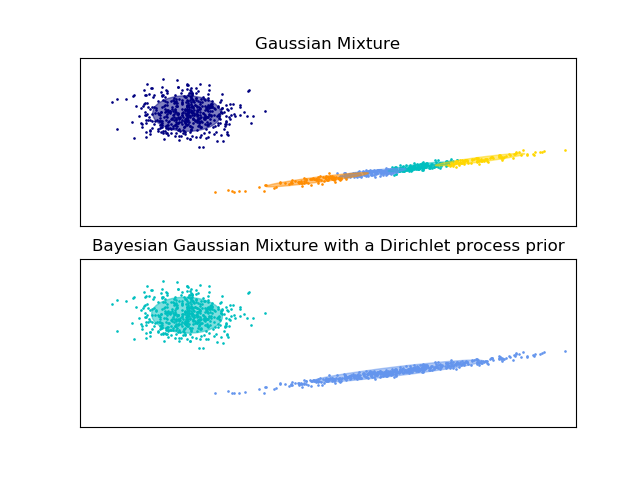
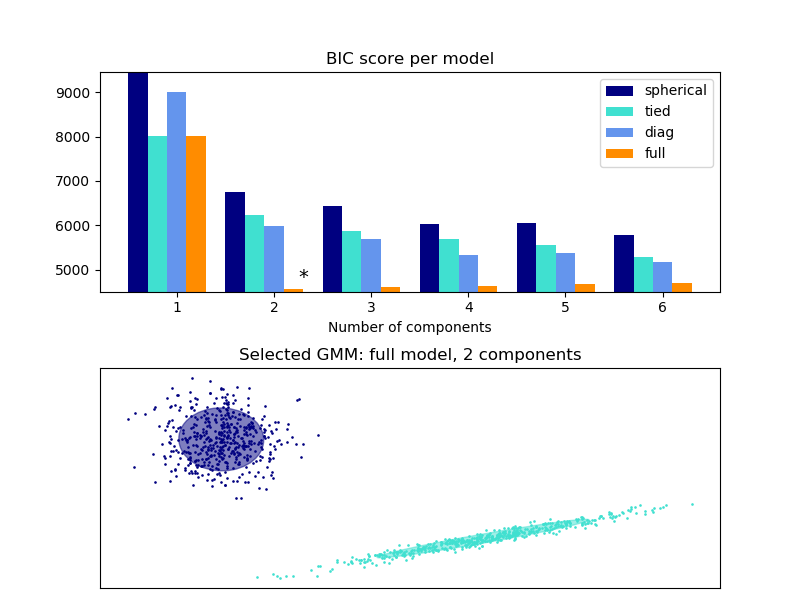
