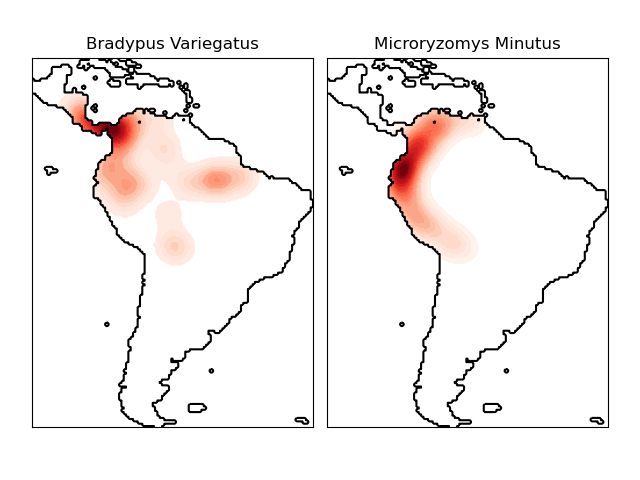
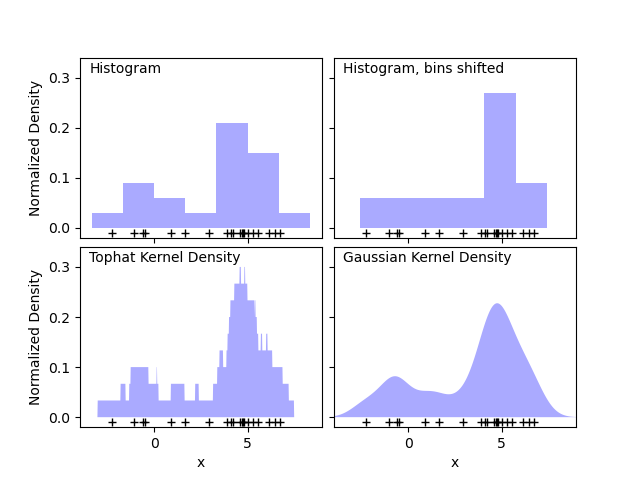
sklearn.neighbors.KernelDensity?
lass sklearn.neighbors.KernelDensity(*, bandwidth=1.0, algorithm='auto', kernel='gaussian', metric='euclidean', atol=0, rtol=0, breadth_first=True, leaf_size=40, metric_params=None)
[源碼]
內核密度估計。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| bandwidth | float 內核的帶寬。 |
| algorithm | str 要使用的樹算法。 有效選項為[‘kd_tree’,ball_tree',‘auto'],默認的是'auto'. |
| kernel | str 要使用的內核。 有效內核為['gaussian',’tophat',’epanechnikov’,’exponential',’linear’,’cosine’],默認的是‘gaussian’. |
| metric | str 使用的距離度量。 請注意,并非所有指標對所有算法都有效。 有關可用算法的描述,請參考BallTree和KDTree的文檔。 請注意,密度輸出的歸一化僅對于歐幾里得距離度量是正確的。 默認值為“歐幾里得”。 |
| atol | float 結果的所需絕對公差。 較大的公差通常會導致執行速度更快。 默認值為0。 |
| rtol | float 結果的所需相對公差。 較大的公差通常會導致執行速度更快。 默認值為1E-8。 |
| breadth_first | bool 如果為true(默認值),請使用廣度優先的方法來解決問題。 否則,請使用深度優先的方法。 |
| leaf_size | int 指定基礎樹的葉大小。 有關詳細信息,請參見BallTree或KDTree。 默認值為40。 |
| metric_params | dict 要傳遞給樹以用于度量標準的其他參數。 有關更多信息,請參見BallTree或KDTree的文檔。 |
另見
快速廣義N點問題的K-dimensional tree。
快速廣義N點問題的球樹。
示例
用固定帶寬計算高斯核密度估計。
>>> import numpy as np
>>> rng = np.random.RandomState(42)
>>> X = rng.random_sample((100, 3))
>>> kde = KernelDensity(kernel=’gaussian’, bandwidth=0.5).fit(X)
>>> log_density = kde.score_samples(X[:3])
>>> log_density
array([-1.52955942, -1.51462041, -1.60244657])
方法
| 方法 | 說明 |
|---|---|
fit(, X[, y, sample_weight]) |
在數據上擬合核密度模型。 |
get_params([deep]) |
獲取此估計量的參數。 |
sample([,n_samples, random_state]) |
從模型生成隨機樣本。 |
score(X[, y]) |
計算模型下的總對數概率密度。 |
score_samples(X) |
在數據上評估對數密度模型。 |
set_params( **params) |
設置此估算器的參數。 |
__init__( *, bandwidth=1.0, algorithm='auto', kernel='gaussian', metric='euclidean', atol=0, rtol=0, breadth_first=True, leaf_size=40, metric_params=None)
初始化. 請參閱help(type(self))以獲得準確的說明。
fit(X, y=None, sample_weight=None)
在數據上擬合核密度模型。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) n_features維數據點列表。 每行對應一個數據點。 |
| y | None 忽略。 僅存在此參數是為了與sklearn.pipeline.Pipeline兼容。 |
| sample_weight | array_like, shape (n_samples,), optional) 數據X附帶的樣本權重列表。 0.20版中的新功能。 |
| 返回值 | 說明 |
|---|---|
| self | object 返回對象的實例。 |
get_params(deep=True)
獲取此估計量的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和作為估算器的所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
sample( n_samples=1, random_state=None)
從模型生成隨機樣本。
當前,這僅適用于高斯和高帽內核。
| 參數 | 說明 |
|---|---|
| n_samples | int, optional 要生成的樣本數。 默認為1。 |
| random_state | int, RandomState instance, default=None 確定用于生成隨機樣本的隨機數生成。 在多個函數調用之間傳遞int以獲得可重復的結果。 參見:term:詞匯表<random_state>。 |
| 返回值 | 說明 |
|---|---|
| X | array_like, shape (n_samples, n_features) 樣本列表。 |
score(, X, y=None)
計算模型下的總對數概率密度。
| 參數 | 說明 |
|---|---|
| X | array_like, shape (n_samples, n_features) n_features維數據點列表。 每行對應一個數據點。 |
| y | None 忽略。僅存在此參數是為了與sklearn.pipeline.Pipeline兼容 |
| 返回值 | 說明 |
|---|---|
| logprob | float X中數據的總對數似然性。這被歸一化為概率密度,因此對于高維數據,該值將較低。 |
score_samples(X)
在數據上評估對數密度模型。
| 參數 | 說明 |
|---|---|
| X | array_like, shape (n_samples, n_features) 要查詢的點數組。 最后維度應與訓練數據的維度(n_features)相匹配。 |
| 返回值 | 說明 |
|---|---|
| density | ndarray, shape (n_samples,) 對數(密度)評估值的數組。 這些被歸一化為概率密度,因此對于高維數據,值將較低。 |
set_params(**params)
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。 后者的參數格式為
| 參數 | 說明 |
|---|---|
| **params | dict 估算器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估算器實例。 |