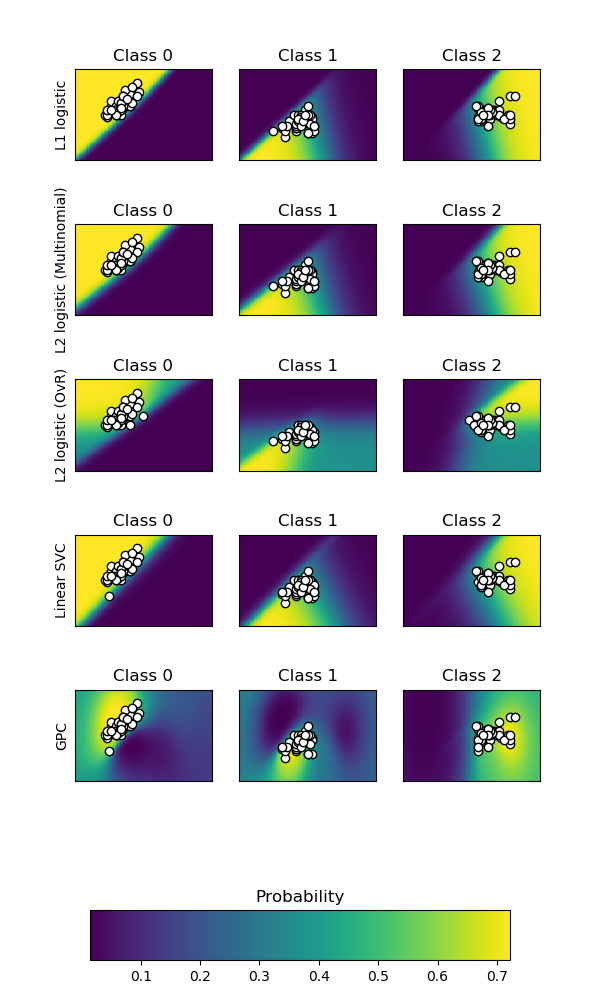
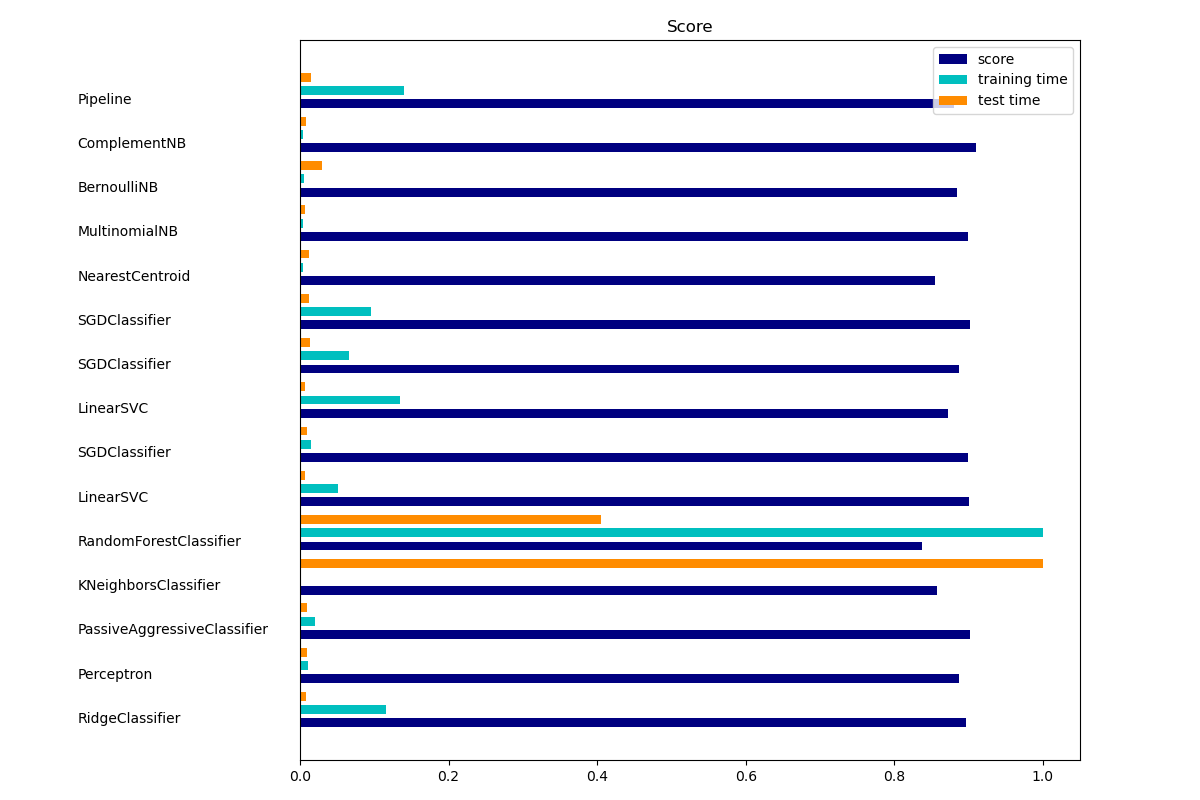
sklearn.metrics.accuracy_score?
sklearn.metrics.accuracy_score(y_true, y_pred, *, normalize=True, sample_weight=None)
精度分類得分。
在多標簽分類中,此函數計算子集準確性:為樣本預測的標簽集必須與y_true中的相應標簽集完全匹配。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| y_true | 1d array-like, or label indicator array / sparse matrix 真實標簽。 |
| y_pred | 1d array-like, or label indicator array / sparse matrix 預測標簽,由分類器返回。 |
| normalize | bool, optional (default=True) 如果為False,則返回正確分類的樣本數。否則,返回正確分類的樣本的分數。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重。 |
| 返回值 | 說明 |
|---|---|
| score | float 如果normalize == True,則返回正確分類的樣本的分數(浮點數),否則返回正確分類的樣本數(整數)。 最佳性能,在normalize == True時,為1;在normalize == False時,為樣本數量。 |
另見
注
在二進制和多類分類中,此函數等同于jaccard_score函數。
示例
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0, 2, 1, 3]
>>> y_true = [0, 1, 2, 3]
>>> accuracy_score(y_true, y_pred)
0.5
>>> accuracy_score(y_true, y_pred, normalize=False)
2
在帶有二進制標簽指示符的多標簽情況下:
>>> import numpy as np
>>> accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2)))
0.5