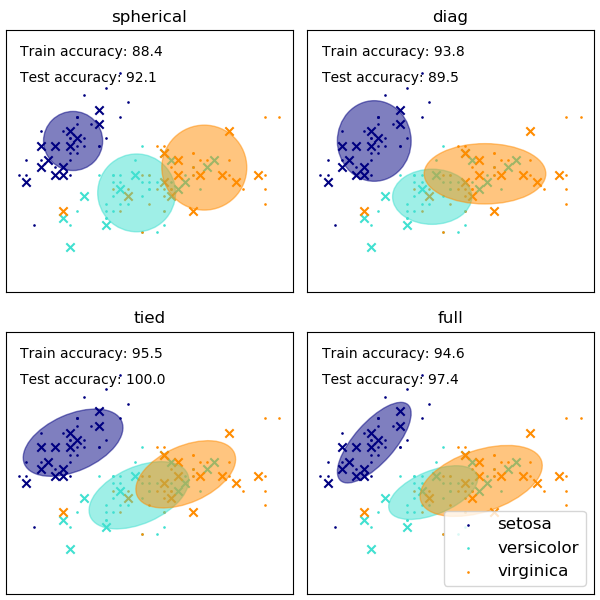
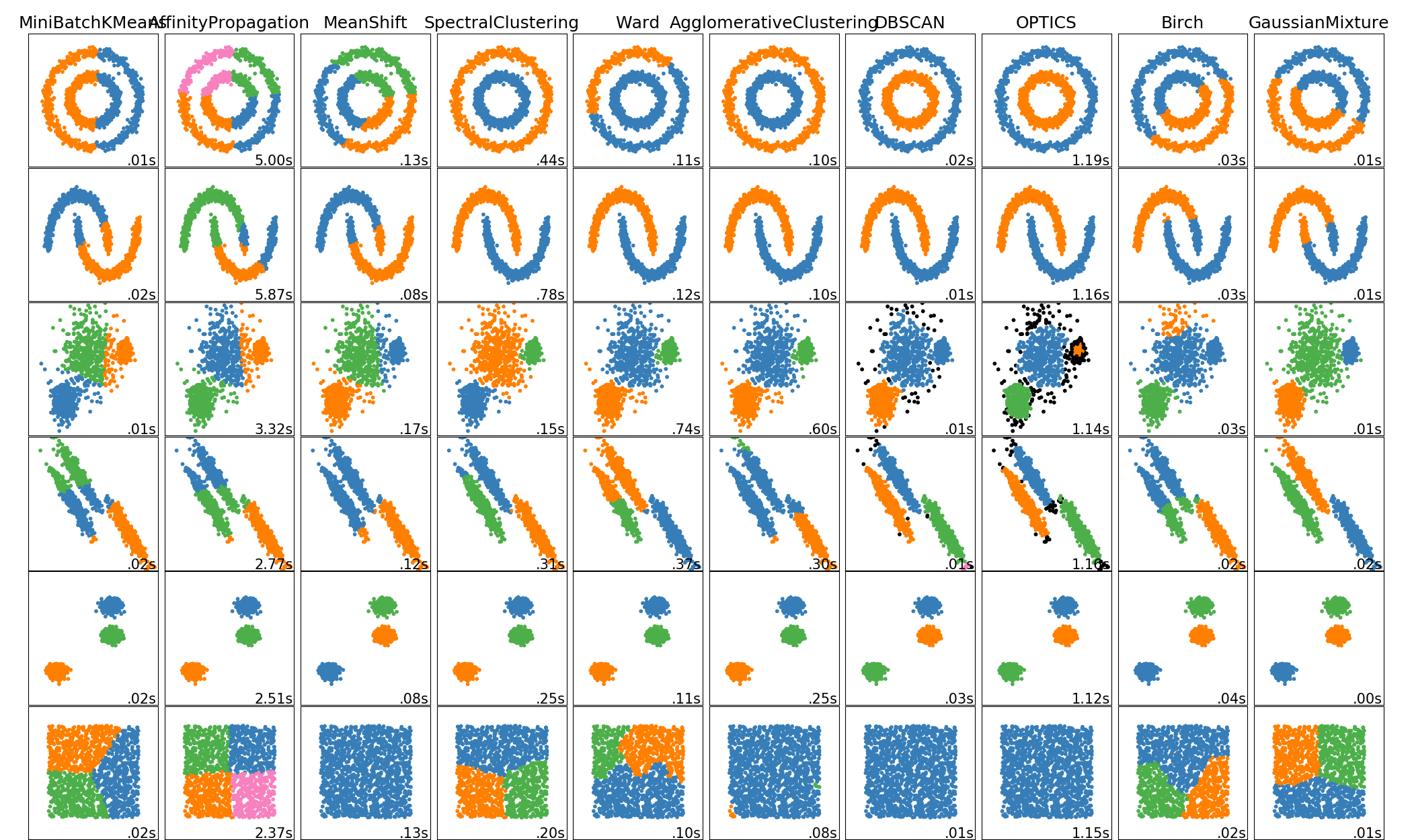
sklearn.mixture.GaussianMixture?
