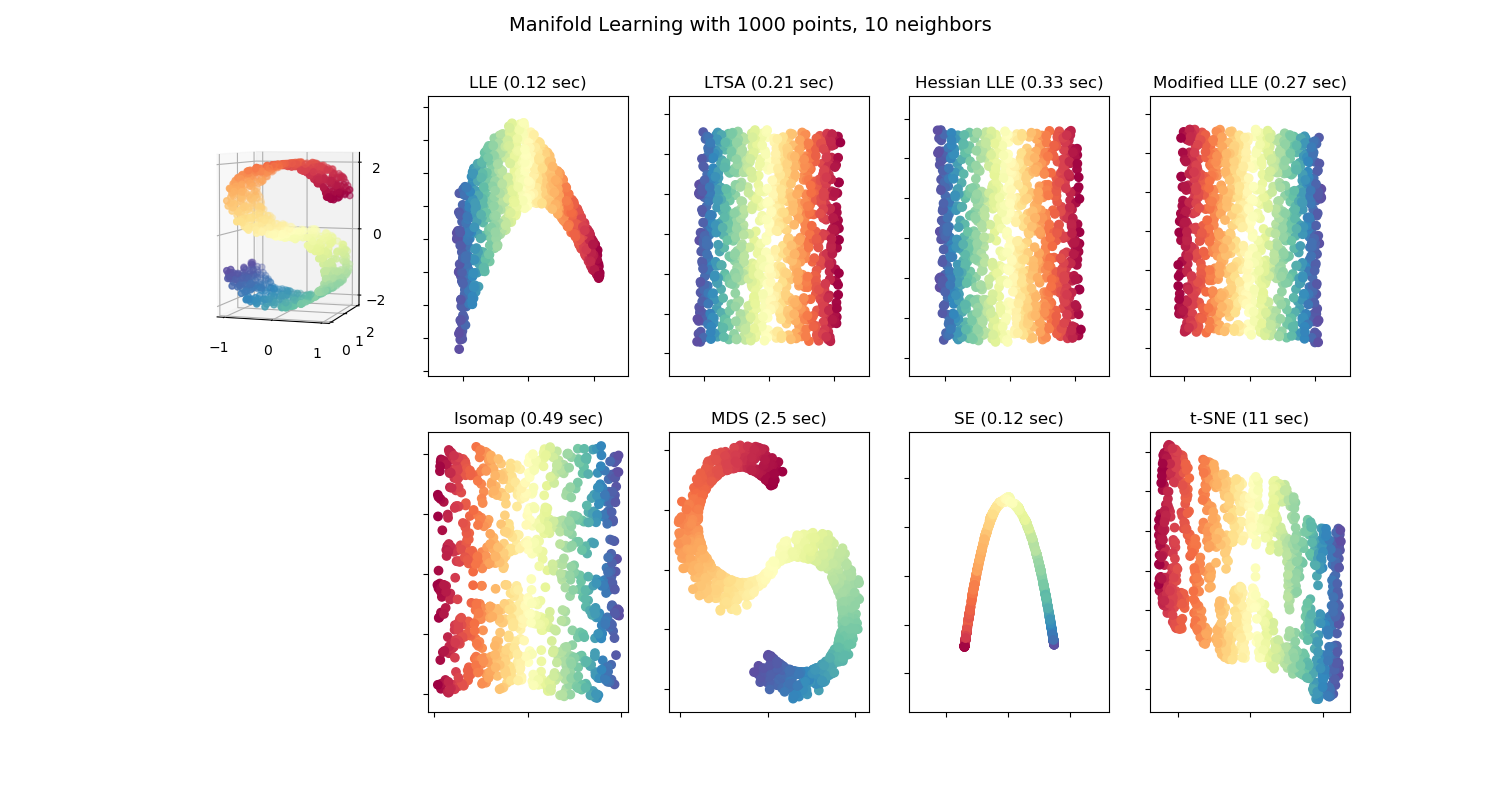
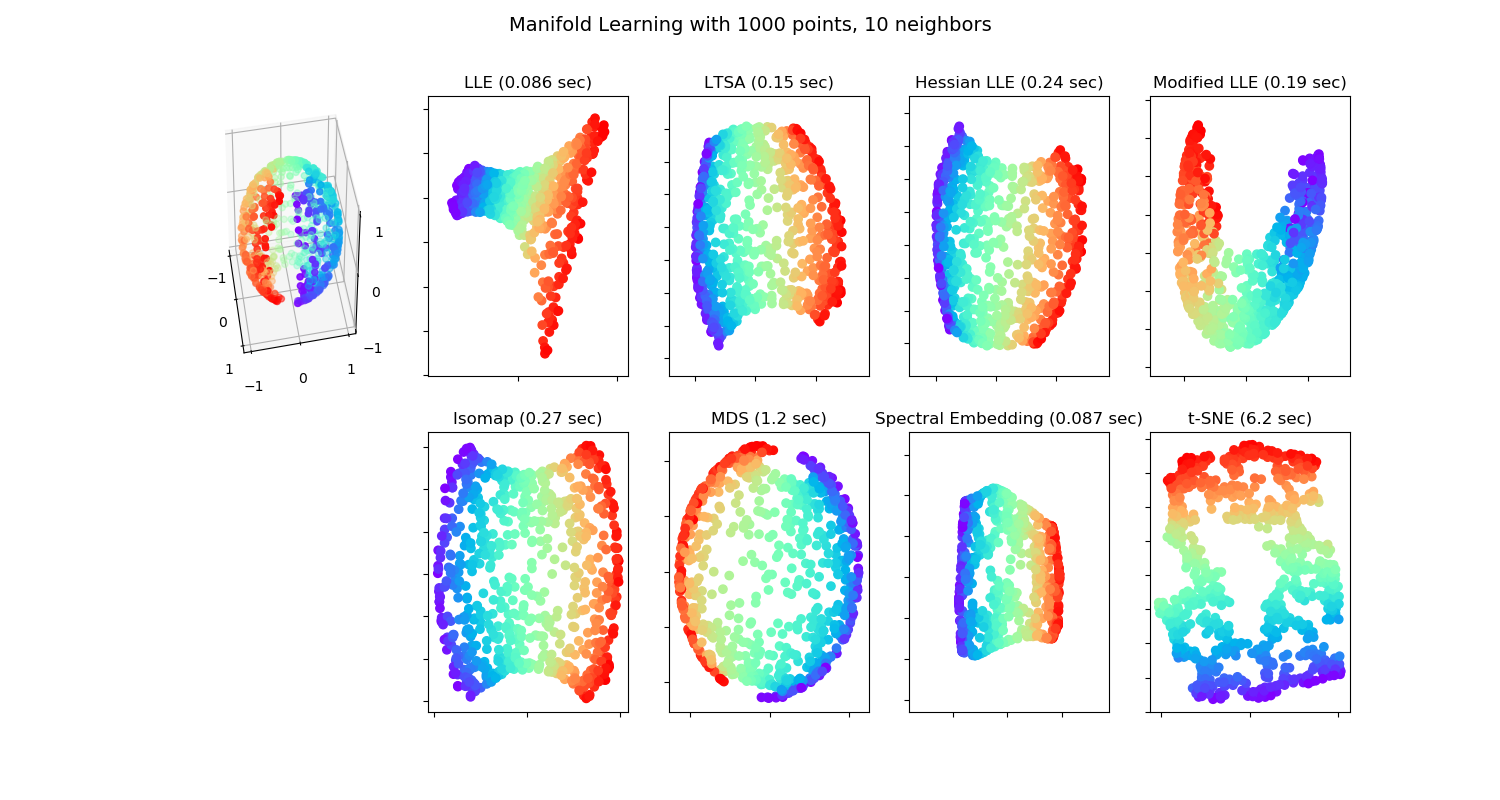
sklearn.manifold.LocallyLinearEmbedding?
