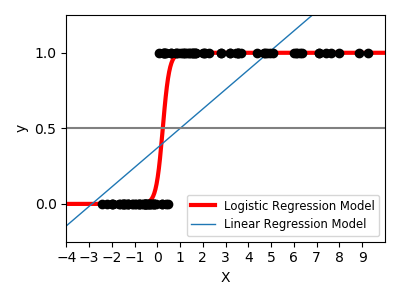
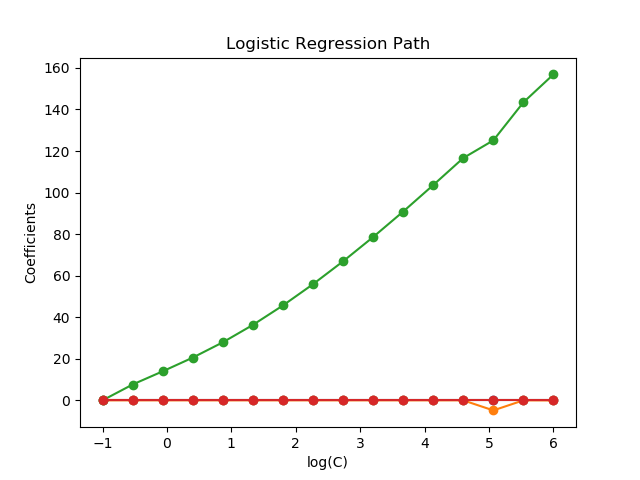
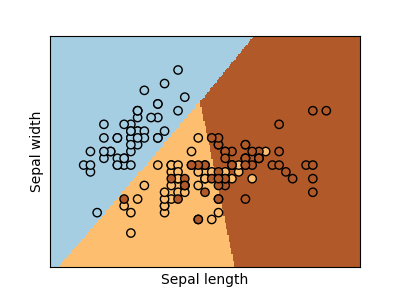