class sklearn.mixture.GaussianMixture`(*n_components=1, *, covariance_type='full', tol=0.001, reg_covar=1e-06,max_iter=100,n_init=1,init_params='kmeans', weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False,verbose=0, verbose_interval=10)
[源碼]
高斯混合。
高斯混合模型概率分布的表示。此類允許估計高斯混合分布的參數。
在用戶指南中閱讀更多內容。
版本0.18中的新功能。
| 參數 | 說明 |
|---|---|
| n_components | int, defaults to 1. 混合元素的數量。 |
| covariance_type | {‘full’ (default), ‘tied’, ‘diag’, ‘spherical’} 描述要使用的協方差參數類型的字符串。必須是以下之一: ‘full’ 每個分量都有自己的協方差矩陣 ‘tied’ 所有分量共享相同的通用協方差矩陣 ‘diag’ 每個分量都有自己的對角協方差矩陣 ‘spherical’ 每個組件都有其自己的單個方差 |
| tol | float, defaults to 1e-3. 收斂閾值。當下限平均增益低于此閾值時,EM迭代將停止。 |
| reg_covar | float, defaults to 1e-6. 非負正則化添加到協方差的對角線上。允許確保協方差矩陣均為正。 |
| max_iter | int, defaults to 100. 要執行的EM迭代次數。 |
| n_init | int, defaults to 1. 要執行的初始化次數。保持最佳結果。 |
| init_params | {‘kmeans’, ‘random’}, defaults to ‘kmeans’. 用于初始化權重,均值和精度的方法。必須是以下之一: 'kmeans' : responsibilities are initialized using kmeans. 'random' : responsibilities are initialized randomly. |
| weights_init | array-like, shape (n_components, ), optional 用戶提供的初始權重,默認為None。如果為None,則使用 init_params方法初始化權重。 |
| means_init | array-like, shape (n_components, n_features), optional 用戶提供的初始均值,默認為None,如果為None,則使用 init_params方法初始化均值。 |
| precisions_init | array-like, optional. 用戶提供的初始精度(協方差矩陣的倒數),默認為None。如果為None,則使用'init_params'方法初始化精度。形狀取決于'covariance_type': (n_components,) if 'spherical',(n_features, n_features) if 'tied',(n_components, n_features) if 'diag',(n_components, n_features, n_features) if 'full' |
| random_state | int, RandomState instance or None, optional (default=None) 控制分配給用于初始化參數的方法的隨機種子(請參閱參考資料 init_params)。另外,它控制擬合分布中隨機樣本的生成(請參見方法sample)。為多個函數調用傳遞可重復輸出的int值。請參閱詞匯表。 |
| warm_start | bool, default to False. 如果'warm_start'為True,則最后一次擬合的解決方案將用作下一次fit()的初始化。在類似問題上多次調用擬合時,可以加快收斂速度。在這種情況下,“ n_init”將被忽略,并且在第一次調用時僅發生一次初始化。請參閱詞匯表。 |
| verbose | int, default to 0. 啟用詳細輸出。如果為1,則打印當前的初始化和每個迭代步驟。如果大于1,則還將打印對數概率和每個步驟所需的時間。 |
| verbose_interval | int, default to 10. 下一次打印之前完成的迭代次數。 |
| 參數 | 說明 |
|---|---|
| weights_ | array-like, shape (n_components,) 每種混合元素的權重。 |
| means_ | array-like, shape (n_components, n_features) 每種混合元素的平均值。 |
| covariances_ | array-like 每個混合元素的協方差。形狀取決于 covariance_type:(n_components,) if 'spherical',(n_features, n_features) if 'tied',(n_components, n_features) if 'diag',(n_components, n_features, n_features) if 'full' |
| precisions_ | array-like 混合元素中每種成分的精密度矩陣。精度矩陣是協方差矩陣的逆矩陣。協方差矩陣是對稱正定的,因此可以通過精度矩陣等效地對高斯的混合進行參數化。存儲精度矩陣而不是協方差矩陣使在測試時計算新樣本的對數似然更有效率。形狀取決于 covariance_type:(n_components,) if 'spherical',(n_features, n_features) if 'tied',(n_components, n_features) if 'diag',(n_components, n_features, n_features) if 'full' |
| precisions_cholesky_ | array-like 每個混合元素的精確矩陣的cholesky分解。精度矩陣是協方差矩陣的逆矩陣。協方差矩陣是對稱正定的,因此可以通過精度矩陣等效地對高斯的混合進行參數化。存儲精度矩陣而不是協方差矩陣使在測試時計算新樣本的對數似然更有效率。形狀取決于 covariance_type:(n_components,) if 'spherical',(n_features, n_features) if 'tied',(n_components, n_features) if 'diag',(n_components, n_features, n_features) if 'full' |
| converged_ | bool 當在fit()中達到收斂時為true,否則為False。 |
