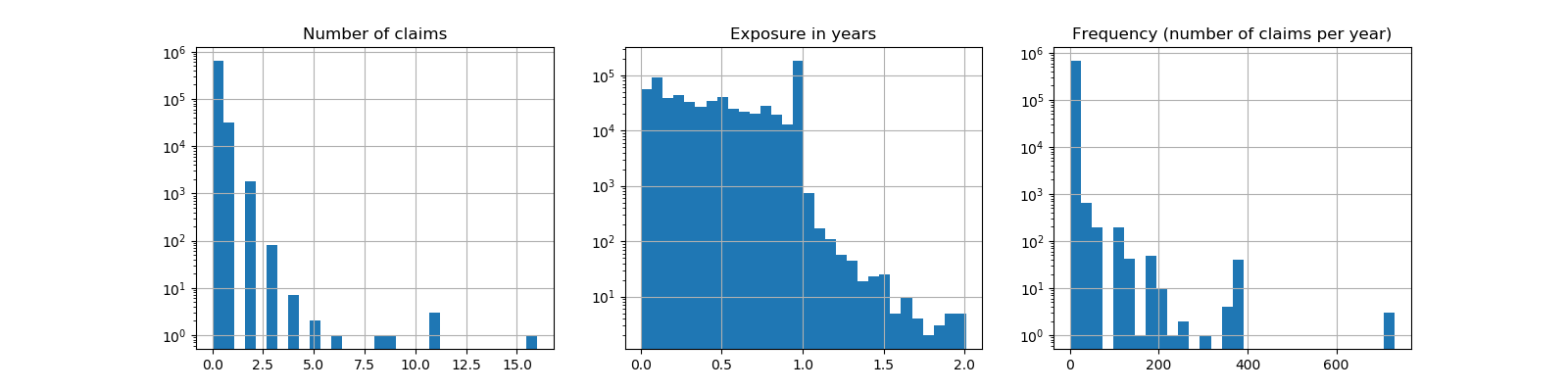
sklearn.preprocessing.OrdinalEncoder?
class sklearn.preprocessing.OrdinalEncoder(*, categories='auto', dtype=<class 'numpy.float64'>)
將分類特征編碼為整數數組。
該轉換器的輸入應為整數或字符串之類的數組,表示分類(離散)特征所采用的值。要素將轉換為序數整數。這將導致每個要素的一列整數(0到n_categories-1)。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| categories | ‘auto’ or a list of array-like, default=’auto’ 每個功能的類別(唯一值): ‘auto’:根據訓練數據自動確定類別。 list:category [i]保存第i列中預期的類別。傳遞的類別不應將字符串和數字值混合使用,并且在使用數字值時應進行排序。 使用的類別可以在category_屬性中找到。 |
| dtype | number type, default np.float64 所需的輸出dtype。 |
| 屬性 | 說明 |
|---|---|
| categories_ | list of arrays 擬合期間確定的每個特征的類別(按X中特征的順序,并與轉換的輸出相對應)。 |
另見:
sklearn.preprocessing.OneHotEncoder
對分類特征執行一鍵編碼。
sklearn.preprocessing.LabelEncoder
使用0到n_classes-1之間的值對目標標簽進行編碼。
示例
給定具有兩個特征的數據集,我們讓編碼器找到每個特征的唯一值,然后將數據轉換為序數編碼。
>>> from sklearn.preprocessing import OrdinalEncoder
>>> enc = OrdinalEncoder()
>>> X = [['Male', 1], ['Female', 3], ['Female', 2]]
>>> enc.fit(X)
OrdinalEncoder()
>>> enc.categories_
[array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)]
>>> enc.transform([['Female', 3], ['Male', 1]])
array([[0., 2.],
[1., 0.]])
>>> enc.inverse_transform([[1, 0], [0, 1]])
array([['Male', 1],
['Female', 2]], dtype=object)
方法
| 方法 | 說明 |
|---|---|
fit(X[, y]) |
使OrdinalEncoder擬合X。 |
fit_transform(X[, y]) |
擬合數據,然后對其進行轉換。 |
get_params([deep]) |
獲取此估計量的參數。 |
inverse_transform(X) |
將數據轉換回原始表示形式。 |
set_params(**params) |
設置此估算器的參數。 |
transform(X) |
將X轉換為序數代碼。 |
__init__(*, categories='auto', dtype=<class 'numpy.float64'>)
初始化self,有關準確的簽名,請參見help(type(self))。
fit(X, y=None)
| 參數 | 說明 |
|---|---|
| X | array-like, shape [n_samples, n_features] 該數據確定每個功能的類別。 |
| y | None 忽略。僅存在此參數是為了與 sklearn.pipeline.Pipeline兼容。 |
| 返回值 | 說明 |
|---|---|
| self | - |
fit_transform(X, y=None, **fit_params)
擬合數據,然后對其進行轉換。
使用可選參數fit_params將轉換器擬合到X和y,并返回X的轉換版本。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目標值。 |
| **fit_params | dict 其他擬合參數。 |
| 返回值 | 說明 |
|---|---|
| X_new | ndarray array of shape (n_samples, n_features_new) 轉換后的數組。 |
get_params(deep=True)
獲取此估計量的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和作為估算器的所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
inverse_transform(X)
將數據轉換回原始表示形式。
| 參數 | 說明 |
|---|---|
| X | array-like or sparse matrix, shape [n_samples, n_encoded_features] 轉換后的數據。 |
| 返回值 | 說明 |
|---|---|
| X_tr | array-like, shape [n_samples, n_features] 逆變換數組。 |
set_params(**params)
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。后者的參數形式為<component>__<parameter>這樣就可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估算器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估算器實例。 |
transform(X)
將X轉換為序數代碼。
| 參數 | 說明 |
|---|---|
| X | array-like, shape [n_samples, n_features] 要編碼的數據。 |
| 返回值 | 說明 |
|---|---|
| X_out | sparse matrix if sparse=True else a 2-d array 轉換后的輸入。 |