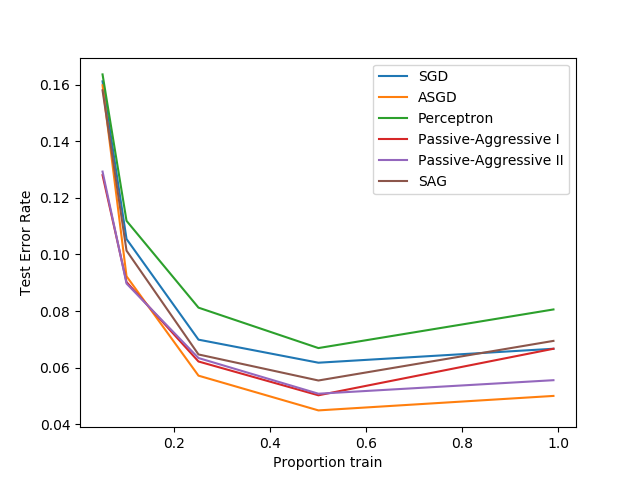
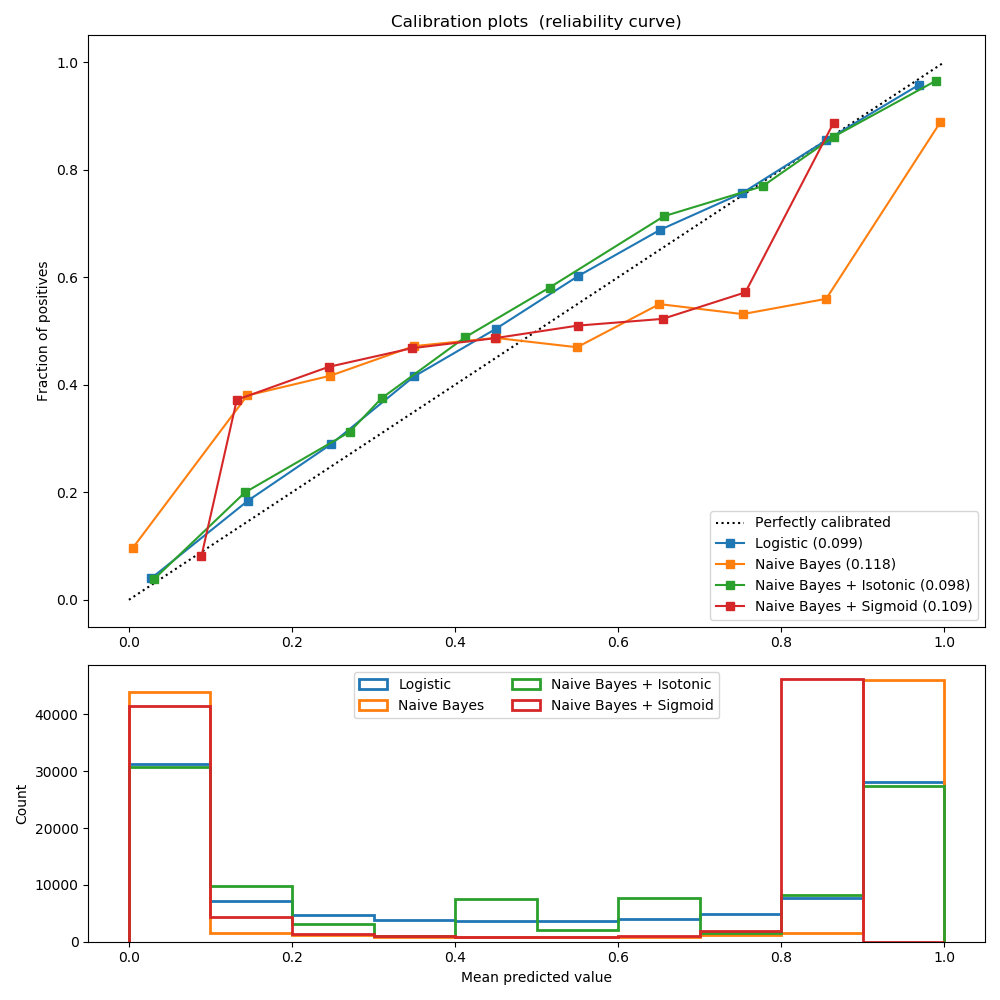
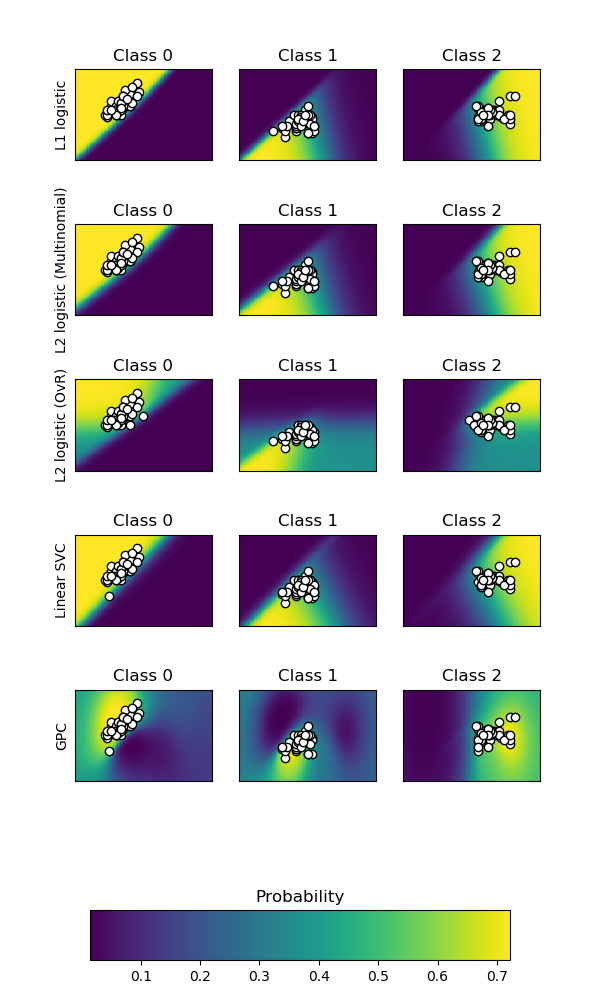
