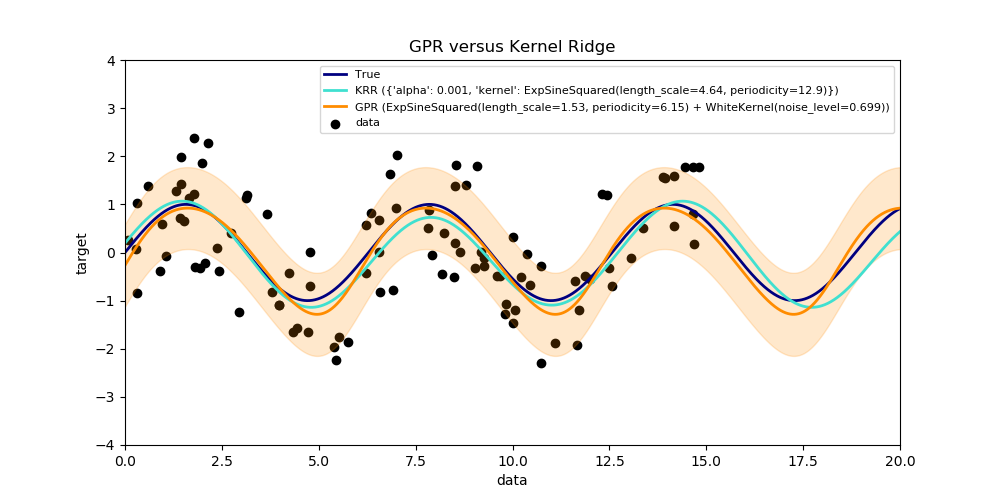
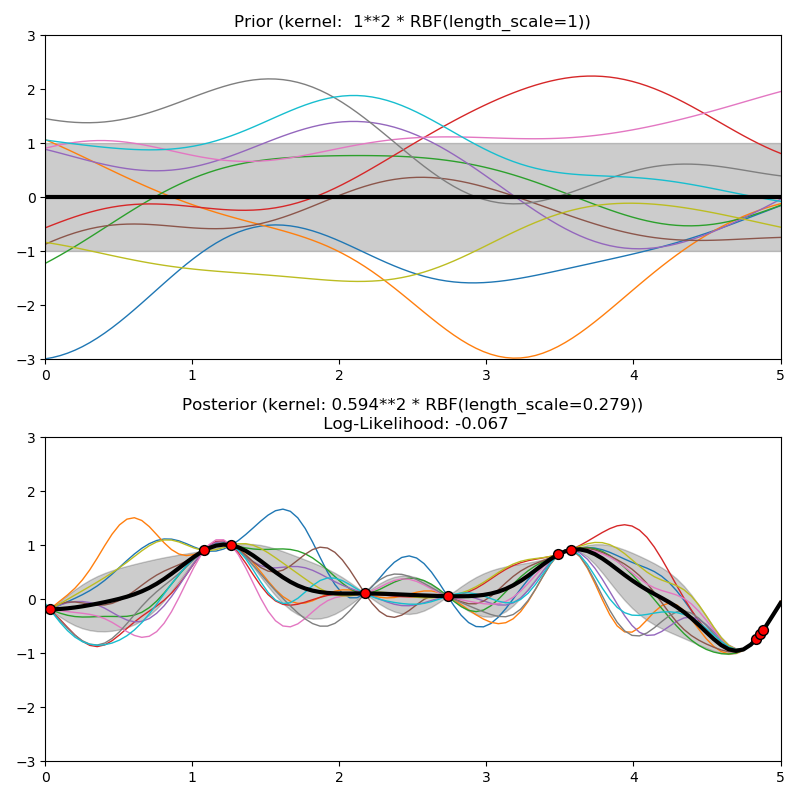
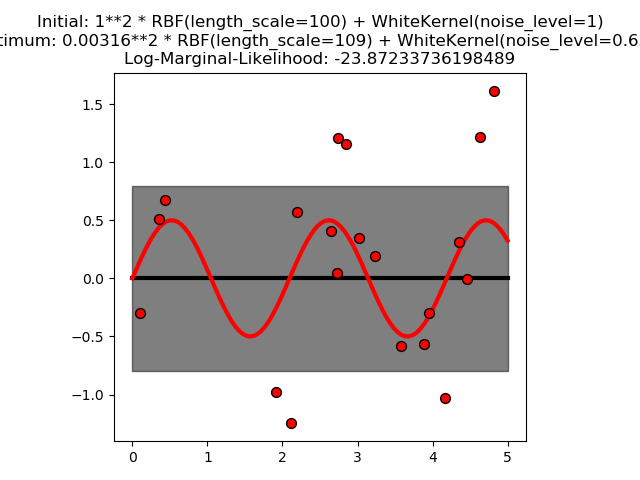
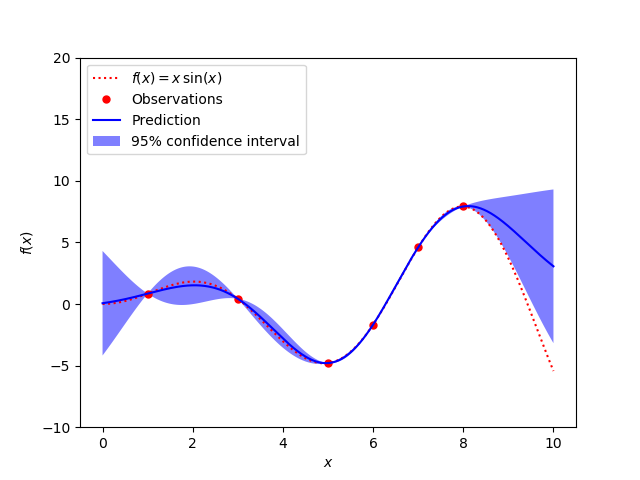
sklearn.gaussian_process.GaussianProcessRegressor?
class sklearn.gaussian_process.GaussianProcessRegressor(kernel=None, *, alpha=1e-10, optimizer='fmin_l_bfgs_b', n_restarts_optimizer=0, normalize_y=False, copy_X_train=True, random_state=None)
高斯過程回歸。
該方法是基于Rasmussen和Williams的機器學習高斯過程(GPML)算法2.1節實現的。
除了標準scikit-learn estimator API, GaussianProcessRegressor:
允許預測而不需要預先擬合(基于GP先驗)
提供另一個方法sample_y(X),它評估給定輸入時從探地雷達(前或后)中抽取的樣本
公開一個方法log_marginal_likelihood(theta),它可以被外部用于其他選擇超參數的方法,例如通過馬爾科夫鏈蒙特卡洛。
在用戶指南中閱讀更多內容。
新版本0.18。
| 參數 | 說明 |
|---|---|
| kernel | kernel instance, default=None 指定GP的協方差函數的核。如果沒有傳遞,則默認使用內核“1.0 * RBF(1.0)”。注意,在擬合過程中優化了內核的超參數。 |
| alpha | float or array-like of shape (n_samples), default=1e-10 擬合時在核矩陣對角線上增加的值。較大的值對應于觀測中噪聲水平的增加。這也可以防止在擬合過程中可能出現的數值問題,確保計算值形成一個正定矩陣。如果傳遞了一個數組,它必須具有與用于擬合的數據相同的條目數,并且用作數據點相關的噪聲級別。注意,這相當于添加一個c=alpha的白色內核。允許將噪音聲級直接指定為參數,主要是為了方便和與嶺度的一致性。 |
| optimizer | “fmin_l_bfgs_b” or callable, default=”fmin_l_bfgs_b” 可以是內部支持的優化器之一,用于優化由字符串指定的內核參數,也可以是作為callable傳遞的外部定義的優化器。如果一個可調用的被傳遞,它必須有說明 def optimizer(obj_func, initial_theta, bounds): return theta_opt, func_min # * 'obj_func' is the objective function to be minimized, which # takes the hyperparameters theta as parameter and an # optional flag eval_gradient, which determines if the # gradient is returned additionally to the function value # * 'initial_theta': the initial value for theta, which can be # used by local optimizers # * 'bounds': the bounds on the values of theta .... # Returned are the best found hyperparameters theta and # the corresponding value of the target function. 默認情況下,來自scipy.optimize的“L-BGFS-B”算法。減少使用。如果沒有傳遞,內核的參數將保持不變。可用的內部優化器是: “fmin_l_bfgs_b” |
