sklearn.preprocessing.StandardScaler?
class sklearn.preprocessing.StandardScaler(*, copy=True, with_mean=True, with_std=True)
通過去除均值并將其縮放為單位方差來標準化特征樣本x的標準得分計算為:
z = (x - u) / s
其中u是訓練樣本的平均值,如果with_mean = False,則為零; s是訓練樣本的標準偏差,如果with_std = False,則為1。
通過計算訓練集中樣本的相關統計信息,對每個特征進行獨立的居中和縮放。然后將平均值和標準偏差存儲起來,以使用變換在以后的數據上使用。
數據集的標準化是許多機器學習估計器的普遍要求:如果各個特征看起來或多或少不像標準正態分布數據(例如均值和單位方差為0的高斯),則它們可能表現不佳。
例如,在學習算法的目標函數中使用的許多元素(例如支持向量機的RBF內核或線性模型的L1和L2正則化器)都假定所有特征都圍繞0居中并且具有相同順序的方差。如果某個特征的方差比其他特征大幾個數量級,則它可能會支配目標函數并使估計器無法按預期從其他特征中正確學習。
還可以通過傳遞with_mean = False來將此縮放器應用于稀疏CSR或CSC矩陣,以避免破壞數據的稀疏性結構。
閱讀更多內容參見用戶指南。
| 參數 | 說明 |
|---|---|
| copy | boolean, optional, default True 如果為False,請嘗試避免復制并改為就地縮放。不能保證總是在原地工作;例如,如果數據不是NumPy數組或scipy.sparse CSR矩陣,則可能仍會返回副本。 |
| with_mean | boolean, True by default 如果為True,則在縮放之前將數據居中。嘗試使用稀疏矩陣時,這不起作用(并且會引發異常),因為將它們居中需要建立一個密集的矩陣,在通常的使用情況下,該矩陣可能太大而無法容納在內存中。 |
| with_std | boolean, True by default 如果為True,則將數據縮放到單位方差(或等效地,單位標準偏差)。 |
| 屬性 | 說明 |
|---|---|