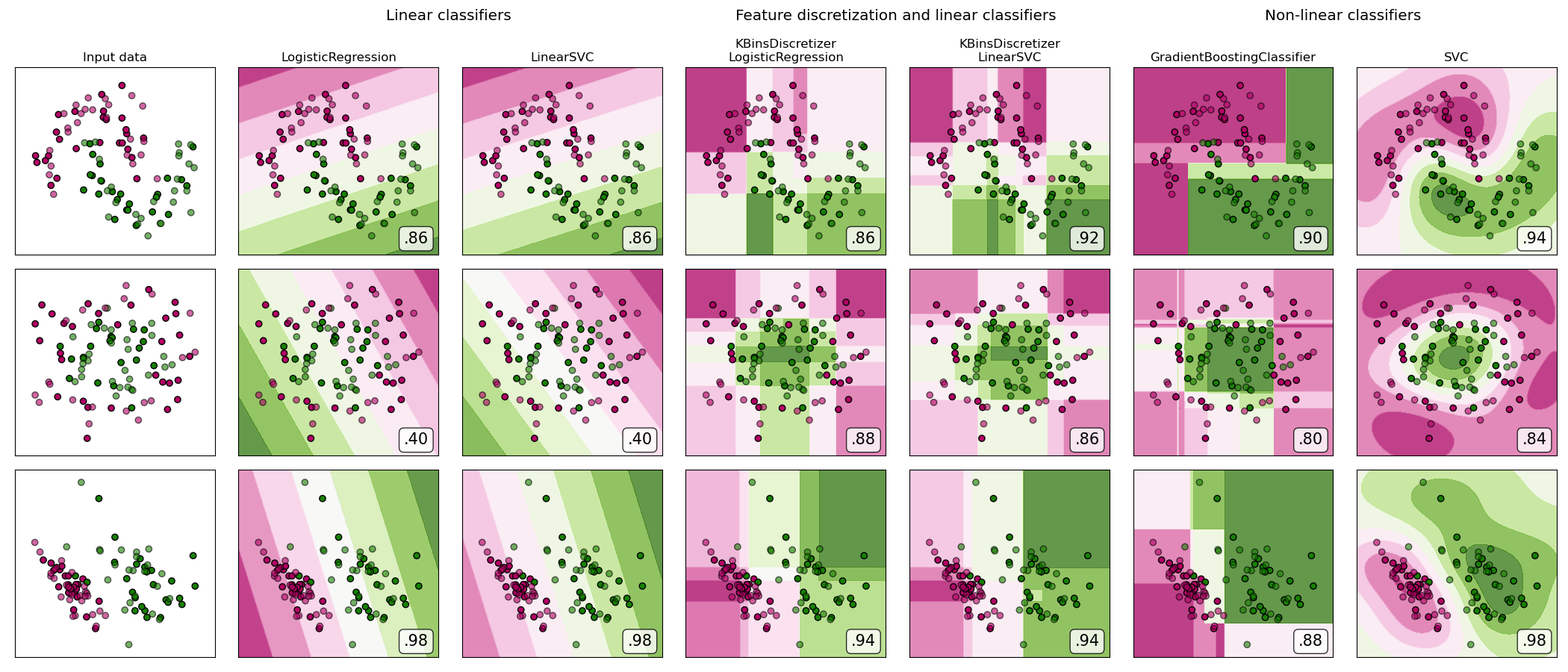
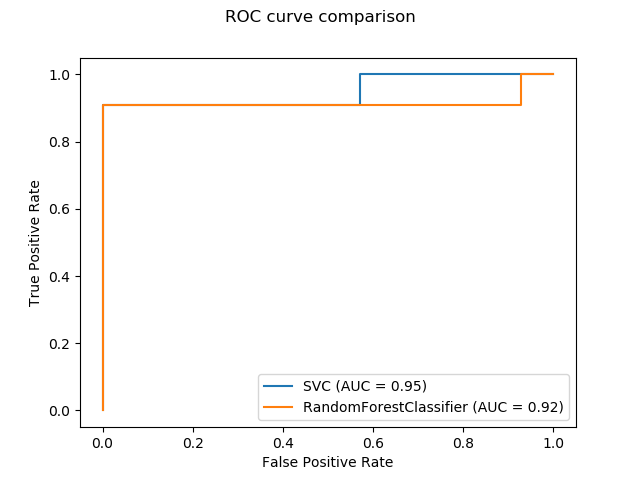
sklearn.linear_model.LogisticRegression?
class sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
Logistic回歸(又名logit,MaxEnt)分類器。
在多類情況下,如果將“ multi_class”選項設置為“ ovr”,則訓練算法將使用“一對剩余”(OvR)方案;如果將“ multi_class”選項設置為“multinomial(多項式)”,則使用交叉熵損失。(當前,只有“ lbfgs”,“ sag”,“ saga”和“ newton-cg”求解器支持“多項式”選項。)
此類使用'liblinear'庫,'newton-cg','sag','saga'和'lbfgs'求解器實現正則邏輯回歸。請注意,默認情況下將應用正則化。它可以處理密集和稀疏輸入。使用C排序數組或包含64位浮點數的CSR矩陣可獲得最佳性能;其他任何輸入格式將被轉換(并復制)。
“ newton-cg”,“ sag”和“ lbfgs”求解器支持帶有原始公式的L2正則化或不應用正則化。“ liblinear”求解器支持L1和L2正則化,僅針對L2罰分采用雙重公式。只有“ saga”求解器支持Elastic-Net正則化。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| penalty | {‘L1’, ‘L2’, ‘elasticnet’, ‘none’}, default=’L2’ 用于指定處罰中使用的規范。'newton-cg','sag'和'lbfgs'求解器僅支持L2懲罰。僅“ saga”求解器支持“ elasticnet”。如果為“ none”(liblinear求解器不支持),則不應用任何正則化。 版本0.19中的新功能: SAGA求解器的懲罰為L1(允許“multinomial” + L1) |
| dual | bool, default=False 是否對偶化。僅對liblinear求解器使用L2懲罰時進行對偶化。當n_samples> n_features時,首選dual = False。 |
| tol | float, default=1e-4 停止的容差標準。 |
| C | float, default=1.0 正則強度的倒數;必須為正浮點數。與支持向量機一樣,較小的值指定更強的正則化。 |
| fit_intercept | bool, default=True 是否將常量(aka偏置或截距)添加到決策函數。 |
| intercept_scaling | float, default=1 僅在使用求解器“ liblinear”并將self.fit_intercept設置為True時有用。在這種情況下,x變為[x,self.intercept_scaling],即將常量值等于intercept_scaling的“合成”特征附加到實例矢量。截距變為 intercept_scaling * synthetic_feature_weight注意!與所有其他特征一樣,合成特征權重也要經過L1 / L2正則化。為了減輕正則化對合成特征權重(以及因此對截距)的影響,必須增加intercept_scaling。 |
| class_weight | dict or ‘balanced’, default=None 以 {class_label: weight}的形式與類別關聯的權重。如果沒有給出,所有類別的權重都應該是1。“balanced”模式使用y的值來自動調整為與輸入數據中的類頻率成反比的權重。如 n_samples / (n_classes * np.bincount(y))請注意,如果指定了sample_weight,則這些權重將與sample_weight(通過fit方法傳遞)相乘 *0.17版中的新功能:*class_weight ='balanced' |
| random_state | int, RandomState instance, default=None 在 solver=='sag','saga'或'liblinear'時,用于隨機整理數據。有關詳細信息,請參見詞匯表。 |
