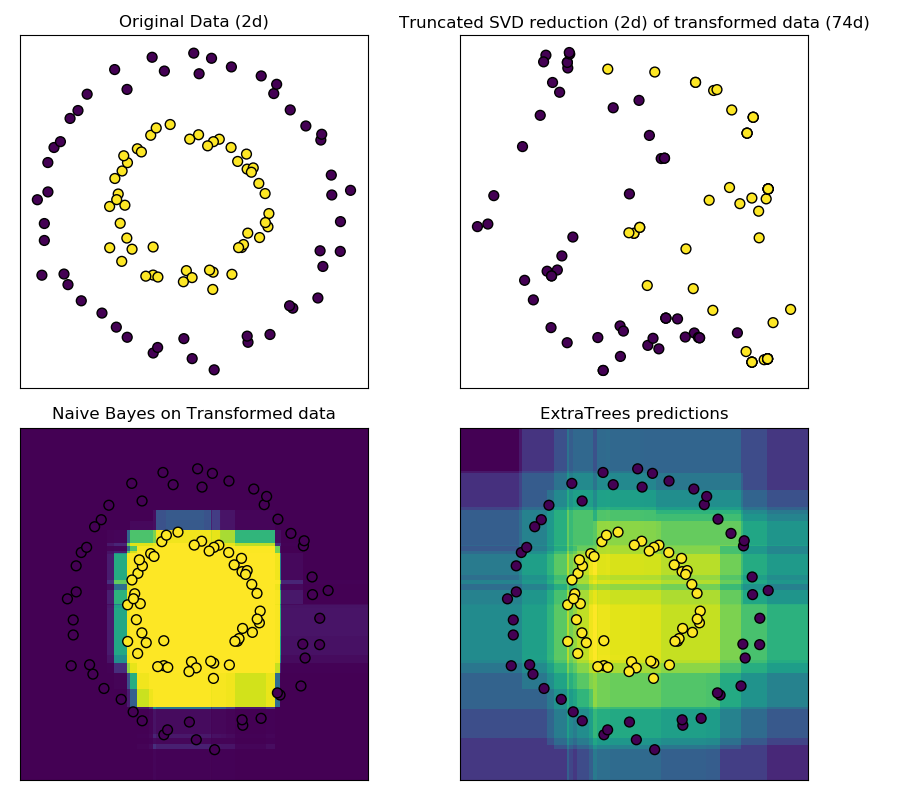
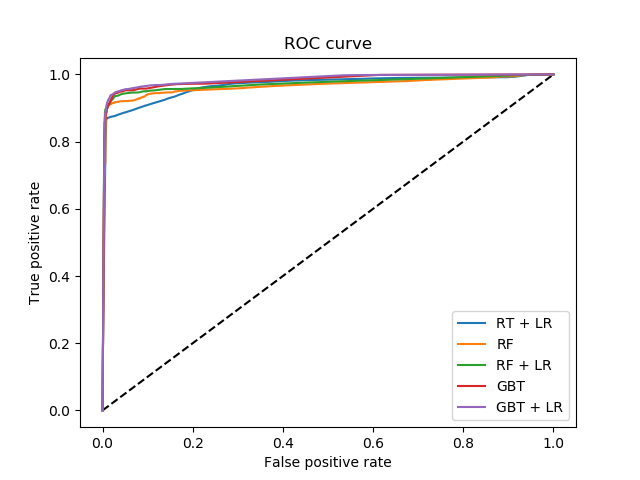
sklearn.ensemble.RandomTreesEmbedding?