| scale_ | ndarray or None, shape (n_features,) 每個要素的數據相對縮放。這是使用np.sqrt(var)計算的。當with_std = False時等于無。 0.17版中的新功能:scale |
| mean_ | ndarray or None, shape (n_features,) 訓練集中每個特征的平均值。當with_mean = False時等于無。 |
| var_ | ndarray or None, shape (n_features,) 訓練集中每個要素的方差。用于計算scale_。當with_std = False時等于無。 |
| n_samples_seen_ | int or array, shape (n_features,) 估計器為每個要素處理的樣本數。如果不缺少樣本,則n_samples_seen將為整數,否則將為數組。將在新的調用中重置為fit,但在partial_fit調用中遞增。 |
另見:
沒有估算器API的等效函數。
進一步刪除帶有'whiten = True'的特征之間的線性相關性。
注釋
NaN被視為缺失值:忽略適合度,并保持變換值。
對于標準偏差,我們使用偏差估算器,它等于numpy.std(x,ddof = 0)。請注意,選擇ddof不太可能影響模型性能。
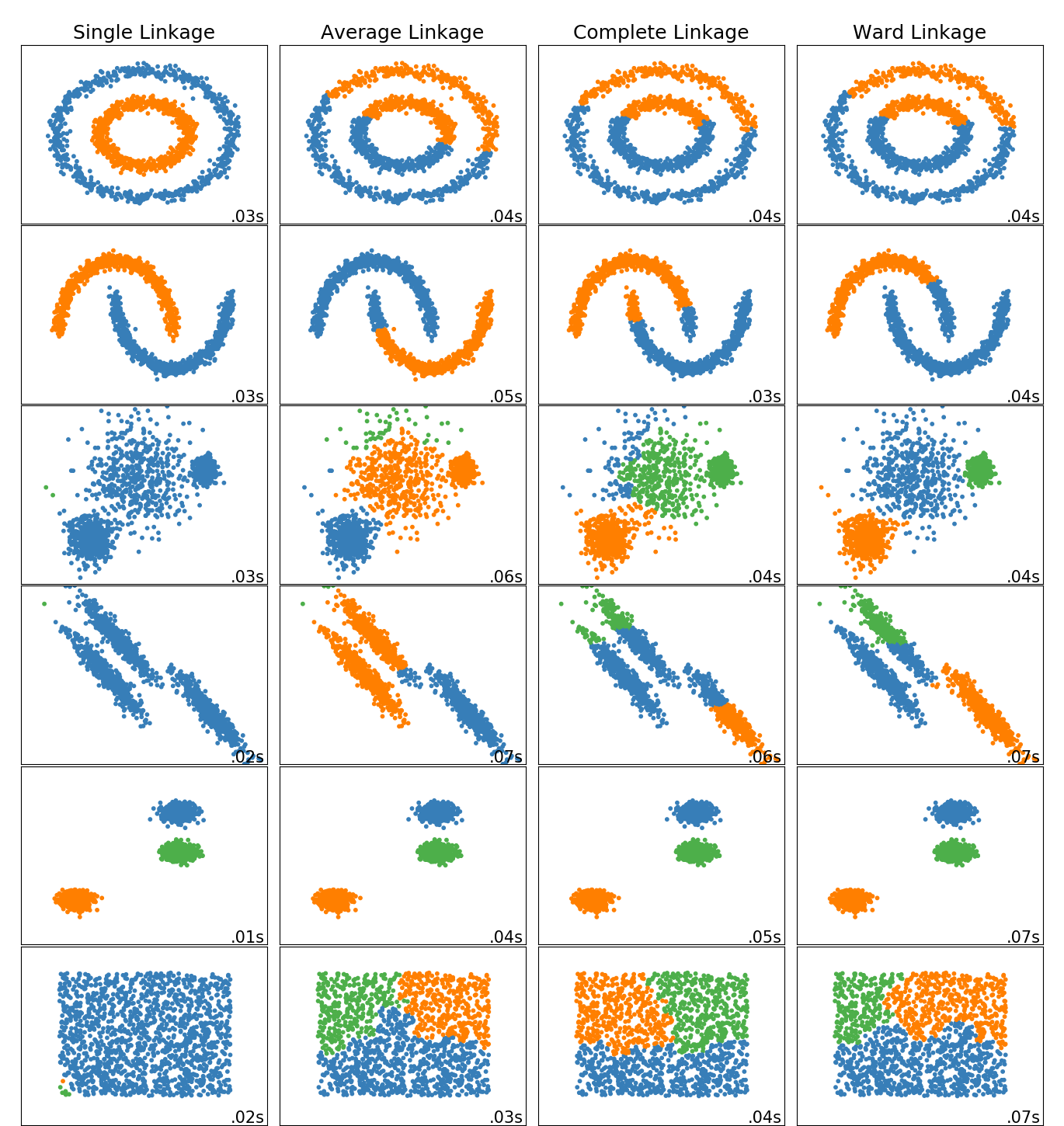
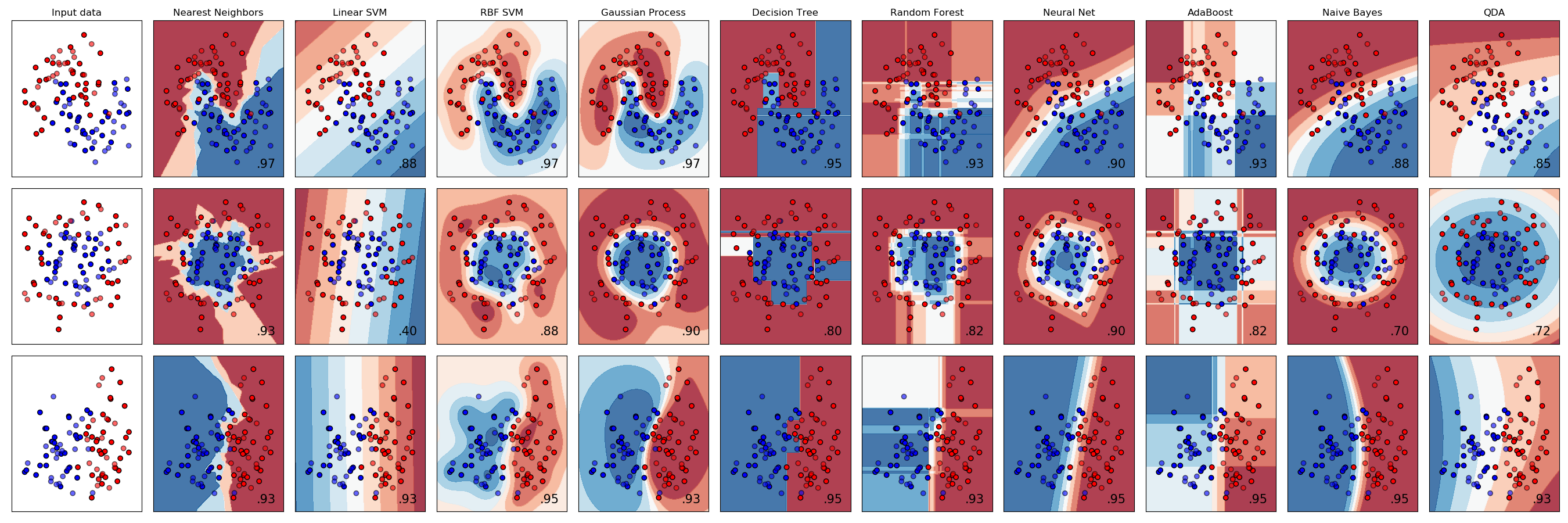
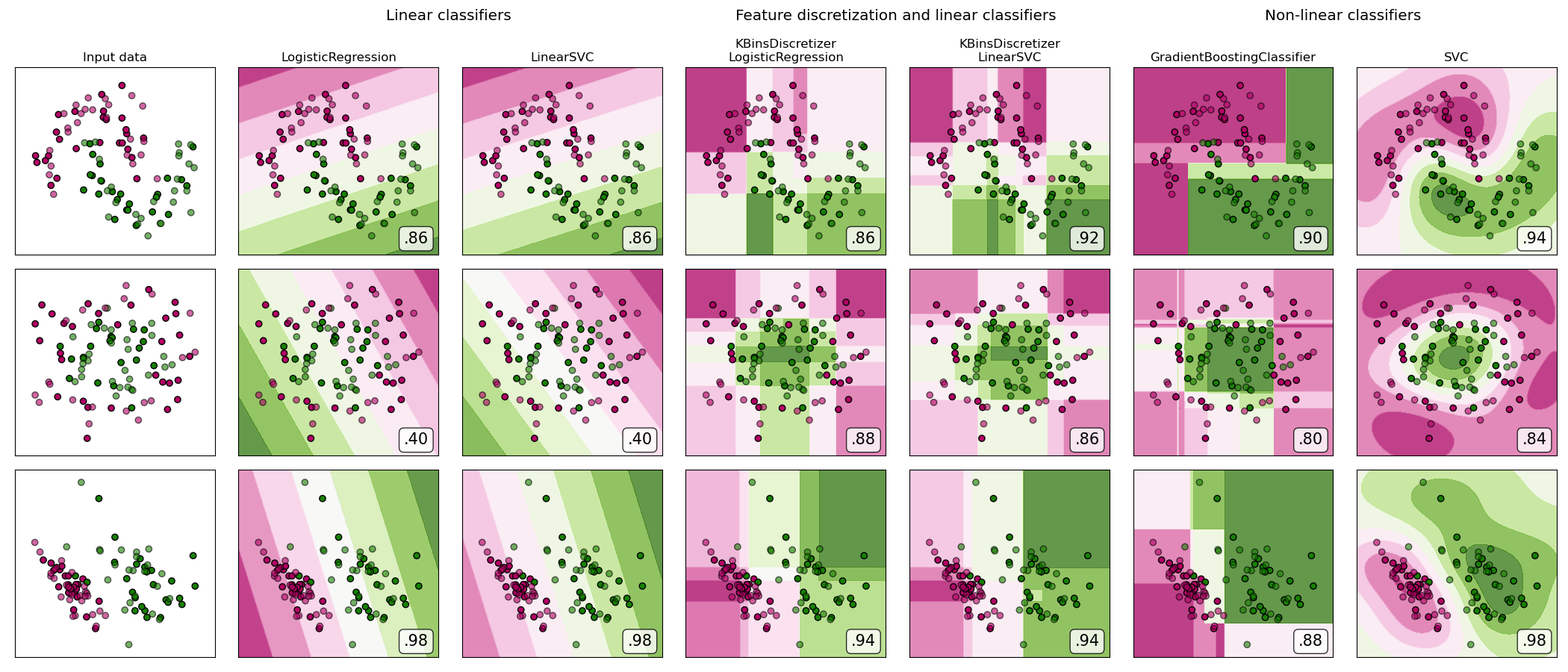
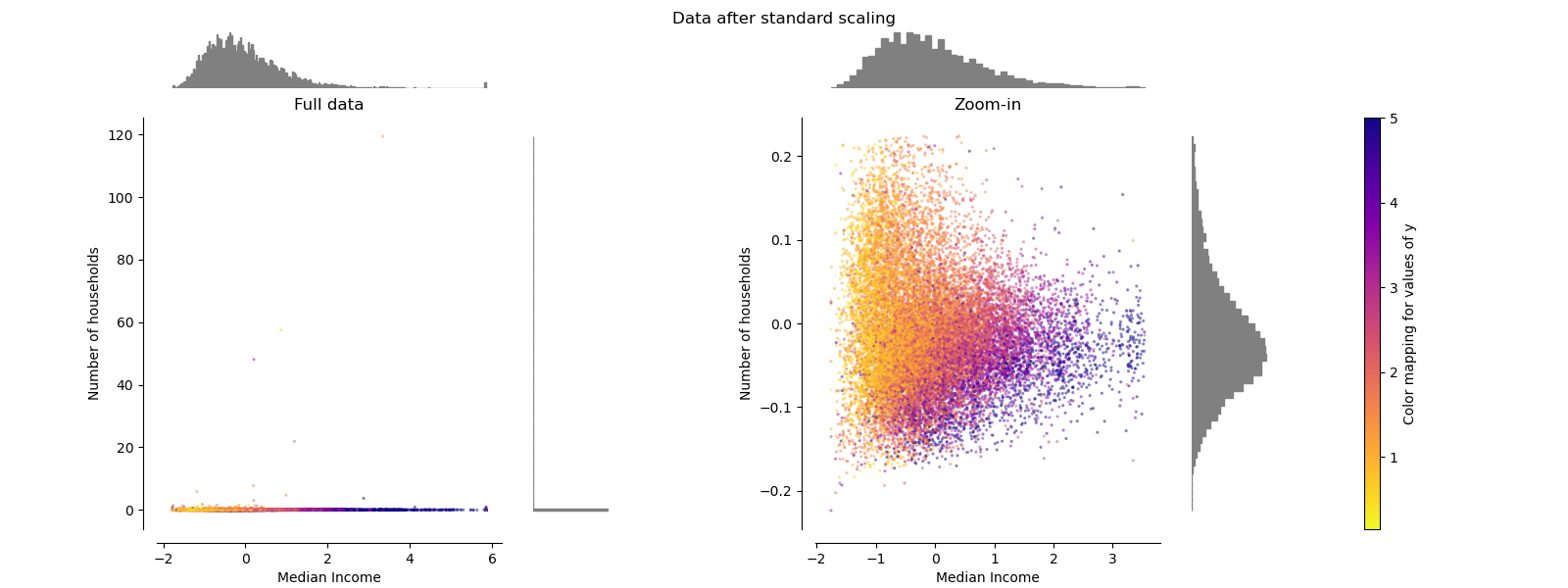
有關不同縮放器,轉換器和規范化器的比較,請參閱examples/preprocessing/plot_all_scaling.py。
示例
>>> from sklearn.preprocessing import StandardScaler
>>> data = [[0, 0], [0, 0], [1, 1], [1, 1]]
>>> scaler = StandardScaler()
>>> print(scaler.fit(data))
StandardScaler()
>>> print(scaler.mean_)
[0.5 0.5]
>>> print(scaler.transform(data))
[[-1. -1.]