| n_restarts_optimizer | int, default=0 用于查找使對數邊際似然最大化的內核參數的優化器重啟的次數。優化器的第一次運行是從內核的初始參數執行的,其余的參數(如果有的話)是從允許的ta值的空間中隨機采樣的log-uniform日志。如果大于0,所有的邊界必須是有限的。注意,n_restarts_optimizer == 0表示執行一次運行。 |
| normalize_y | boolean, optional (default: False) 無論目標值y是否歸一化,目標值的均值和方差分別設為0和1。這是推薦的情況下,零均值,單位方差先驗是使用。注意,在這個實現中,在GP的預測被報告之前,正態化是顛倒的。 在版本0.23中進行了更改。 |
| copy_X_train | bool, default=True 如果為真,則在對象中存儲訓練數據的持久副本。否則,只存儲對訓練數據的引用,如果數據被外部修改,則可能導致預測發生更改。 |
| random_state | int or RandomState, default=None 確定用于初始化中心的隨機數生成。在多個函數調用中傳遞可重復的結果。參見: term: Glossary <random_state>. |
| 屬性 | 說明 |
|---|---|
| X_train_ | array-like of shape (n_samples, n_features) or list of object 訓練數據的特征向量或其他表示(也需要預測)。 |
| y_train_ | array-like of shape (n_samples,) or (n_samples, n_targets) 訓練數據中的目標值(也是預測所需要的) |
| kernel_ | kernel instance 用于預測的核函數。內核的結構與作為參數傳遞的內核的結構相同,但具有優化的超參數 |
| L_ | array-like of shape (n_samples, n_samples) X_train_內核的下三角Cholesky分解 |
| alpha_ | array-like of shape (n_samples,) 核空間中訓練數據點的對偶系數 |
| log_marginal_likelihood_value_ | float self.kernel_.theta的對數邊緣似然 |
示例
>>> from sklearn.datasets import make_friedman2
>>> from sklearn.gaussian_process import GaussianProcessRegressor
>>> from sklearn.gaussian_process.kernels import DotProduct, WhiteKernel
>>> X, y = make_friedman2(n_samples=500, noise=0, random_state=0)
>>> kernel = DotProduct() + WhiteKernel()
>>> gpr = GaussianProcessRegressor(kernel=kernel,
... random_state=0).fit(X, y)
>>> gpr.score(X, y)
0.3680...
>>> gpr.predict(X[:2,:], return_std=True)
(array([653.0..., 592.1...]), array([316.6..., 316.6...]))
方法
| 方法 | 說明 |
|---|---|
fit(self, X, y) |
擬合高斯過程回歸模型。 |
get_params(self[, deep]) |
獲取這個估計器的參數。 |