| solver | {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=’lbfgs’ 用于優化問題的算法。 - 對于小型數據集,“ liblinear”是一個不錯的選擇,而對于大型數據集,“ sag”和“ saga”更快。 - 對于多類分類問題,只有'newton-cg' ,'sag','saga' 和 'lbfgs' 處理多項式損失。“ liblinear”僅限于“一站式”計劃。 - 'newton-cg','lbfgs','sag'和'saga'處理L2或不懲罰 - 'liblinear'和'saga'也可以處理L1罰款 - “ saga”還支持“ elasticnet”懲罰 - 'liblinear'不支持設置 penalty='none'請注意,只有在比例大致相同的要素上才能保證“ sag”和“ saga”快速收斂。您可以使用sklearn.preprocessing中的縮放器對數據進行預處理。 *版本0.17中的新功能:*隨機平均梯度下降求解器。 0.19版中的新功能: SAGA求解器。 在版本0.22中更改:默認求解器在0.22中從“ liblinear”更改為“ lbfgs”。 |
| max_iter | int, default=100 求解程序收斂的最大迭代次數。 |
| multi_class | {‘auto’, ‘ovr’, ‘multinomial’}, default=’auto’ 如果選擇的選項是“ ovr”,則每個標簽都看做二分類問題。對于“multinomial”,即使數據是二分類的,損失最小是多項式損失擬合整個概率分布。當solver ='liblinear' 時, 'multinomial' 不可用。如果數據是二分類的,或者如果Solver ='liblinear',則'auto'選擇'ovr',否則選擇'multinomial'。 *版本0.18中的新功能:*用于“多項式”情況的隨機平均梯度下降求解器。 *在版本0.22中更改:在版本0.22中,*默認值從'ovr'更改為'auto'。 |
| verbose | int, default=0 對于liblinear和lbfgs求解器,將verbose設置為任何正數以表示輸出日志的詳細程度。 |
| warm_start | bool, default=False 設置為True時,重用前面調用的解決方案來進行初始化,否則,只清除前面的解決方案。這個參數對于線性求解器無用。請參閱詞匯表。 0.17版中的新功能:**warm_start支持lbfgs,newton-cg,sag和saga求解器。 |
| n_jobs | int, default=None 當multi_class ='ovr'”,在對類進行并行化時使用的CPU內核數。將 solver設置為“ liblinear”時,無論是否指定“ multi_class” ,都將忽略此參數。除非設置了joblib.parallel_backend 參數,否則None表示1 。 -1表示使用所有處理器。有關更多詳細信息,請參見詞匯表。 |
| l1_ratio | float, default=None Elastic-Net混合參數,取值范圍 0 <= l1_ratio <= 1。僅在penalty='elasticnet'時使用。設置l1_ratio=0等同于使用penalty='l2',而設置l1_ratio=1等同于使用penalty='l1'。對于0 < l1_ratio <1,懲罰是L1和L2的組合。 |
| 屬性 | 說明 |
|---|---|
| classes_ | ndarray of shape (n_classes, ) 分類器已知的類別標簽列表。 |
| coef_ | ndarray of shape (1, n_features) or (n_classes, n_features) 決策函數中特征的系數。 coef_當給定問題為二分類時,其形狀為(1,n_features)。特別地,當時multi_class='multinomial',coef_對應于輸出1(真),并且-coef_對應于輸出0(假)。 |
