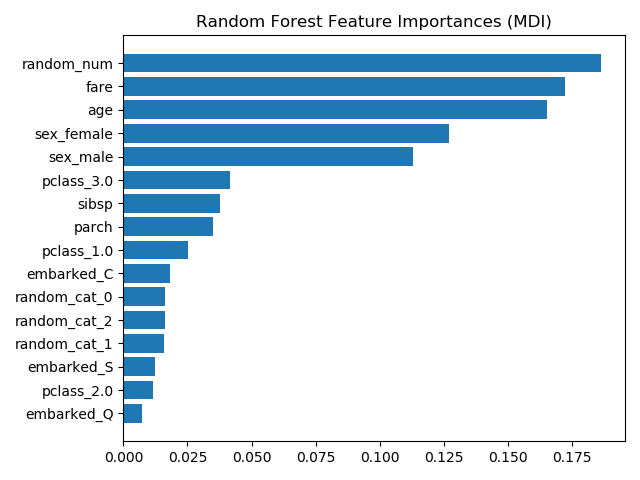
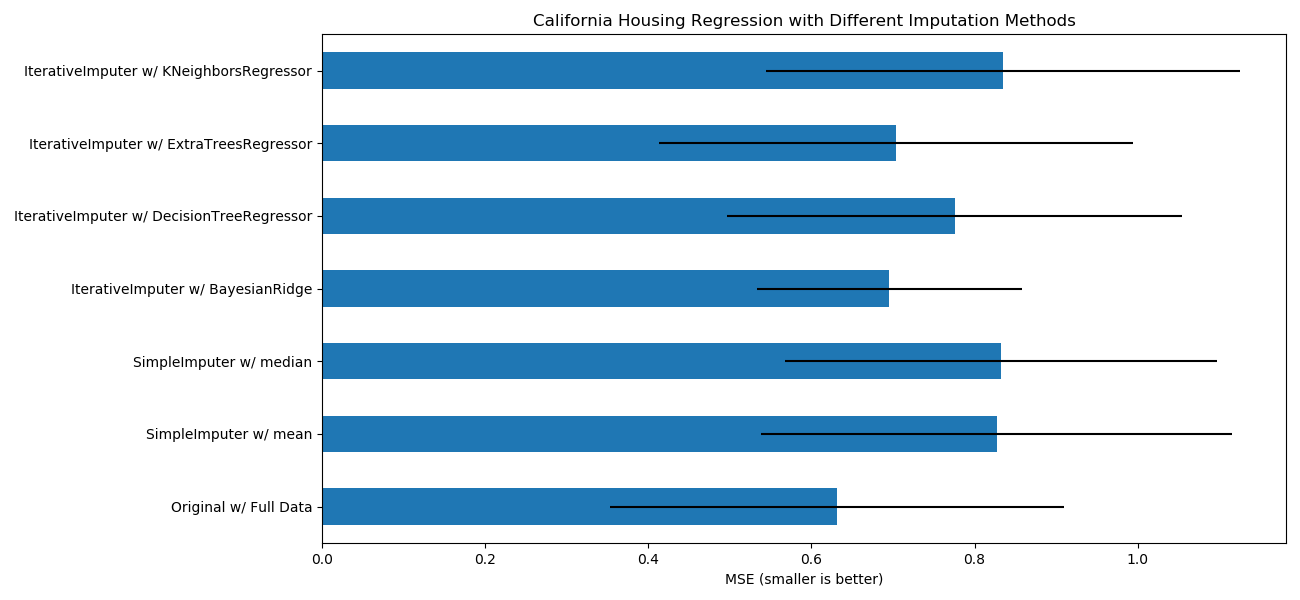
