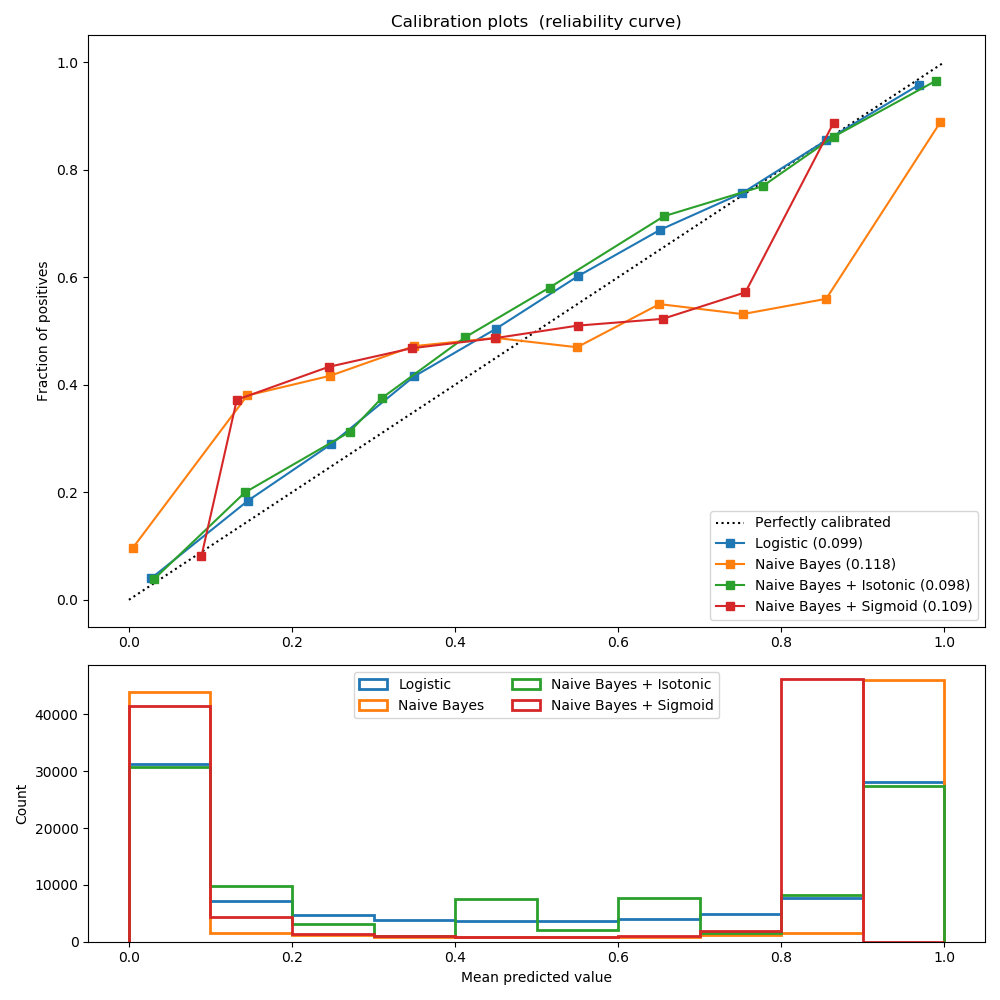
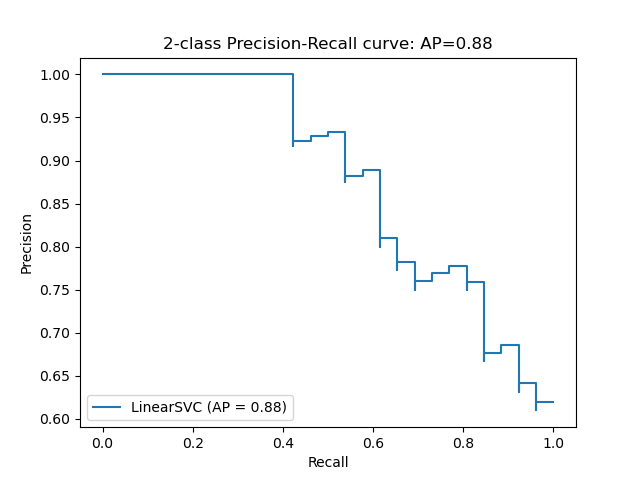
sklearn.metrics.recall_score?
