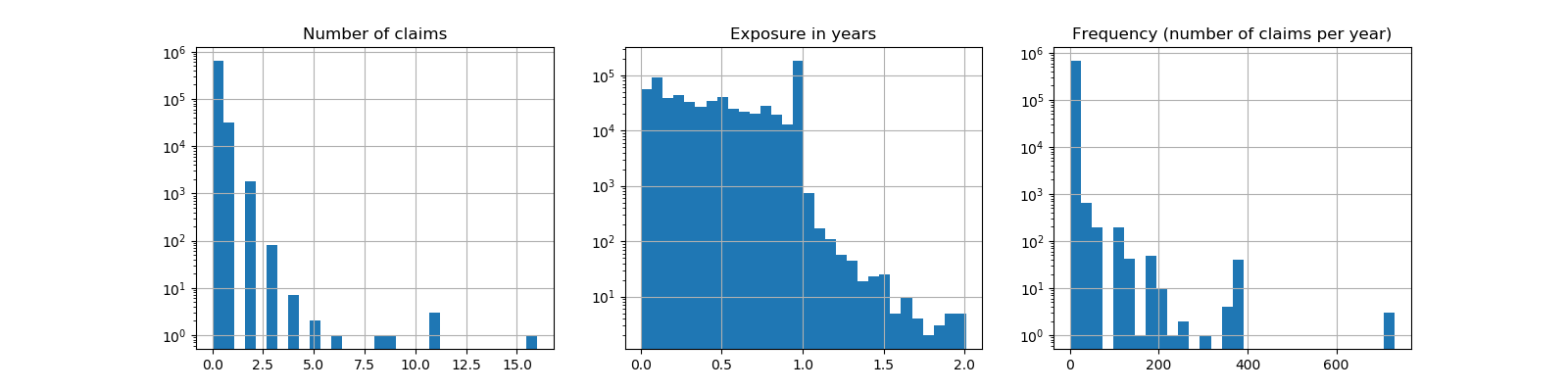
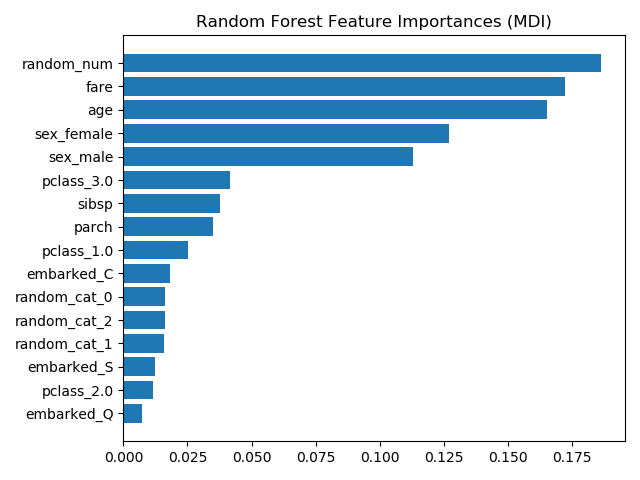
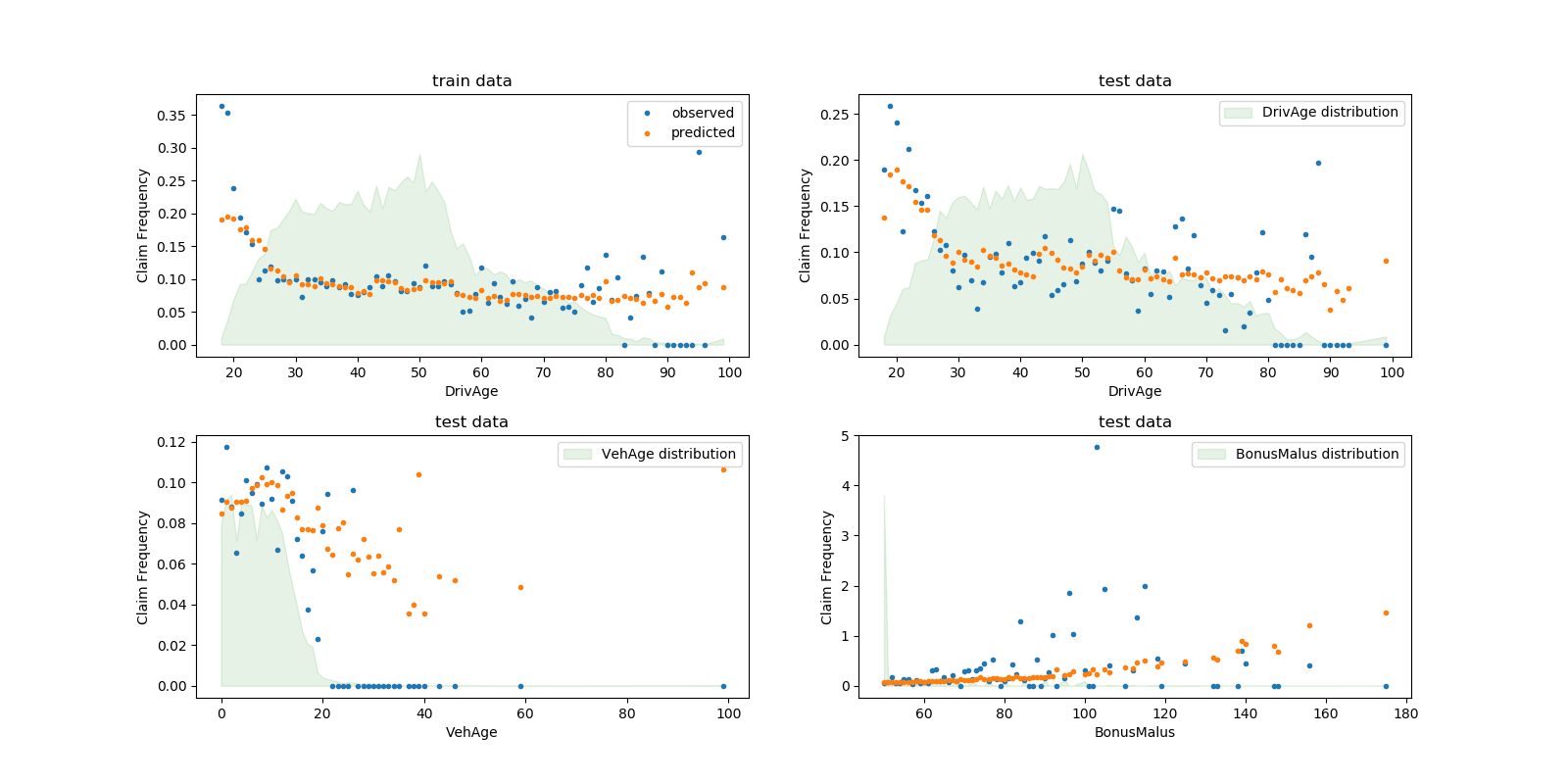
sklearn.compose.ColumnTransformer?
class sklearn.compose.ColumnTransformer(transformers, *, remainder='drop', sparse_threshold=0.3, n_jobs=None, transformer_weights=None, verbose=False)
將轉換器應用于數組或pandas 的 DataFrame的列
該估計器允許獨立地轉換輸入的不同列或列子集,并將每個轉換器生成的特征連接起來形成一個單一的特征空間。這對于異構或柱狀數據非常有用,可以將多個特征提取機制或轉換組合成單個轉換器。
在用戶指南中閱讀更多內容
New in version 0.20.
| 參數 | 說明 |
|---|---|
| transformers | list of tuples 指定要應用于數據子集的轉換器對象的元組列表(名稱、轉換器、列)。 |
| name | str 與Pipeline和FeatureUnion一樣,這允許使用 set_params設置變壓器及其參數,并在網格搜索中進行搜索。 |
| transformer | {‘drop’, ‘passthrough’} or estimator 估計器必須支持fit和transform。特殊大小寫的字符串‘drop’和‘passthrough’也被接受,分別表示要刪除列或將它們傳遞給未轉換的列。 |
| columns | str, array-like of str, int, array-like of int, array-like of bool, slice or callable 在其第二軸上索引數據。整數被解釋為位置列,而字符串可以按名稱引用DataFrame列。應該使用標量字符串或int,如果 transformer期望X是一維數組類(向量),否則2d數組將傳遞給轉換器。可調用傳遞輸入數據X,并可以返回上述任何內容。若要按名稱或dtype選擇多列,可以使用make_column_selector。 |
| remainder | {‘drop’, ‘passthrough’} or estimator, default=’drop’ 默認情況下,只有 transformers中的指定列在輸出中轉換和組合,而非指定列被刪除。(默認‘drop’)。通過指定remainder='passthrough',所有未在transformers中指定的其余列都將自動通過。這個列的子集與的transformers輸出連接在一起。通過將remainder設置為估計器,其余未指定的列將使用remainder估計器。估計器必須支持fit和transform。請注意,使用此特性需要在fit和transform中輸入的DataFrame列具有相同的順序。 |
| sparse_threshold | float, default=0.3 如果不同的轉換器輸出含有稀疏矩陣,則如果總密度低于此值,則將這些矩陣疊加為稀疏矩陣。使用 sparse_threshold=0來始終返回稠密。當轉換后的輸出由所有密集數據組成時,疊加的結果將是密集的,而這個關鍵字將被忽略。 |
| n_jobs | int, default=None 要運行的并行數。 None意味1, 除非在joblib.parallel_backend環境中。-1指使用所有處理器。有關詳細信息,請參Glossary。 |
