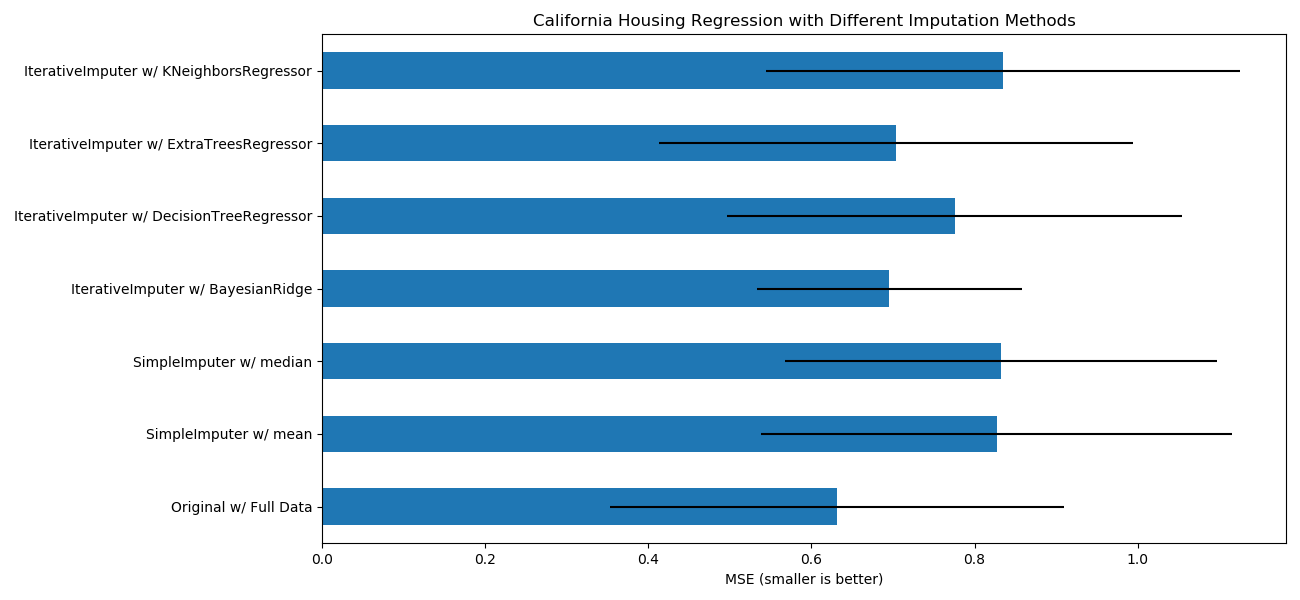
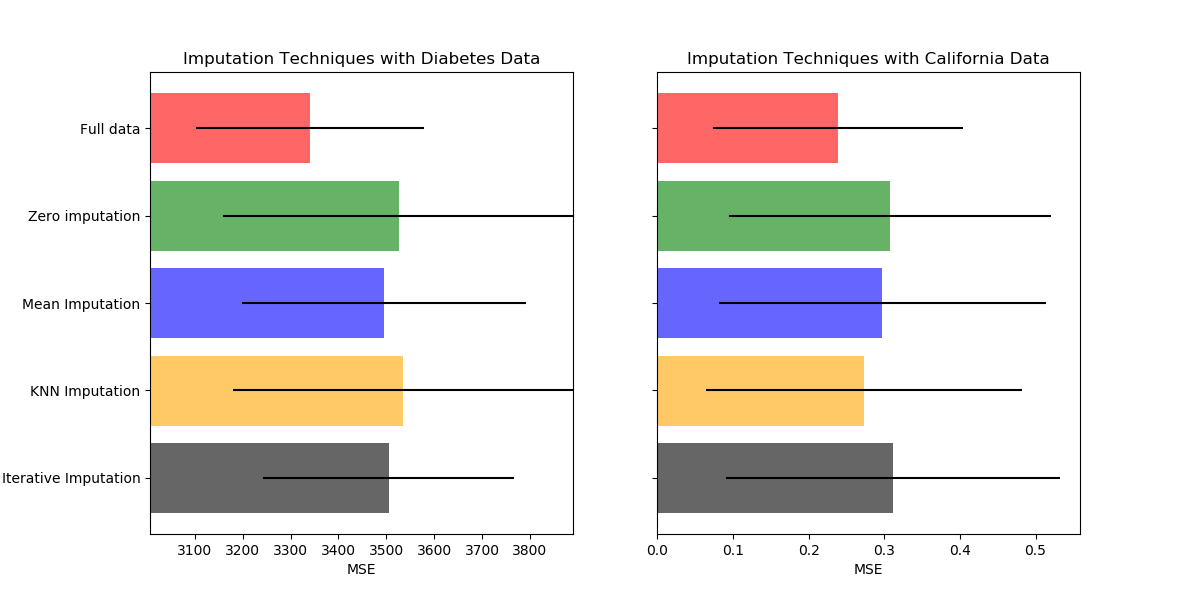
sklearn.impute.IterativeImputer?
