sklearn.feature_selection.chi2?
sklearn.feature_selection.chi2(X, y)
計算每個非負特征與類之間的卡方統計量。
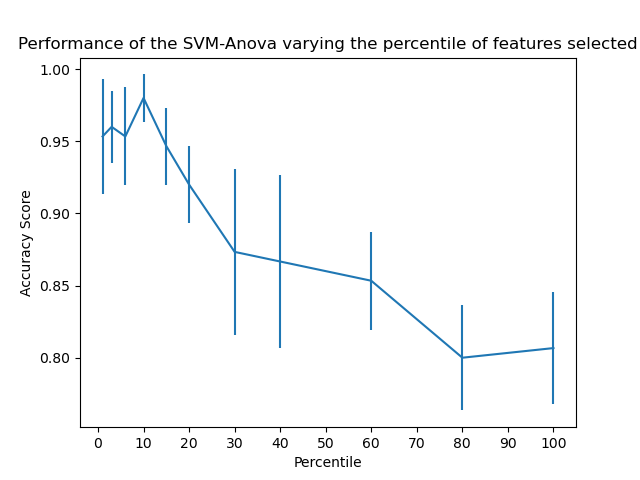
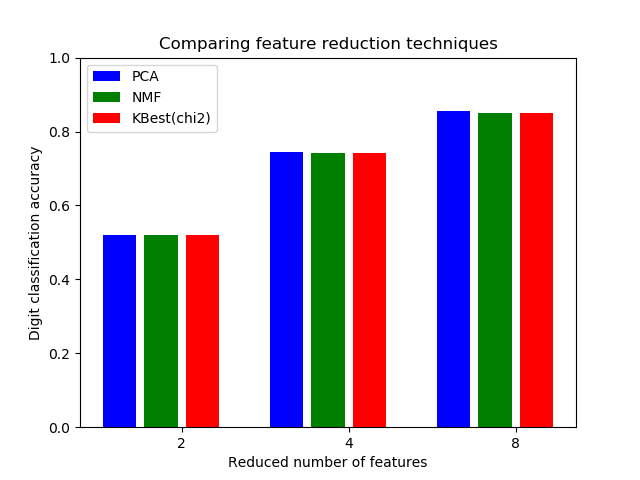
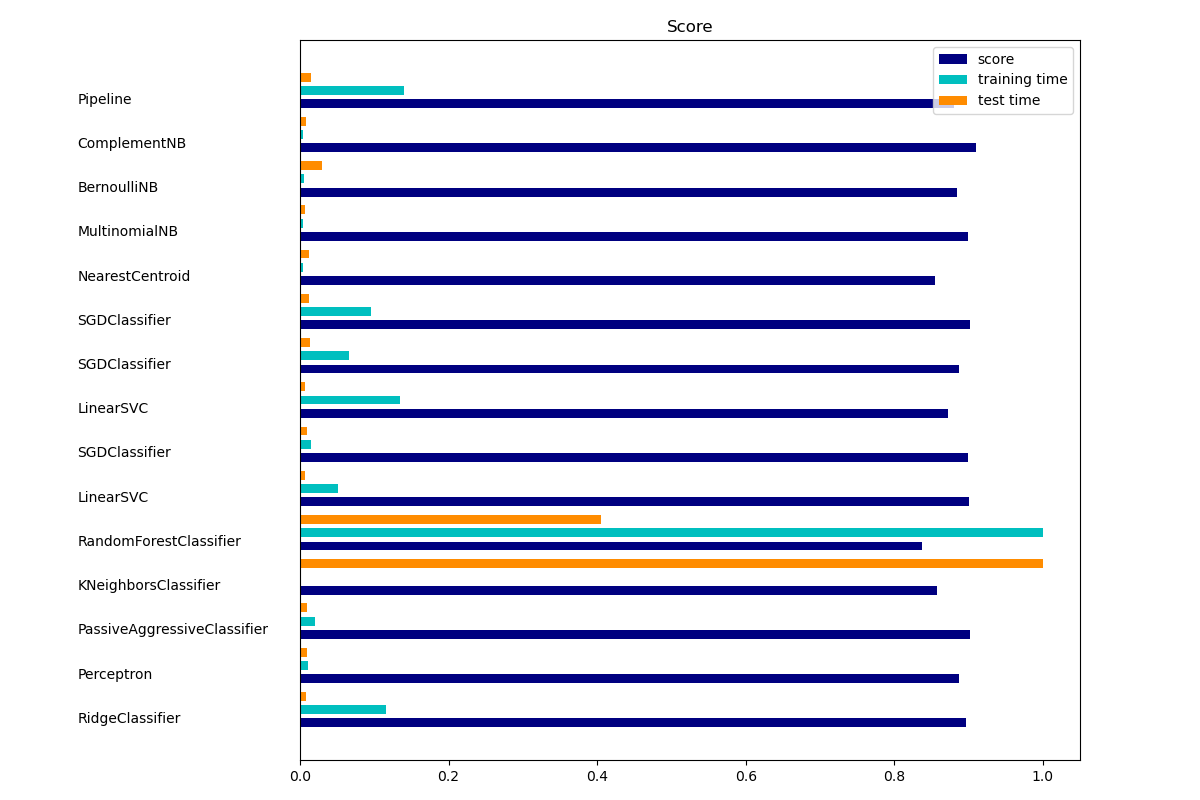
該分數可用于從X中選擇測試卡方統計量值最高的特征,相對于類,該特征必須僅包含非負特征,例如布爾值或頻率(例如,文檔分類中的術語計數)。
回想一下,卡方檢驗可測量隨機變量之間的相關性,因此使用此功能可以“淘汰”最有可能與類別無關的特征。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 樣本向量。 |
| y | array-like of shape (n_samples,) 目標向量(類標簽)。 |
| 返回值 | 說明 |
|---|---|
| chi2 | array, shape = (n_features,) 每個特征的chi2統計信息。 |
| pval | array, shape = (n_features,) 每個特征的p值。 |
另見
標簽和特征之間的ANOVA F值,用于分類任務。
回歸任務的標簽和特征之間的F值。
注
該算法的復雜度為O(n_classes * n_features)。