class sklearn.manifold.LocallyLinearEmbedding(*, n_neighbors=5, n_components=2, reg=0.001, eigen_solver='auto', tol=1e-06, max_iter=100, method='standard', hessian_tol=0.0001, modified_tol=1e-12, neighbors_algorithm='auto', random_state=None, n_jobs=None)
[源碼]
局部線性嵌入
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| n_neighbors | integer 每個點要考慮的鄰居數量。 |
| n_components | integer 流形的坐標數 |
| reg | float 正則化常數,乘以距離的局部協方差矩陣的軌跡。 |
| eigen_solver | string, {‘auto’, ‘arpack’, ‘dense’} 自動:算法將嘗試為輸入數據選擇最佳方法 |
| arpack | use arnoldi iteration in shift-invert mode. 對于此方法,M可以是稠密矩陣,稀疏矩陣或一般線性式子。警告:由于某些問題,ARPACK可能不穩定。最好嘗試幾個隨機種子以檢查結果。 |
| dense | use standard dense matrix operations for the eigenvalue 分解。對于此方法,M必須為數組或矩陣類型。對于大問題應避免使用此方法。 |
| tol | float, optional 如果eigen_solver==’dense’,則不使用“arpack”方法的容差。 |
| max_iter | integer arpack求解器的最大迭代次數。如果eigen_solver =='dense',則不使用。 |
| method | string (‘standard’, ‘hessian’, ‘modified’ or ‘ltsa’) |
| standard | use the standard locally linear embedding algorithm. see 參考參考文獻[1] |
| hessian | use the Hessian eigenmap method. This method requiresn_neighbors > n_components * (1 + (n_components + 1) / 2參見參考文獻[2] |
| modified | use the modified locally linear embedding algorithm. 參見參考文獻[3] |
| ltsa | use local tangent space alignment algorithm 參見參考文獻[4] |
| hessian_tol | float, optional Hessian特征映射方法的公差。僅在 method == 'hessian'這種情況下使用 |
| modified_tol | float, optional 修正的LLE方法的公差。僅在 method == 'hessian'這種情況下使用 |
| neighbors_algorithm | string [‘auto’,’brute’,’kd_tree’,’ball_tree’] 用于最近鄰居搜索的算法,傳遞給鄰居。NearestNeighbors實例 |
| random_state | int, RandomState instance, default=None 當 eigen_solver=='arpack' 時確定隨機數生成器 。在多個函數調用之間傳遞int以獲得可重復的結果。請參閱:term: Glossary <random_state>. |
| n_jobs | int or None, optional (default=None) 用于進行計算的CPU數量。 None除非在joblib.parallel_backend環境中,否則表示1 。 undefined表示使用所有處理器。有關更多詳細信息,請參見詞匯表。 |
| 屬性 | 說明 |
|---|---|
| embedding_ | array-like, shape [n_samples, n_components] 存儲嵌入向量 |
| reconstruction_error_ | float 與重建相關的錯誤 embedding_ |
| nbrs_ | NearestNeighbors object 存儲最近的鄰居實例,包括BallTree或KDtree(如果適用)。 |
參考文獻
1 Roweis, S. & Saul, L. Nonlinear dimensionality reduction by locally linear embedding. Science 290:2323 (2000).
2 Donoho, D. & Grimes, C. Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. Proc Natl Acad Sci U S A. 100:5591 (2003).
3 Zhang, Z. & Wang, J. MLLE: Modified Locally Linear Embedding Using Multiple Weights. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.70.382
4 Zhang, Z. & Zha, H. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment. Journal of Shanghai Univ. 8:406 (2004)
實例
>>> from sklearn.datasets import load_digits
>>> from sklearn.manifold import LocallyLinearEmbedding
>>> X, _ = load_digits(return_X_y=True)
>>> X.shape
(1797, 64)
>>> embedding = LocallyLinearEmbedding(n_components=2)
>>> X_transformed = embedding.fit_transform(X[:100])
>>> X_transformed.shape
(100, 2)
| 方法 | 說明 |
|---|---|
fit(X[, y]) |
計算數據X的嵌入向量 |
fit_transform(X[, y]) |
計算數據X的嵌入向量并變換X。 |
get_params([deep]) |
獲取此估計量的參數。 |
set_params(**params) |
設置此估算量的參數。 |
transform(X) |
將新點轉換為嵌入空間。 |
__init__(*, n_neighbors=5, n_components=2, reg=0.001, eigen_solver='auto', tol=1e-06, max_iter=100, method='standard', hessian_tol=0.0001, modified_tol=1e-12, neighbors_algorithm='auto', random_state=None, n_jobs=None)
[源碼]
初始化self, 請參閱help(type(self))以獲得準確的說明。
fit(X, y=None)
[源碼]
計算數據X的嵌入向量
| 參數 | 說明 |
|---|---|
| X | array-like of shape [n_samples, n_features] 訓練集。 |
| y | Ignored |
| 返回值 | 說明 |
|---|---|
| self | returns an instance of self. |
fit_transform(X, y=None)
[源碼]
計算數據X的嵌入向量并變換X。
| 參數 | 說明 |
|---|---|
| X | array-like of shape [n_samples, n_features] 訓練集。 |
| y | Ignored |
| 返回值 | 說明 |
|---|---|
| X_new | array-like, shape (n_samples, n_components) |
get_params(deep=True)
[源碼]
獲取此估計量的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算量和作為估算量的所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 映射到其值的參數名。 |
set_params(**params)
[源碼]
設置此估算量的參數。
該方法適用于簡單估計量以及嵌套對象(例如pipelines)。后者具有形式的參數。<component>__<parameter>以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估算量參數。 |
| 返回值 | |
|---|---|
| self | object 估算量實例。 |
transform(X)
[源碼]
將新點轉換為嵌入空間。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) |
| 返回值 | 說明 |
|---|---|
| X_new | array, shape = [n_samples, n_components] |
注
由于此方法執行縮放,因此不建議將其與非縮放不變的方法(例如SVM)一起使用.