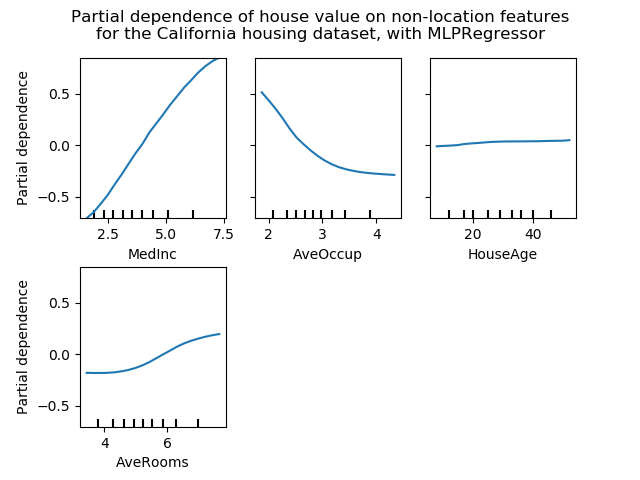
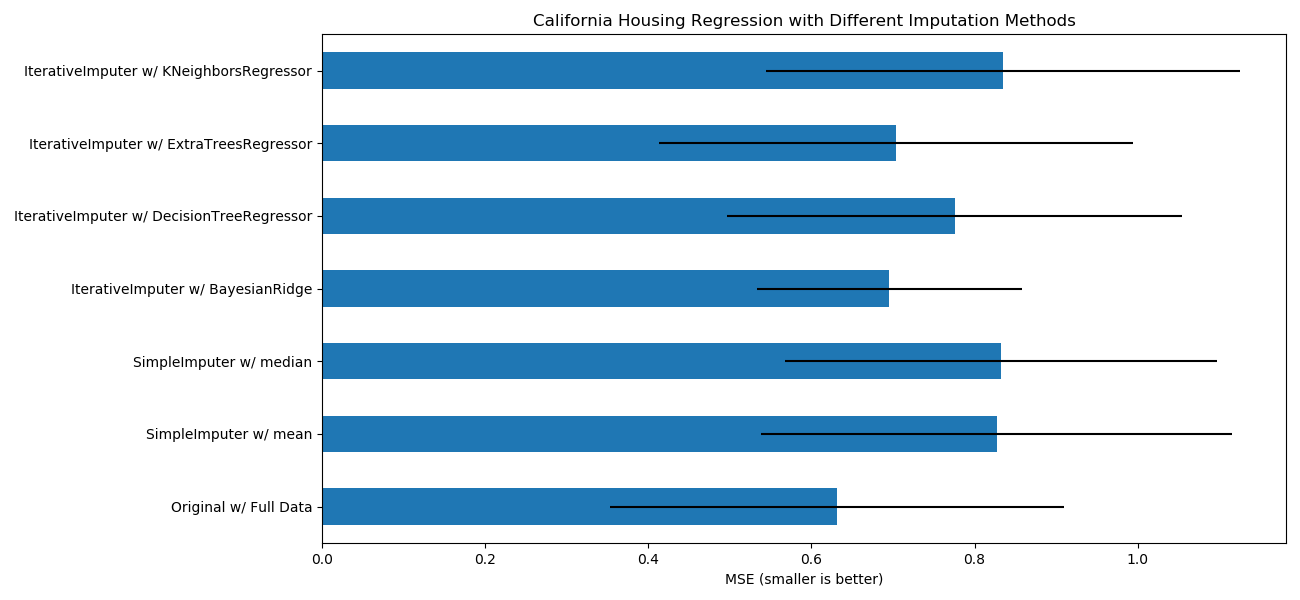
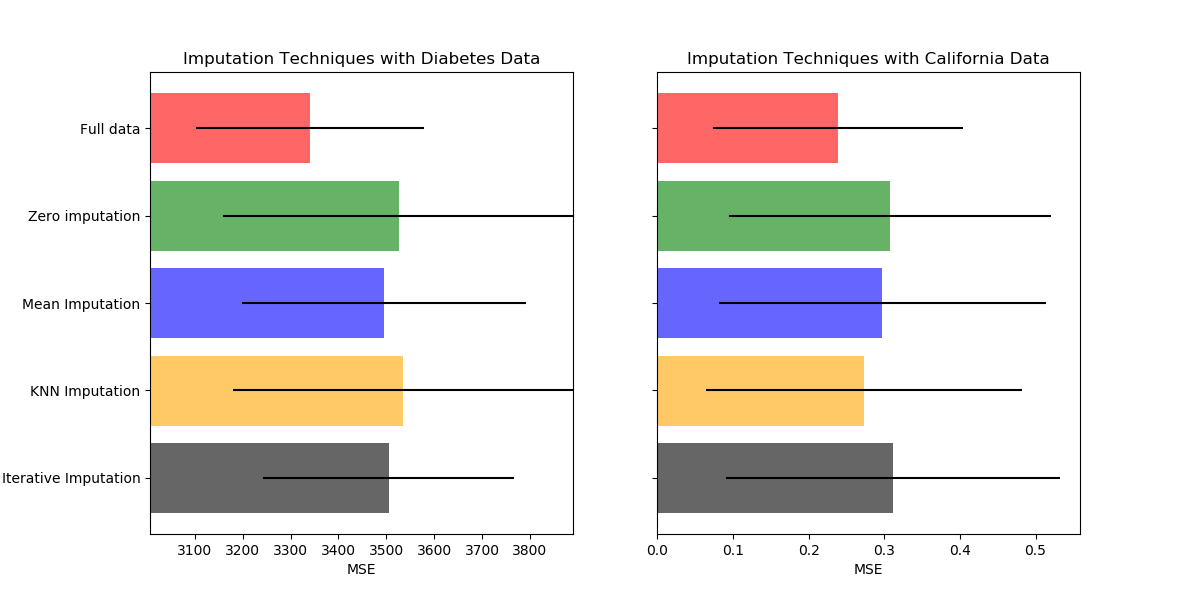
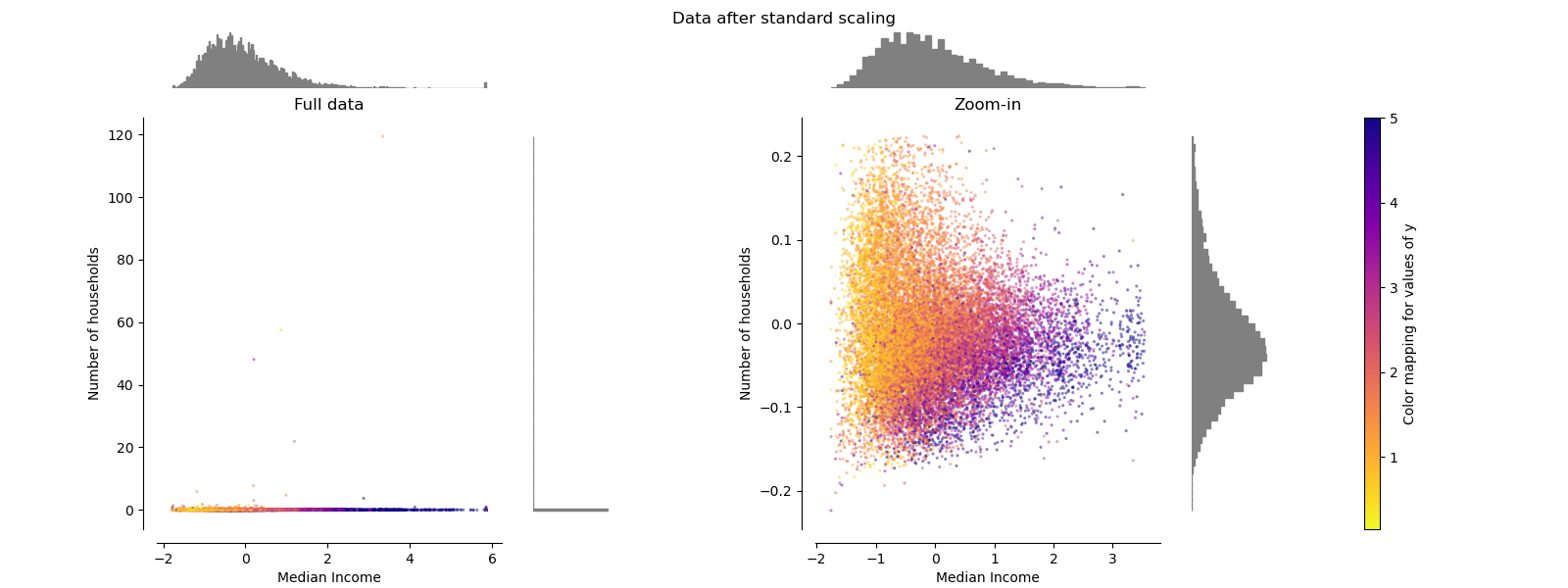
sklearn.datasets.fetch_california_housing?
sklearn.datasets.fetch_california_housing(*, data_home=None, download_if_missing=True, return_X_y=False, as_frame=False)
加載加利福尼亞住房數據集(回歸)。
| 樣本總數 | 20640 |
|---|---|
| 維度 | 8 |
| 特征 | real |
| target | real 0.15 - 5. |
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| data_home | optional, default: None 為數據集指定另一個下載和緩存文件夾。默認情況下,所有scikit-learn數據都存儲在“?/ scikit_learn_data”子文件夾中。 |
| download_if_missing | optional, default=True 如果為False,則在數據不在本地可用時引發IOError,而不是嘗試從源站點下載數據。 |
| return_X_y | boolean, default=False 如果為True,則返回(data.data,data.target)而不是Bunch對象。 0.20版中的新功能。 |
| as_frame | boolean, default=False 如果為True,則數據為pandas DataFrame,其中包含具有適當dtypes(numeric, string 或 categorical)的列。 target是pandas DataFrame還是Series,取決于target_columns的數量。 0.23版中的新功能。 |
| 返回值 | 說明 |
|---|---|
| dataset | Bunch類字典對象,具有以下屬性。 - data: ndarray, shape (20640, 8) 每行依次對應8個特征值。 如果as_frame為True,則data為pandas對象。 - target: numpy array of shape (20640,) 每個值對應于以100,000為單位的平均房屋價值。 如果as_frame為True,則target為pandas對象。 - feature_names: list of length 8 數據集中使用的有序要素名稱的數組。 - DESCR: string 加州住房數據集的描述。 |
| (data, target) | tuple if return_X_y is True0.20版中的新功能。 |
| frame | pandas DataFrame 僅在as_frame = True時存在。 具有data和target的DataFrame。 0.23版中的新功能。 |
注
該數據集包含20,640個樣本和9個特征。