[-1. -1.]
[ 1. 1.]
[ 1. 1.]]
>>> print(scaler.transform([[2, 2]]))
[[3. 3.]]
方法
| 方法 | 說明 |
|---|---|
fit(X[, y]) |
計算平均值和標準差,以用于以后的標度。 |
fit_transform(X[, y]) |
擬合數據,然后對其進行轉換。 |
get_params([deep]) |
獲取此估計量的參數。 |
inverse_transform(X[, copy]) |
將數據按比例縮小到原始表示形式 |
partial_fit(X[, y]) |
在線計算X上的均值和標準差,以便以后縮放。 |
set_params(**params) |
設置此估算器的參數。 |
transform(X[, copy]) |
通過居中和縮放執行標準化 |
__init__(*, copy=True, with_mean=True, with_std=True)
始化self,有關準確的簽名,請參見help(type(self))。
fit(X, y=None)
計算均值和標準差以用于以后的縮放。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix}, shape [n_samples, n_features] 用于計算平均值和標準偏差的數據,這些平均值和標準偏差用于以后沿特征軸縮放。 |
| y | None 忽略。 |
fit_transform(X, y=None, **fit_params)
擬合數據,然后對其進行轉換。
使用可選參數fit_params將轉換器擬合到X和y,并返回X的轉換版本。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目標值。 |
| **fit_params | dict 其他擬合參數。 |
| 返回值 | 說明 |
|---|---|
| X_new | ndarray array of shape (n_samples, n_features_new) 轉換后的數組。 |
get_params(deep=True)
獲取此估計量的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回此估算器和作為估算器的所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
inverse_transform(X, copy=None)
將數據按比例縮小到原始表示形式
| 參數 | 說明 |
|---|---|
| X | array-like, shape [n_samples, n_features] 用于沿要素軸縮放的數據。 |
| copy | bool, optional (default: None) 是否復制輸入X。 |
| 返回值 | 說明 |
|---|---|
| X_tr | array-like, shape [n_samples, n_features] 轉換后的數組。 |
partial_fit(X, y=None)
在線計算X上的均值和標準差,以便以后縮放。
所有X都作為一個批處理。這適用于由于n_sample數量過多或從連續流中讀取X而無法進行擬合的情況。
Chan,Tony F.,Gene H.Golub和Randall J.LeVeque的公式1.5a,b中給出了增量均值和std的算法。“計算樣本方差的算法:分析和建議。”美國統計學家37.3(1983):242-247:
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix}, shape [n_samples, n_features] 用于計算平均值和標準偏差的數據,這些平均值和標準偏差用于以后沿特征軸縮放。 |
| y | None 忽略。 |
| 返回值 | 說明 |
|---|---|
| self | object 變壓器實例。 |
set_params(**params)
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。后者的參數形式為<component>__<parameter>這樣就可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估算器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估算器實例。 |
transform(X, copy=None)
通過居中和縮放執行標準化
| 參數 | 說明 |
|---|---|
| X | array-like, shape [n_samples, n_features] 用于沿要素軸縮放的數據。 |
| 返回值 | 說明 |
|---|---|
| X_out | bool, optional (default: None) 是否復制輸入X。 |