log_marginal_likelihood(self[, theta, …]) |
返回訓練數據的theta的對數邊際似然。 |
predict(self, X[, return_std, return_cov]) |
使用高斯過程回歸模型進行預測 |
sample_y(self, X[, n_samples, random_state]) |
從高斯過程中抽取樣本,在X處取值。 |
score(self, X, y[, sample_weight]) |
返回確定系數R ^ 2的預測。 |
set_params(self, **params) |
設置的參數估計量。 |
__init__(self, kernel=None, *, alpha=1e-10, optimizer='fmin_l_bfgs_b', n_restarts_optimizer=0, normalize_y=False, copy_X_train=True, random_state=None)
初始化self.請參閱help(type(self))以獲得準確的說明。
fit( X, y)
擬合高斯過程回歸模型。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) or list of object 訓練數據的特征向量或其他表示。 |
| y | array-like of shape (n_samples,) or (n_samples, n_targets) 目標值 |
| 返回值 | 說明 |
|---|---|
| self | returns an instance of self. |
get_params(self, deep=True)
獲取這個估計器的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為真,將返回此估計器的參數以及包含的作為估計器的子對象。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到它們的值。 |
log_marginal_likelihood(self, theta=None, eval_gradient=False, clone_kernel=True)
返回訓練數據的theta的對數邊際似然。
| 參數 | 說明 |
|---|---|
| theta | array-like of shape (n_kernel_params,) default=None 核超參數的對數邊際似然被評估。如果沒有,則預先計算self.kernel_的log_marginal_likelihood。θ是回來了。 |
| eval_gradient | bool, default=False 如果為真,則額外返回關于位置的核超參數的對數邊際似然的梯度。如果為真,一定不為零。 |
| clone_kernel | bool, default=True 如果為真,則復制內核屬性。如果為False,則修改內核屬性,但可能會導致性能改進。 |
| 返回值 | 說明 |
|---|---|
| log_likelihood | float 訓練數據的對數邊際似然。 |
| log_likelihood_gradient | ndarray of shape (n_kernel_params,), optional 關于位置的核超參數的對數邊際似然的梯度。只有當eval_gradient為真時才返回。 |
predict(self, X, return_std=False, return_cov=False)
使用高斯過程回歸模型進行預測
我們也可以使用GP先驗,基于一個不擬合的模型進行預測。除了預測分布的均值,還有其標準差 (return_std=True)或協方差(return_cov=True)。注意,最多可以請求其中的一個。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) or list of object 對GP進行評估的查詢點。 |