| intercept_ | ndarray of shape (1,) or (n_classes,) 添加到決策函數的截距(也稱為偏差)。 如果 fit_intercept設置為False,則截距設置為零。 intercept_當給定問題為二分類時,其形狀為(1,)。特別地,當multi_class='multinomial'時,intercept_ 對應于結果1(真),并且-intercept_對應于結果0(假)。 |
| n_iter_ | ndarray of shape (n_classes,) or (1, ) 所有類的實際迭代數。如果是二分類或多項式,則僅返回1個元素。對于liblinear求解器,僅給出所有類的最大迭代次數。 *在0.20版中更改:*在SciPy <= 1.0.0中,lbfgs迭代次數可能超過 max_iter。n_iter_現在輸出最大的max_iter。 |
另見
逐步訓練的邏輯回歸(當指定參數時
loss="log")。具有內置交叉驗證的邏輯回歸。
注
底層的C實現使用一個隨機數生成器來選擇適合模型的特性。因此,對于相同的輸入數據,結果略有不同的情況并不少見。如果出現這種情況,嘗試使用較小的tol參數。
在某些情況下,預測輸出可能與獨立liblinear的輸出不匹配。請參見敘述文檔中與liblinear的區別。
參考
L-BFGS-B – Software for Large-scale Bound-constrained Optimization
Ciyou Zhu, Richard Byrd, Jorge Nocedal and Jose Luis Morales. http://users.iems.northwestern.edu/~nocedal/lbfgsb.html
LIBLINEAR – A Library for Large Linear Classification
https://www.csie.ntu.edu.tw/~cjlin/liblinear/
SAG – Mark Schmidt, Nicolas Le Roux, and Francis Bach
Minimizing Finite Sums with the Stochastic Average Gradient https://hal.inria.fr/hal-00860051/document
SAGA – Defazio, A., Bach F. & Lacoste-Julien S. (2014).
SAGA: A Fast Incremental Gradient Method With Support for Non-Strongly Convex Composite Objectives https://arxiv.org/abs/1407.0202
Hsiang-Fu Yu, Fang-Lan Huang, Chih-Jen Lin (2011). Dual coordinate descent
methods for logistic regression and maximum entropy models. Machine Learning 85(1-2):41-75. https://www.csie.ntu.edu.tw/~cjlin/papers/maxent_dual.pdf
示例
>>> from sklearn.datasets import load_iris
>>> from sklearn.linear_model import LogisticRegression
>>> X, y = load_iris(return_X_y=True)
>>> clf = LogisticRegression(random_state=0).fit(X, y)
>>> clf.predict(X[:2, :])
array([0, 0])
>>> clf.predict_proba(X[:2, :])
array([[9.8...e-01, 1.8...e-02, 1.4...e-08],
[9.7...e-01, 2.8...e-02, ...e-08]])
>>> clf.score(X, y)
0.97...