class sklearn.ensemble.RandomTreesEmbedding(n_estimators=100, *, max_depth=5, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, sparse_output=True, n_jobs=None, random_state=None, verbose=0, warm_start=False)
完全隨機樹的集成。
數據集到高維稀疏表示的無監督轉換。數據點是根據它被分類到的每棵樹的相應葉中來編碼的。使用one-hot編碼的葉子,這將導致二進制編碼的數量與森林中的樹一樣多。
結果表示的維數為n_out <= n_estimators * max_leaf_nodes。如果max_leaf_nodes == None,則葉節點的數量最多為n_estimators * 2 ** max_depth。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| n_estimators | int, default=100 森林中樹木的數量。 在版本0.22中更改:默認值 n_estimators在0.22中從10更改為100。 |
| max_depth | int, default=None 樹的最大深度。如果為None,則將節點展開,直到所有葉子都是純凈的,或者直到所有葉子都包含少于min_samples_split個樣本。 |
| min_samples_split | int or float, default=2 分割一個內部節點所需的最小樣本數: - 如果為int,則認為 min_samples_leaf是最小值。- 如果為float, min_samples_leaf則為分數, 是每個節點的最小樣本數。ceil(min_samples_leaf * n_samples)在版本0.18中更改:添加了分數的浮點值。 |
| min_samples_leaf | int or float, default=1 一個葉節點上所需的最小樣本數。只有當它在每個左右分支中都留下至少min_samples_leaf訓練樣本時,任何深度的分割點才會被考慮。這可能會產生平滑模型的效果,特別是在回歸中。 - 如果為int,則認為 min_samples_leaf是最小值。- 如果為float, min_samples_leaf則為分數, 是每個節點的最小樣本數。ceil(min_samples_leaf * n_samples)在版本0.18中更改:添加了分數的浮點值。 |
| min_weight_fraction_leaf | float, default=0.0 一個葉節點上所需的(所有輸入樣本的)總權重的最小加權分數。當不提供 sample_weight時,樣本的權重相等。 |
| max_leaf_nodes | int, default=Nonemax_leaf_nodes以最好的方式進行“種樹”。雜質的相對減少的節點被當作最佳節點。如果為None,則葉節點數不受限制。 |
| min_impurity_decrease | float, default=0.0 如果節點分裂會導致雜質的減少大于或等于該值,則該節點將被分裂。 加權減少雜質的方程式如下: N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)其中, N是樣本總數,N_t是當前節點上N_t_L的樣本數,是左子節點中的樣本N_t_R數,是右子節點中的樣本數。N,N_t,N_t_R并且N_t_L都指的是加權和,如果sample_weight獲得通過。版本0.19中的新功能。 |
| min_impurity_split | float, default=None 樹提升提前停止的閾值。如果節點的雜質高于閾值,則該節點將分裂,否則為葉。 - 從版本0.19 min_impurity_split開始不推薦使用:在版本0.19中不再推薦使用 min_impurity_decrease。的默認值 min_impurity_split在0.23中從1e-7更改為0,并將在0.25中刪除。使用min_impurity_decrease代替。 |
| sparse_output | bool, default=False 是否返回稀疏CSR矩陣(默認行為),或返回與密集管道操作符兼容的密集數組。 |
| n_jobs | int, default=None 要并行運行的作業的數量。 fit, predict, decision_path 和 apply都在樹中并行化。除非在一個joblib.parallel_backend的內容中,否則None在joblib中的表示是1。-1表示使用所有處理器。有關更多詳細信息,請參見Glossary。 |
| random_state | int, RandomState, default=None 控制用于擬合樹的隨機 y的生成,以及繪制分割樹節點上每個特征。有關更多詳細信息,請參見Glossary。 |
| verbose | int, default=0 在擬合和預測時控制冗余程度。 |
| warm_start | bool, default=False 當設置為 True時,重用前面調用的解決方案來適應并向集成添加更多的評估器,否則,只會擬合完整的新森林。有關更多詳細信息,請參見Glossary。 |
| 屬性 | 說明 |
|---|---|
| estimators_ | list of DecisionTreeRegressor 擬合的子估計器的集合。 |
參考文獻
P. Geurts, D. Ernst., and L. Wehenkel, “Extremely randomized trees”, Machine Learning, 63(1), 3-42, 2006.
Moosmann, F. and Triggs, B. and Jurie, F. “Fast discriminative visual codebooks using randomized clustering forests” NIPS 2007
實例
>>> from sklearn.ensemble import RandomTreesEmbedding
>>> X = [[0,0], [1,0], [0,1], [-1,0], [0,-1]]
>>> random_trees = RandomTreesEmbedding(
... n_estimators=5, random_state=0, max_depth=1).fit(X)
>>> X_sparse_embedding = random_trees.transform(X)
>>> X_sparse_embedding.toarray()
array([[0., 1., 1., 0., 1., 0., 0., 1., 1., 0.],
[0., 1., 1., 0., 1., 0., 0., 1., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 1., 0., 1., 0., 0., 1., 1., 0.]])