| transformer_weights | dict, default=None 每個轉換器特征的權重。轉換器的輸出乘以這些權重。鍵是轉換器名稱,值權重。 |
| verbose | bool, default=False 如果是真的,安裝每個變壓器所需的時間將在完成時打印出來。 |
| 屬性 | 說明 |
|---|---|
| transformers_ | list 安裝transformers的集合,作為(name, fitted_transformer, column)的元組。 fitted_transformer可以是一個估計器,‘drop’, 或者 ‘passthrough’。如果沒有選擇列,這將是未擬合的轉換器。如果還有剩余的列,則最后一個元素是一個元組:(‘remainder’, transformer, remaining_columns),對應于remainder參數。如果還有剩余的列, 那么len(transformers_)==len(transformers)+1, 否則len(transformers_)==len(transformers)。named_transformers_Bunch按名稱訪問擬合的轉換器 |
| sparse_output_ | bool 布爾標志指示 transform的輸出是稀疏矩陣還是稠密的numpy數組,這取決于各個轉換器的輸出和sparse_threshold關鍵字。 |
另見
sklearn.compose.make_column_transformer便利功能,用于組合應用于原始特征空間的列子集的多個變壓器對象的輸出。
sklearn.compose.make_column_selector便利功能,用于基于數據類型或帶有正則表達式模式的列名稱選擇列。
注
轉換后的特征矩陣中列的順序遵循transformers列表中列的指定順序。未指定的原始特征矩陣的列將從結果轉換的特征矩陣中刪除,除非在passthrough關鍵字中指定。用passthrough指定的列將被添加到轉換器器輸出的右側。
示例
>>> import numpy as np
>>> from sklearn.compose import ColumnTransformer
>>> from sklearn.preprocessing import Normalizer
>>> ct = ColumnTransformer(
... [("norm1", Normalizer(norm='l1'), [0, 1]),
... ("norm2", Normalizer(norm='l1'), slice(2, 4))])
>>> X = np.array([[0., 1., 2., 2.],
... [1., 1., 0., 1.]])
>>> # Normalizer scales each row of X to unit norm. A separate scaling
>>> # is applied for the two first and two last elements of each
>>> # row independently.
>>> ct.fit_transform(X)
array([[0. , 1. , 0.5, 0.5],
[0.5, 0.5, 0. , 1. ]])
方法
| 方法 | 說明 |
|---|---|
fit(self, X[, y]) |
使用X擬合所有轉換器 |
fit_transform(self, X[, y]) |
擬合所有轉換器,轉換數據并連接結果 |
get_feature_names(self) |
從所有轉換器獲取特征名稱 |
get_params(self[, deep]) |
獲取此估計器的參數 |
set_params(self, **kwargs) |
設置此估計器的參數 |