sklearn.metrics.recall_score(y_true, y_pred, *, labels=None, pos_label=1, average='binary', sample_weight=None, zero_division='warn')
計算召回率
召回率是tp /(tp + fn)的比率,其中tp是真正例的數目,fn是假負例的數目。 直觀上,召回率是分類器找到所有正例樣本的能力。
最佳值為1,最差值為0。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| y_true | 1d array-like, or label indicator array / sparse matrix 真實目標值。 |
| y_pred | 1d array-like, or label indicator array / sparse matrix 分類器返回的估計目標。 |
| labels | list, optional 當average!='binary'時要包括的一組標簽,如果average是None,則是標簽的順序。可以排除數據中存在的標簽,例如,以忽略多數否定類的方式計算多類平均值,而數據中不存在的標簽將導致宏平均值中的0成分。對于多標簽目標,標簽是列索引。 默認情況下,y_true和y_pred中的所有標簽均按排序順序使用。 在版本0.17中進行了更改:針對多類問題改進了參數標簽。 |
| pos_label | str or int, 1 by default average ='binary'且數據為二進制的報告類。如果數據是多類或多標簽的,則將被忽略; 設置labels=[pos_label]和average!='binary'將僅報告該標簽的分數。 |
| average | string, [None|‘binary’ (default)| ‘micro’| ‘macro’| ‘samples’|‘weighted’] 對于多類/多標簽目標,此參數是必需的。如果為None,則返回每個類的得分。否則,將根據數據的平均表現確定類型: - 'binary':僅報告由pos_label指定的類的結果。僅當目標(y_ {true,pred})為二進制時才適用。 - 'micro':通過計算真正例、假負例和假正例的總數來全局計算度量。 - 'macro':計算每個標簽的度量,并找到其未加權平均值。 這沒有考慮標簽不平衡。 - 'weighted':計算每個標簽的度量,并找到它們受支持的平均權重(每個標簽的真實實例數)。這會更改‘macro’以解決標簽不平衡的問題;這可能導致F-score不在精確度和召回率之間。 - 'samples':計算每個實例的度量,并找到它們的平均值(僅對不同于 accuracy_score的多標簽分類有意義)。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重。 |
| zero_division | “warn”, 0 or 1, default=”warn” 設置零分頻時返回的值。如果設置為“ warn”,則該值為0,但也會發出警告。 |
| 返回值 | 說明 |
|---|---|
| recall | float (if average is not None) or array of float, shape = [n_unique_labels] 二進制分類中的正例類的召回率或多類別任務的每個類別的召回率加權平均。 |
另見:
注
當真正例+假負例== 0時,召回率返回0并引發UndefinedMetricWarning。可以使用zero_division修改此行為。
示例
>>> from sklearn.metrics import recall_score
>>> y_true = [0, 1, 2, 0, 1, 2]
>>> y_pred = [0, 2, 1, 0, 0, 1]
>>> recall_score(y_true, y_pred, average='macro')
0.33...
>>> recall_score(y_true, y_pred, average='micro')
0.33...
>>> recall_score(y_true, y_pred, average='weighted')
0.33...
>>> recall_score(y_true, y_pred, average=None)
array([1., 0., 0.])
>>> y_true = [0, 0, 0, 0, 0, 0]
>>> recall_score(y_true, y_pred, average=None)
array([0.5, 0. , 0. ])
>>> recall_score(y_true, y_pred, average=None, zero_division=1)
array([0.5, 1. , 1. ])