方法
| 方法 | 說明 |
|---|---|
apply(X) |
將森林中的樹應用于X,返回葉索引。 |
decision_path(X) |
返回森林的決策路徑。 |
fit(X[, y, sample_weight]) |
擬合估計器。 |
fit_transform(X[, y, sample_weight]) |
擬合估計器和變換數據集。 |
get_params([deep]) |
獲取這個估計器的參數。 |
set_params(**params) |
設置這個估計器的參數。 |
transform(X) |
轉化數據集。 |
__init__(n_estimators=100, *, max_depth=5, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, sparse_output=True, n_jobs=None, random_state=None, verbose=0, warm_start=False)
初始化self。有關準確的簽名,請參見help(type(self))。
apply(X)
將森林中的樹應用于X,返回葉子索引。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 輸入樣本。在內部,它的 dtype將被轉換為dtype=np.float32。如果提供了一個稀疏矩陣,它將被轉換為一個csr_matrix。 |
| 返回值 | 說明 |
|---|---|
| X_leaves | ndarray of shape (n_samples, n_estimators) 對于X中的每個數據點x和森林中的每棵樹,返回x最終所在的葉子的索引。 |
decision_path(X)
返回森林中的決策路徑。
版本0.18中的新功能。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 輸入樣本。在內部,它的 dtype將被轉換為dtype=np.float32。如果提供了一個稀疏矩陣,它將被轉換為一個csr_matrix。 |
| 返回值 | 說明 |
|---|---|
| indicator | sparse matrix of shape (n_samples, n_nodes) 返回一個節點指示符矩陣,其中非零元素表示樣本經過節點。矩陣為CSR格式。 |
| n_nodes_ptr | ndarray of shape (n_estimators + 1,) 列元素來自指示符 [n_nodes_ptr[i]:n_nodes_ptr[i+1]]給出第i個估計器的指示值。 |
property feature_importances_
基于雜質的功能的重要性。
越高,功能越重要。特征的重要性計算為該特征帶來的標準的(標準化)總縮減。這也被稱為基尼重要性。
警告:基于雜質的特征重要性可能會誤導高基數特征(許多唯一值)。另見 sklearn.inspection.permutation_importance。
| 返回值 | 說明 |
|---|---|
| feature_importances_ | ndarray of shape (n_features,) 除非所有樹都是僅由根節點組成的單節點樹,否則此數組的值總計為1,在這種情況下,它將是零數組。 |
fit(X, y, sample_weight = None)
擬合估計器。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 輸入樣本。在內部,它的 dtype將被轉換為dtype=np.float32。如果提供了一個稀疏矩陣,它將被轉換為一個csr_matrix。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) 目標值(分類中的類標簽,回歸中的實數)。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重。如果沒有,那么樣本的權重相等。當在每個節點中搜索分割時,將忽略創建具有凈零權值或負權值的子節點的分割。在分類的情況下,如果分割會導致任何一個類在任一子節點中具有負權值,那么分割也將被忽略。 |
| 返回值 | 說明 |
|---|---|
| self | object |
fit_transform(X, y=None, sample_weight=None)
擬合估計量和變換數據集。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 輸入樣本。在內部,它的 dtype將被轉換為dtype=np.float32。如果提供了一個稀疏矩陣,它將被轉換為一個csr_matrix。 |
| y | Ignored 未使用,按照約定呈現API一致性。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重。如果沒有,那么樣本的權重相等。當在每個節點中搜索分割時,將忽略創建具有凈零權值或負權值的子節點的分割。在分類的情況下,如果分割會導致任何一個類在任一子節點中具有負權值,那么分割也將被忽略。 |
| 返回值 | 說明 |
|---|---|
| X_transformed | sparse matrix of shape (n_samples, n_out) 轉化后的數據集。 |
get_params(deep=True)
得到估計器的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default = True 如果為真,將返回此估計量的參數以及包含作為估計量的子對象。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 名稱參數及他們所映射的值。 |
set_params(**params)
設置該估計器的參數。
該方法適用于簡單估計器和嵌套對象(如pipline)。后者具有形式為<component>_<parameter>的參數,這樣就可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估計器參數 |
| 返回值 | 說明 |
|---|---|
| self | object 估計實例。 |
transform(X)
轉化數據集。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 輸入樣本。在內部,它的 dtype將被轉換為dtype=np.float32。如果提供了一個稀疏矩陣,它將被轉換為一個csr_matrix。 |
| 返回值 | 說明 |
|---|---|
| X_transformed | sparse matrix of shape (n_samples, n_out) 轉化后的數據集 |