sklearn.linear_model.BayesianRidge?
class sklearn.linear_model.BayesianRidge(*, n_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, alpha_init=None, lambda_init=None, compute_score=False, fit_intercept=True, normalize=False, copy_X=True, verbose=False)
貝葉斯嶺回歸。
擬合貝葉斯山脊模型。有關此實現以及正則化參數lambda(權重的精度)和alpha(噪聲的精度)的優化的詳細信息,請參見“注釋”部分。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| n_iter | int, default=300 最大迭代次數。應該大于或等于1。 |
| tol | float, default=1e-3 如果w收斂,則停止算法。 |
| alpha_1 | float, default=1e-6 超參數:高于alpha參數的Gamma分布的形狀參數。 |
| alpha_2 | float, default=1e-6 超參數:優先于alpha參數的Gamma分布的反比例參數(速率參數)。 |
| lambda_1 | float, default=1e-6 超參數:高于lambda參數的Gamma分布的形狀參數。 |
| lambda_2 | float, default=1e-6 超參數:優先于lambda參數的Gamma分布的反比例參數(速率參數)。 |
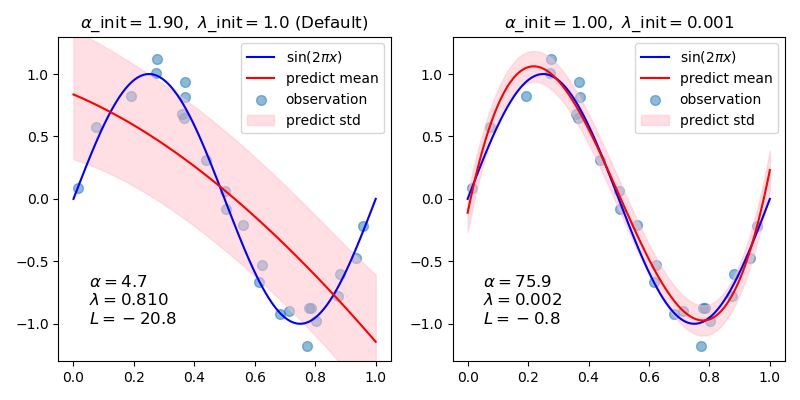
| alpha_init | float, default=None alpha的初始值(噪聲的精度)。如果未設置,則alpha_init為1 / Var(y)。 0.22版中的新功能。 |
| lambda_init | float, default=None Lambda的初始值(權重的精度)。如果未設置,則lambda_init為1。 0.22版中的新功能。 |
| compute_score | bool, default=False 如果為True,則計算模型每一步的目標函數。 |
| fit_intercept | bool, default=True 是否計算該模型的截距。如果設置為false,則在計算中將不使用截距(即,數據應居中)。 |
| normalize | bool, default=Falsefit_intercept設置為False 時,將忽略此參數。如果為True,則在回歸之前通過減去均值并除以l2-范數來對回歸變量X進行歸一化。如果你希望標準化,請先使用 sklearn.preprocessing.StandardScaler,然后調用fit 估算器并設置normalize=False。 |
| copy_X | bool, default=True 如果為True,將復制X;否則X可能會被覆蓋。 |
| verbose | bool, default=False 擬合模型時的詳細模式。 |
| 屬性 | 說明 |
|---|---|
| coef_ | array-like of shape (n_features,) 回歸模型的系數(分布的均值) |
| intercept_ | float 決策函數中的截距。如果 fit_intercept = False則設置為0.0 。 |
| alpha_ | float 估計的噪聲精度。 |
| lambda_ | array-like of shape (n_features,) 權重的估計精度。 |
| sigma_ | array-like of shape (n_features, n_features) 權重的估計方差-協方差矩陣 |
| scores_ | array-like of shape (n_iter_+1,) 如果calculated_score為True,則在每次優化迭代時的對數邊際似然值(待最大化)。該數組從alpha和lambda的初始值獲得的對數邊際似然值開始,以alpha和lambda的估計值獲得的值結束。 |
| n_iter_ | int 達到停止標準的實際迭代次數。 |
注
進行貝葉斯嶺回歸有幾種方法。此實現基于附錄A(Tipping,2001)中描述的算法,其中正則化參數的更新按照(MacKay,1992)中的建議進行。請注意,根據自動相關性確定的新觀點(Wipf和Nagarajan,2008年),這些更新規則不能保證在連續兩次優化迭代之間邊際似然增加。