class sklearn.impute.IterativeImputer(estimator=None, *, missing_values=nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy='mean', imputation_order='ascending', skip_complete=False, min_value=None, max_value=None, verbose=0, random_state=None, add_indicator=False)
從所有其他特征中估計每個特征的多元插補器。
一種通過以循環方式將具有缺失值的每個特征建模為其他特征的函數來估算缺失值的策略。
在用戶指南中閱讀更多內容。
0.21版中的新功能。
注意:此估計器目前仍處于試驗階段:預測和API可能會更改,而不會出現任何棄用周期。要使用它,您需要顯式導入enable_iterative_imputer:
>>> # explicitly require this experimental feature
>>> from sklearn.experimental import enable_iterative_imputer # noqa
>>> # now you can import normally from sklearn.impute
>>> from sklearn.impute import IterativeImputer
| 參數 | 說明 |
|---|---|
| estimator | estimator object, default=BayesianRidge() 在循環插補的每個步驟中使用的估計器。如果 sample_posterior為True,則估算器必須在predict方法中提供支持return_std 。 |
| missing_values | int, np.nan, default=np.nan 缺失值的占位符。所有出現 missing_values的情況都將被估算。對于具有缺失值的可空整數類型的pandas數據框,missing_values 應將其設置為np.nan,因為pd.NA將轉換為np.nan。 |
| sample_posterior | boolean, default=False 是否對每個擬合估計器的(高斯)后驗預測進行采樣。如果設為 True,估計器必須支持predict方法中的return_std。如果IterativeImputer用于多個插補,則設置為 True。 |
| max_iter | int, default=10 返回最后一輪計算的插補之前要執行的最大插補輪數。一輪是對每個缺失值的特征進行一次插補。遇到 abs(max(X_t - X_{t-1}))/abs(max(X[known_vals]))<TOL則停止,這里X_t是在迭代t中的X。注意只有在sample_posterior=False時才會提前停止。 |
| tol | float, default=1e-3 停止條件的容差。 |
| n_nearest_features | int, default=None 用于估計每個特征列的缺失值的其他特征數。使用每個特征對之間的絕對相關系數(在初始插補之后)測量特征之間的鄰近度。為了確保整個插補過程中的特征覆蓋,相鄰特征不一定是最接近的,而是以與每個插補目標特征的相關性成比例的概率來提取。當特征很多時可以大大提高速度。如果為 None,則將使用所有特征。 |
| initial_strategy | str, default=’mean’ 用于初始化缺失值的策略。與 sklearn.impute.SimpleImputer中的strategy參數有效值相同:{“mean”, “median”,“most_frequent”或“ constant”}。 |
| imputation_order | str, default=’ascending’ 特征的插補順序。可能的取值有: - “ascending” 從缺失值最少的特征到最多的特征。 - “descending” 從缺失值最多的特征到最少的特征。 - “roman” 左到右。 - “arabic” 右到左。 - “random” 每輪隨機順序。 |
| skip_complete | boolean, default=False 如果為 True,包含有缺失值的特征在進行fit期間沒有任何缺失值的transform轉換時 ,將僅使用初始插補方法來插補。如果有很多特征在fit和transform時都沒有缺失值保存計算,則設置為True。 |
| min_value | float or array-like of shape (n_features,), default=None. 最小的可能估算值。如果為標量,廣播成(n_features,)的形狀。如果為類數組,則期望形狀為(n_features,),每個特征有一個最小值。 None(默認)將轉換為np.inf。 |
| max_value | float or array-like of shape (n_features,), default=None. 最大的可能估算值。如果為標量,廣播成(n_features,)的形狀。如果為類數組,則期望形狀為(n_features,),每個特征有一個最大值。 None(默認)將轉換為np.inf。 |
| verbose | int, default=0 詳細度標志,控制在評估函數時發出的調試消息。越大,輸出越冗長。可以是0、1或2。 |
| random_state | int, RandomState instance or None, default=None 要使用的偽隨機數生成器的種子。如果n_nearest_features不為None,對估計器特征進行隨機選擇,如果為 random,則imputation_order;如果 sample_posterior為True,則從后驗采樣。確定性使用整數。請參閱詞匯表。 |
| add_indicator | boolean, default=False 如果為True,則 MissingIndicator轉換將堆疊到輸入的轉換的輸出上。這使得預測性估計器可以解釋盡管進行了插補但仍存在缺失。如果某個特征在擬合或訓練時沒有缺失值,則即使在變換或測試時有缺失值,該特征也不會出現在缺失指示器上。 |