| return_std | bool, default=False 如果為真,則返回查詢點預測分布的標準偏差以及平均值。 |
| return_cov | bool, default=False 如果為真,則返回聯合預測分布在查詢點的協方差和均值 |
| 返回值 | 說明 |
|---|---|
| y_mean | ndarray of shape (n_samples, [n_output_dims]) 查詢點的預測分布平均值 |
| y_std | ndarray of shape (n_samples,), optional 查詢點預測分布的標準差。只有當 return_std為真時才返回。 |
| y_cov | y_cov 聯合預測分布的協方差是一個疑問點。只有當 return_cov為真時才返回。 |
sample_y(self, X, n_samples=1, random_state=0)
從高斯過程中抽取樣本,在X處取值。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) or list of object 對GP進行評估的查詢點。 |
| n_samples | int, default=1 從高斯過程中抽取的樣本數 |
| random_state | int, RandomState, default=0 確定隨機數生成隨機抽取樣本。在多個函數調用中傳遞可重復的結果。參見:term: Glossary <random_state>. |
| 返回值 | 說明 |
|---|---|
| y_samples | ndarray of shape (n_samples_X, [n_output_dims], n_samples) Values of n_samples samples drawn from Gaussian process and evaluated at query points. |
score(self, X, y, sample_weight=None)
返回預測的決定系數R^2。
定義系數R^2為(1 - u/v),其中u為(y_true - y_pred) ** 2).sum()的殘差平方和,v為(y_true - y_true.mean()) ** 2).sum()的平方和。最好的可能的分數是1.0,它可能是負的(因為模型可以任意地更糟)。常數模型總是預測y的期望值,而不考慮輸入特征,得到的R^2得分為0.0。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 測試樣品。對于某些估計器,這可能是一個預先計算的內核矩陣或一列通用對象,而不是形狀= (n_samples, n_samples_fitting),其中n_samples_fitting是用于擬合估計器的樣本數量。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真值。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重。 |
| 返回值 | 說明 |
|---|---|
| score | float R^2 of self.predict(X) wrt. y. |
注
調用回歸變量上的score時使用的R2 score使用0.23版本的multioutput='uniform_average'來保持與r2_score的默認值一致。這影響了所有多輸出回歸的評分方法(除了MultiOutputRegressor)。
set_params(self, **params)
設置這個估計器的參數。
該方法適用于簡單估計器和嵌套對象(如管道)。后者具有形式為<component>__<parameter>的參數,這樣就可以更新嵌套對象的每個樣本。
| 參數 | 說明 |
|---|---|
| **params | dict 估計參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估計實例。 |