方法
| 方法 | 說明 |
|---|---|
decision_function(self, X) |
預測樣本的置信度得分。 |
densify(self) |
將系數矩陣轉換為密集數組格式。 |
fit(self, X, y[, sample_weight]) |
根據給定的訓練數據擬合模型。 |
get_params(self[, deep]) |
獲取此估計器的參數。 |
predict(self, X) |
預測X中樣本的類別標簽。 |
predict_log_proba(self, X) |
預測概率估計的對數。 |
predict_proba(self, X) |
概率估計。 |
score(self, X, y[, sample_weight]) |
返回給定測試數據和標簽上的平均準確度。 |
set_params(self, **params) |
設置此估計器的參數。 |
sparsify(self) |
將系數矩陣轉換為稀疏格式。 |
__init__(self, penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
初始化self, 請參閱help(type(self))以獲得準確的說明。
decision_function(self, X)
預測樣本的置信度得分。
樣本的置信度分數是該樣本到超平面的符號距離。
| 參數 | 說明 |
|---|---|
| X | array_like or sparse matrix, shape (n_samples, n_features) 樣本。 |
| 返回值 | 說明 |
|---|---|
| array, shape=(n_samples,) if n_classes == 2 else (n_samples, n_classes) 每個(樣本,類別)組合的置信度得分。在二分類情況下,self.classes_ [1]的置信度得分> 0表示將預測該類。 |
densify(self)
將系數矩陣轉換為密集數組格式。
將coef_數值(返回)轉換為numpy.ndarray。這是coef_的默認格式,并且是擬合模型所需的格式,因此僅在之前被稀疏化的模型上才需要調用此方法。否則,它是無操作的。
| 返回值 | 說明 |
|---|---|
| self | 擬合估計器。 |
fit(self,X,y,sample_weight = None )
根據給定的訓練數據擬合模型。
| 參數 | 說明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 訓練數據,其中n_samples是樣本數,n_features是特征數。 |
| y | array-like of shape (n_samples,) 對應于X的目標向量。 |
| sample_weight | array-like of shape (n_samples,) default=None 分配給各個樣本的權重數組。如果未設置,則為每個樣本的權重都為1。 0.17版中的新功能:sample_weight支持LogisticRegression。 |
| 返回值 | 說明 |
|---|---|
| self | 擬合估計器。 |
注
SAGA求解器支持float64和float32位數組。
get_params(self,deep = True )
獲取此估計器的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,返回此估計器和所包含子對象的參數。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
predict(self, X)
預測X中樣本的類別標簽。
| 參數 | 說明 |
|---|---|
| X | array_like or sparse matrix, shape (n_samples, n_features) 樣本數據 |
| 返回值 | 說明 |
|---|---|
| C | array, shape [n_samples] 每個樣本的預測類別標簽。 |
predict_log_proba(self, X)
預測概率估計的對數。
返回按類別標簽排序的所有類別的估計值。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 要預測的數據,其中 n_samples是樣本數, n_features是特征數。 |
| 返回值 | 說明 |
|---|---|
| T | array-like of shape (n_samples, n_classes) 返回模型中每個類別的樣本的對數概率,按 self.classes_中類別的順序排序。 |
predict_proba(self, X)
概率估計。
返回按類別標簽排序的所有類別的估計值。
對于multi_class問題,如果將multi_class設置為“multinomial”,則使用softmax函數查找每個類別的預測概率。否則使用one vs-rest方法,即使用logistic函數計算每個類別為正的概率。并在所有類別中標準化這些值。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 要預測的數據,其中 n_samples是樣本數, n_features是特征數。 |
| 返回值 | 說明 |
|---|---|
| T | array-like of shape (n_samples, n_classes) 返回模型中每個類別的樣本概率,類按 self.classes_中的順序排序。 |
score(self, X, y, sample_weight=None)
返回給定測試數據和標簽上的平均準確度。
在多標簽分類中,這是子集準確性,這是一個嚴格的指標,因為你需要為每個樣本正確預測標簽集。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 測試樣本。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真實標簽。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重。 |
| 返回值 | 說明 |
|---|---|
| score | float 預測標簽與真實標簽的平均準確度 |
set_params(self, **params)
設置此估算器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如管道)。后者具有形式參數 <component>__<parameter>,以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估計器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估計器實例。 |
sparsify(self)
將系數矩陣轉換為稀疏格式。
將coef_數值轉換為scipy.sparse矩陣,對于L1正規化的模型,該矩陣比通常的numpy.ndarray具有更高的內存和存儲效率。
該intercept_數值未轉換。
| 返回值 | 說明 |
|---|---|
| self | 擬合估計器。 |
注
對于非稀疏模型,即當coef_中零的個數不多時,這實際上可能會增加內存使用量,因此請謹慎使用此方法。經驗法則是,可以使用(coef_ == 0).sum()計算得到的零元素的數量必須大于50%,這時的效果是顯著的。
在調用densify之前,調用此方法將無法進一步使用partial_fit方法(如果有)。