| n_iter_ | int 最適合EM達到收斂的步數。 |
| lower_bound_ | float EM最佳擬合的對數似然(訓練數據相對于模型)的下界值。 |
另見
高斯混合模型具有變分推斷。
| 方法 | 說明 |
|---|---|
aic(X) |
在當前模型上輸入X的Akaike信息準則 |
bic(X) |
在當前模型上輸入X的貝葉斯信息準則。 |
fit(X[, y]) |
用EM算法估計模型參數。 |
fit_predict(X[, y]) |
用X估計模型參數,并預測X的標簽。 |
get_params([deep]) |
獲取這個算法的參數 |
predict(X) |
使用訓練模型預測X中數據樣本的標簽。 |
predict_proba(X) |
在給定數據的情況下,預測每個分量的后驗概率。 |
sample([n_samples]) |
從擬合的高斯分布生成隨機樣本。 |
score(X[, y]) |
計算給定數據X的每個樣本平均log似然函數 |
score_samples(X) |
計算每個樣本的加權log概率。 |
set_params(**params) |
為算法設置參數 |
__init__(n_components=1, *, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)
[源碼]
初始化self, 請參閱help(type(self))以獲得準確的說明。
aic(X)
[源碼]
在當前模型上輸入X的Akaike信息準則
| 參數 | 說明 |
|---|---|
| X | array of shape (n_samples, n_dimensions) |
| 返回值 | 說明 |
|---|---|
| aic | float 越低越好。 |
bic(X)
[源碼]
在當前模型上輸入X的貝葉斯信息準則。
| 參數 | 說明 |
|---|---|
| X | array of shape (n_samples, n_dimensions) |
| 返回值 | 說明 |
|---|---|
| bic | float 越低越好。 |
fit(X, y=None)
[源碼]
該方法擬合模型n_init時間,并設置模型具有最大似然性或下界的參數。在每次試驗中,該方法都會在E步和M步之間迭代一段max_iter 時間,直到似然性或下界的變化小于 tol為止,否則ConvergenceWarning提高a。如果warm_start為True,則將n_init其忽略,并在第一次調用時執行一次初始化。連續運行時,訓練從停下來的地方開始。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) n_features維數據點列表。每行對應一個數據點。 |
| 返回值 | 說明 |
|---|---|
| self |
fit_predict(X, y=None)
[源碼]
使用X估算模型參數并預測X的標簽。
該方法擬合模型n_init次,并設置模型具有最大似然性或下界的參數。在每次試驗中,該方法都會在E步和M步之間迭代一段max_iter 時間,直到似然性或下界的變化小于 tol為止,否則ConvergenceWarning提高a。擬合后,它將為輸入數據點預測最可能的標簽。
0.20版中的新功能。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) n_features維數據點列表。每行對應一個數據點。 |
| 返回值 | 說明 |
|---|---|
| labels | array, shape (n_samples,) 組件標簽。 |
get_params(deep=True)
[源碼]
獲取此估計量的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算量和作為估算量的所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
predict(X)
[源碼]
使用訓練好的模型預測X中數據樣本的標簽。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) n_features維數據點列表。每行對應一個數據點。 |
| 返回值 | 說明 |
|---|---|
| labels | array, shape (n_samples,) 組件標簽。 |
predict_proba(X)
[源碼]
給定數據,預測每個分量的后驗概率。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) n_features維數據點列表。每行對應一個數據點。 |
| 返回值 | 說明 |
|---|---|
| resp | array, shape (n_samples, n_components) 返回給定每個樣本的模型中每個高斯(狀態)的概率。 |
sample(n_samples=1)
[源碼]
從擬合的高斯分布中生成隨機樣本。
| 參數 | 說明 |
|---|---|
| n_samples | int, optional 要生成的樣本數。默認為1。 |
| 返回值 | 說明 |
|---|---|
| X | array, shape (n_samples, n_features) 隨機生成的樣本 |
| y | array, shape (nsamples,) 組件標簽 |
score(X, y=None)
[源碼]
計算給定數據X的每樣本平均對數似然度。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_dimensions) n_features維數據點列表。每行對應一個數據點。 |
| 返回值 | 說明 |
|---|---|
| log_likelihood | float 給定X的高斯混合的對數似然。 |
score_samples(X)
[源碼]
計算每個樣本的加權對數概率。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) n_features維數據點列表。每行對應一個數據點。 |
| 返回值 | 說明 |
|---|---|
| log_prob | array, shape (n_samples,) 在X中記錄每個數據點的概率。 |
set_params(**params)
[源碼]
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如 pipelines)。后者具有形式的參數, <component>__<parameter>以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估算量參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估算量實例。 |