| 參數 | 說明 |
|---|---|
| initial_imputer_ | object of type sklearn.impute.SimpleImputer用于初始化缺失值的插補器。 |
| imputation_sequence_ | list of tuples 每個元組具有 (feat_idx, neighbor_feat_idx, estimator),其中feat_idx是要插補的當前特征,neighbor_feat_idx是用于插補當前特征的其他特征的數組,并且estimator是用于插補的經過訓練的估計器。長度為self.n_features_with_missing_ * self.n_iter_。 |
| n_iter_ | int 發生的迭代輪數。如果達到提前停止標準,將小于 self.max_iter。 |
| n_features_with_missing_ | int 包含缺失值的特征數量。 |
| indicator_ | sklearn.impute.MissingIndicator用于為缺失值添加二進制指標的指示器。 如果add_indicator為False,則為 None。 |
| random_state_ | RandomState instance 由種子、隨機數生成器或 np.random生成的RandomState實例。 |
另見
缺失值的單變量插補。
注
為了支持歸納模式下的插補,我們在fit階段中存儲每個特征的估計量,并在transform階段中進行預測而無需重新擬合(按順序)。
transform之前,全部為缺失值的特征將在fit時丟棄。
參考
示例
>>> import numpy as np
>>> from sklearn.experimental import enable_iterative_imputer
>>> from sklearn.impute import IterativeImputer
>>> imp_mean = IterativeImputer(random_state=0)
>>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]])
IterativeImputer(random_state=0)
>>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]]
>>> imp_mean.transform(X)
array([[ 6.9584..., 2. , 3. ],
[ 4. , 2.6000..., 6. ],
[10. , 4.9999..., 9. ]])
方法
| 方法 | 說明 |
|---|---|
fit(X[, y]) |
在X上擬合插補,然后返回self對象。 |
fit_transform(X[, y]) |
在X上擬合輸入項并返回變換后的X。 |
get_params([deep]) |
獲取此估計器的參數。 |
set_params(**params) |
設置此估計器的參數。 |
transform(X) |
對X中所有缺失值進行插補。 |
__init__(estimator=None, *, missing_values=nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy='mean', imputation_order='ascending', skip_complete=False, min_value=None, max_value=None, verbose=0, random_state=None, add_indicator=False)
初始化self,參見help(type(self))獲取更準確的說明。
fit(X, y=None)
在X上擬合插補,然后返回self對象。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix}, shape (n_samples, n_features) 輸入數據,其中 n_samples是樣本數, n_features是特征數。 |
| y | ignored |
| 返回值 | 說明 |
|---|---|
| self | object 返回self對象。 |
fit_transform(X, y=None)
在X上擬合輸入項并返回變換后的X。
| 參數 | 說明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 輸入數據,其中 n_samples是樣本數, n_features是特征數。 |
| y | ignored |
| 返回值 | 說明 |
|---|---|
| Xt | array-like, shape (n_samples, n_features) 估算的輸入數據。 |
get_params(deep=True)
獲取此估計器的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
set_params(**params)
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。后者具有<component>__<parameter>形式的參數, 以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估計器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估計器實例。 |
transform(X)
對X中所有缺失值進行插補。
請注意,這是隨機的,并且如果random_state不固定,則重復調用或排列輸入將產生不同的結果。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 輸入數據。 |
| 返回值 | 說明 |
|---|---|
| Xt | array-like, shape (n_samples, n_features) 估算的輸入數據。 |