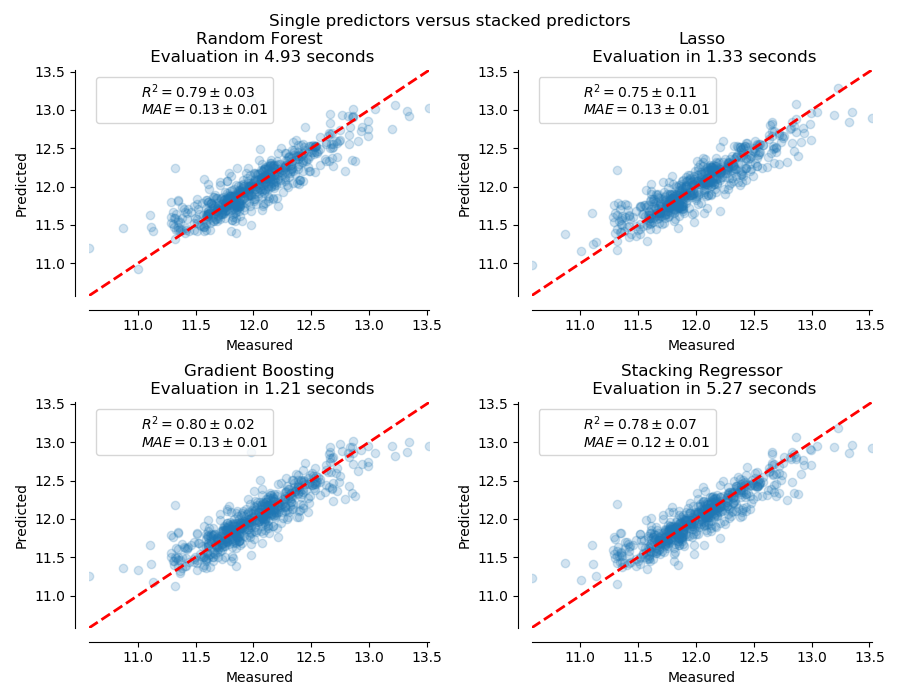
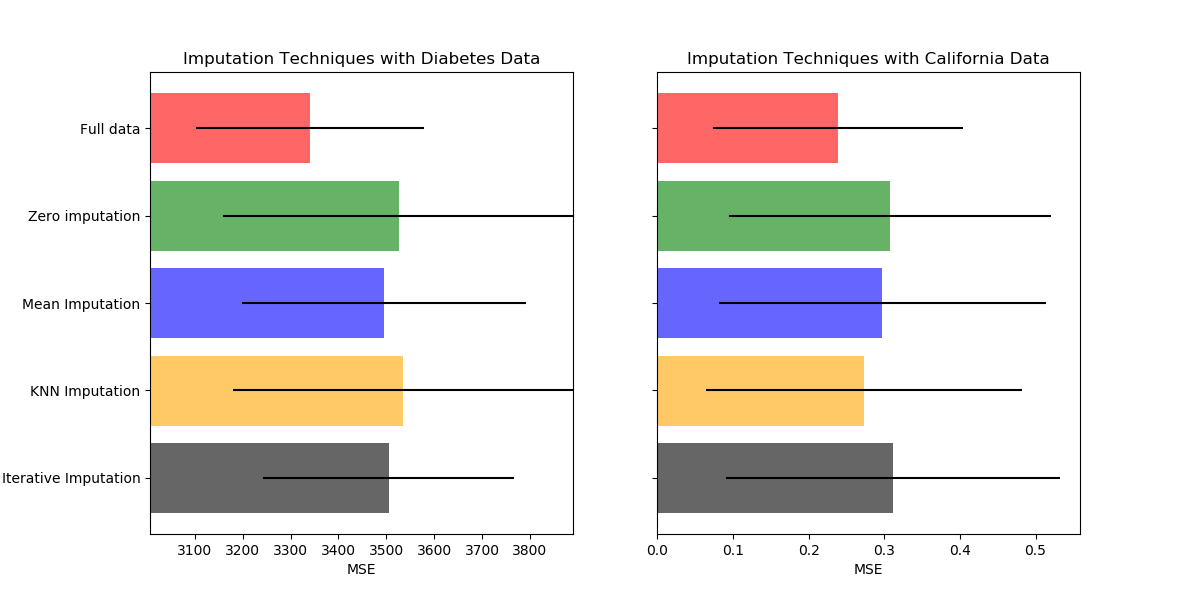
sklearn.impute.SimpleImputer?