transform(self, X) |
由每個轉換器分別變換X,連接結果 |
__init__(self, transformers, *, remainder='drop', sparse_threshold=0.3, n_jobs=None, transformer_weights=None, verbose=False)
初始化self。請參閱help(type(self))以獲得準確的說明。
fit(self, X, y=None)
使用X擬合所有轉換器
| 參數 | 說明 |
|---|---|
| X | {array-like, dataframe} of shape (n_samples, n_features) 輸入數據,其中指定的子集用于擬合轉換器。 |
| y | array-like of shape (n_samples,…), default=None 監督學習目標 |
| 返回值 | 說明 |
|---|---|
| self | ColumnTransformer 這個估計器 |
fit_transform(self, X, y=None)
擬合所有轉換器,轉換數據并連接結果
| 參數 | 說明 |
|---|---|
| X | {array-like, dataframe} of shape (n_samples, n_features) 輸入數據,其中指定的子集用于擬合轉換器。 |
| y | array-like of shape (n_samples,), default=None 監督學習的目標 |
| 返回值 | 說明 |
|---|---|
| X_t | {array-like, sparse matrix} of shape (n_samples, sum_n_components) 變壓器的結果。transformers. sum_n_components的結果的堆疊是輸出維度的轉換之和。如果結果是稀疏矩陣,則一切都將轉換為稀疏矩陣。 |
get_feature_names(self)
從所有轉換器獲取特征名稱
| 返回值 | 說明 |
|---|---|
| feature_names | list of strings 轉換產生的特征的名稱 |
get_params(self, deep=True)
獲取此估計器的參數
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估計器的參數和所包含的作為估計器的子對象。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 映射到其值的參數名稱 |
property named_transformers_
按名稱訪問擬合的轉換器
可按給定名稱訪問任何轉換器的只讀屬性。鍵是轉換器名稱,值是已擬合的轉換器對象。
set_params(self, **kwargs)
設置此估計器的參數
有效的參數鍵可以用get_params()列出。
| 返回值 | 說明 |
|---|---|
| self | - |
transform(self, X)
由各轉換器分別變換X,鏈接結果。
| 參數 | 列表 |
|---|---|
| X | {array-like, dataframe} of shape (n_samples, n_features) 要由子集轉換的數據 |
| 返回值 | 說明 |
|---|---|
| X_t | {array-like, sparse matrix} of shape (n_samples, sum_n_components) 變壓器的結果。transformers. sum_n_components的結果的堆疊是輸出維度的轉換之和。如果結果是稀疏矩陣,則一切都將轉換為稀疏矩陣。 |