參考
D. J. C. MacKay, Bayesian Interpolation, Computation and Neural Systems, Vol. 4, No. 3, 1992.
M. E. Tipping, Sparse Bayesian Learning and the Relevance Vector Machine, Journal of Machine Learning Research, Vol. 1, 2001.
示例
>>> from sklearn import linear_model
>>> clf = linear_model.BayesianRidge()
>>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2])
BayesianRidge()
>>> clf.predict([[1, 1]])
array([1.])
方法
| 方法 | 說明 |
|---|---|
fit(X, y[, sample_weight]) |
擬合模型。 |
get_params([deep]) |
獲取此估計量的參數。 |
predict(X[, return_std]) |
使用線性模型進行預測。 |
score(X, y[, sample_weight]) |
返回預測的確定系數R ^ 2。 |
set_params(**params) |
設置此估算器的參數。 |
__init__(*, n_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, alpha_init=None, lambda_init=None, compute_score=False, fit_intercept=True, normalize=False, copy_X=True, verbose=False)
初始化self, 請參閱help(type(self))以獲得準確的說明。
fit(X, y, sample_weight=None)
[源碼]
擬合模型。
| 參數 | 說明 |
|---|---|
| X | ndarray of shape (n_samples, n_features) 訓練數據。 |
| y | ndarray of shape (n_samples,) 目標值(整數)。如有必要,將強制轉換為X的數據類型。 |
| sample_weight | ndarray of shape (n_samples,), default=None 每個樣本的權重 0.20版中的新功能: BayesianRidge支持sample_weight參數。 |
| 返回值 | 說明 |
|---|---|
| self | returns an instance of self. |
get_params(deep=True)
[源碼]
獲取此估計量的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
predict(X, return_std=False)
[源碼]
使用線性模型進行預測。
除了預測分布的平均值外,還可以返回其標準偏差。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 樣本數據 |
| return_std | bool, default=False 是否返回后驗預測的標準差。 |
| 返回值 | 說明 |
|---|---|
| y_mean | array-like of shape (n_samples,) 查詢點的預測分布平均值。 |
| y_std | array-like of shape (n_samples,) 查詢點的預測分布的標準偏差。 |
score(X, y, sample_weight=None)
[源碼]
返回預測的確定系數R ^ 2。
系數R ^ 2定義為(1- u / v),其中u是殘差平方和((y_true-y_pred)** 2).sum(),而v是總平方和((y_true- y_true.mean())** 2).sum()。可能的最高得分為1.0,并且也可能為負(因為該模型可能會更差)。一個常數模型總是預測y的期望值,而不考慮輸入特征,得到的R^2得分為0.0。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 測試樣本。對于某些估計量,這可以是預先計算的內核矩陣或通用對象列表,形狀為(n_samples,n_samples_fitted),其中n_samples_fitted是用于擬合估計器的樣本數。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真實值。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重。 |
| 返回值 | 說明 |
|---|---|
| score | float 預測值與真實值的R^2。 |
注
調用回歸器中的score時使用的R2分數,multioutput='uniform_average'從0.23版開始使用 ,與r2_score默認值保持一致。這會影響多輸出回歸的score方法( MultiOutputRegressor除外)。
set_params(**params)
[源碼]
設置此估計器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。后者具有形式為 <component>__<parameter>的參數,這樣就可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估計器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估計器實例。 |