class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy='mean', fill_value=None, verbose=0, copy=True, add_indicator=False)
用于缺失值插補的轉換器。
在用戶指南中閱讀更多內容。
0.20版中的新功能:SimpleImputer替換之前已刪除的sklearn.preprocessing.Imputer 估計器。
| 參數 | 說明 |
|---|---|
| missing_values | number, string, np.nan (default) or None 缺失值的占位符。所有出現 missing_values的情況都將被估算。對于具有缺失值的可空整數類型的pandas數據框,missing_values 應將其設置為np.nan,因為pd.NA將轉換為np.nan。 |
| strategy | string, default=’mean’ 插補策略 - 如果是“mean”,則使用每列中的平均值替換缺失值。只能與數字數據一起使用。 - 如果為“median”,則使用每列中的中位數替換缺失值。只能與數字數據一起使用。 - 如果為“ most_frequent”,則使用每一列中的眾數替換缺失值。可以與字符串或數字數據一起使用。 - 如果為“constant”,則將缺失的值替換為fill_value。可以與字符串或數字數據一起使用。 0.20版中的新功能:對于固定值插補,strategy =“ constant”。 |
| fill_value | string or numerical value, default=None 當strategy ==“ constant”時,fill_value用于替換所有missing_values出現的情況。如果保留默認值,則在填充數字數據時fill_value將為0,而對于字符串或對象數據類型則為“ missing_value”。 |
| verbose | integer, default=0 控制日志的詳細程度。 |
| copy | boolean, default=True 如果為True,將創建X的副本。如果為False,只要可能,就要對其進行插補。請注意,在以下情況下,即使 copy=False,也會生成一個新的副本:- 如果X不是浮點值數組; - 如果X被編碼為CSR矩陣; - 如果add_indicator = True。 |
| add_indicator | boolean, default=False 如果為True,則 MissingIndicator轉換將堆疊到輸入的轉換的輸出上。這使得預測性估計器可以解釋盡管進行了插補但仍存在缺失。如果某個特征在擬合或訓練時沒有缺失值,則即使在變換或測試時有缺失值,該特征也不會出現在缺失指示器上。 |
| 屬性 | 說明 |
|---|---|
| statistics_ | array of shape (n_features,) 每個特征的插補填充值。 np.nan值的統計信息可以計算得出。在transform過程中,特征對應的np.nan 統計信息將被丟棄。 |
| indicator_ | sklearn.impute.MissingIndicator用于為缺失值添加二進制指示符的指示符。 如果add_indicator為False,則 None。 |
另見
缺失值的多元估算。
注
如果策略不是“constant”,在transform之前,fit中僅包含缺失值的列將被丟棄。
示例
>>> import numpy as np
>>> from sklearn.impute import SimpleImputer
>>> imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean')
>>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]])
SimpleImputer()
>>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]]
>>> print(imp_mean.transform(X))
[[ 7. 2. 3. ]
[ 4. 3.5 6. ]
[10. 3.5 9. ]]
方法
| 方法 | 說明 |
|---|---|
fit(X[, y]) |
在X上擬合插補。 |
fit_transform(X[, y]) |
擬合數據,然后對其進行轉換。 |
get_params([deep]) |
獲取此估計器的參數。 |
set_params(**params) |
設置此估計器的參數。 |
transform(X) |
對X中所有缺失值進行插補。 |
__init__(*, missing_values=nan, strategy='mean', fill_value=None, verbose=0, copy=True, add_indicator=False)
初始化self,參見help(type(self))獲取更準確的說明。
fit(X, y=None)
在X上擬合插補。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix}, shape (n_samples, n_features) 輸入數據,其中 n_samples是樣本數, n_features是特征數。 |
| 返回值 | 說明 |
|---|---|
| self | SimpleImputer |
fit_transform(X, y=None, **fit_params)
擬合數據,然后對其進行轉換。
使用可選參數fit_params將轉換器擬合到X和y,并返回X的轉換值。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目標值。 |
| **fit_params | dict 其他擬合參數。 |
| 返回值 | 說明 |
|---|---|
| X_new | ndarray array of shape (n_samples, n_features_new) 轉換后的數組。 |
get_params(deep=True)
獲取此估計器的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
set_params(**params)
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。后者具有<component>__<parameter>形式的參數, 以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估計器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估計器實例。 |
transform(X)
對X中所有缺失值進行插補。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix}, shape (n_samples, n_features) 輸入數據。 |