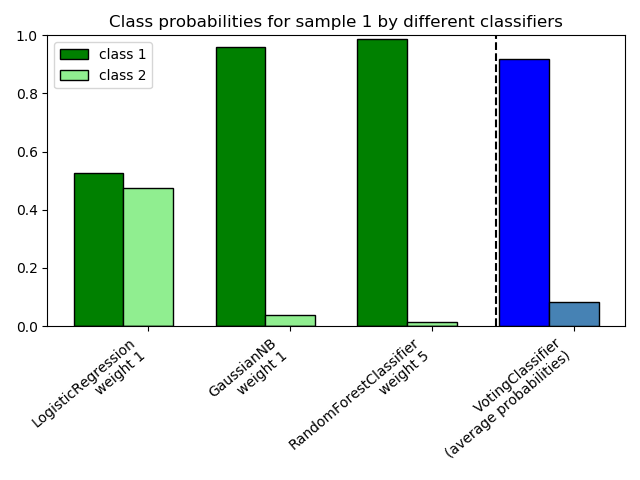
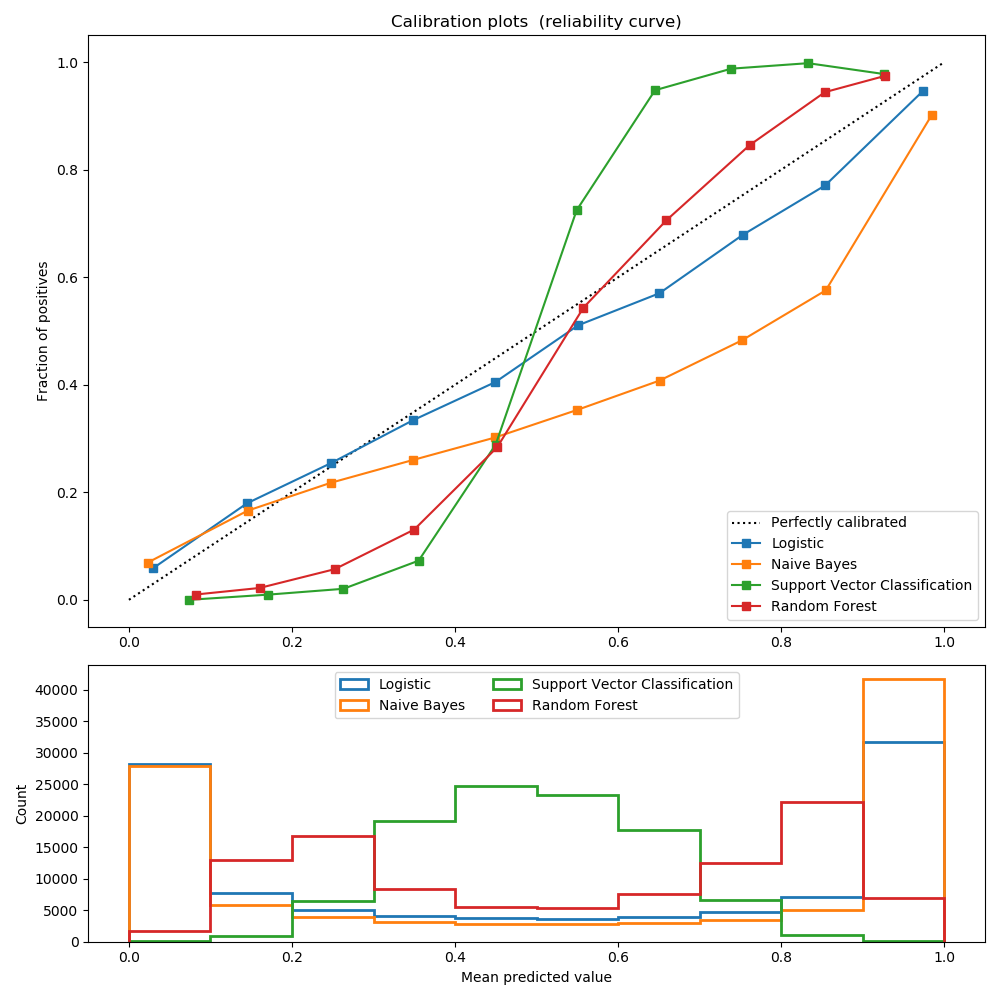
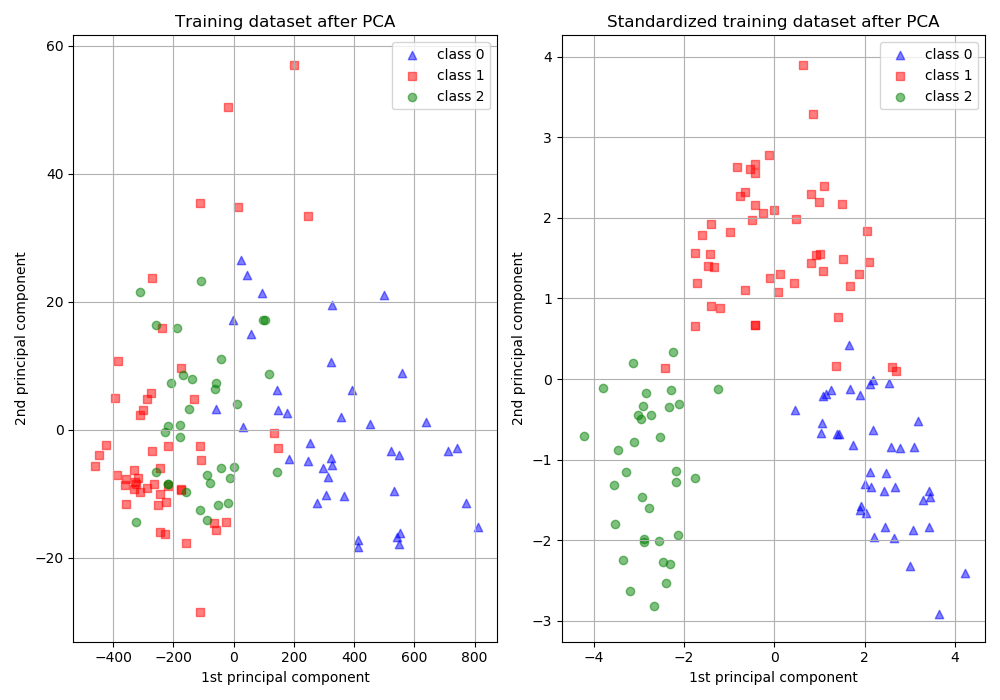
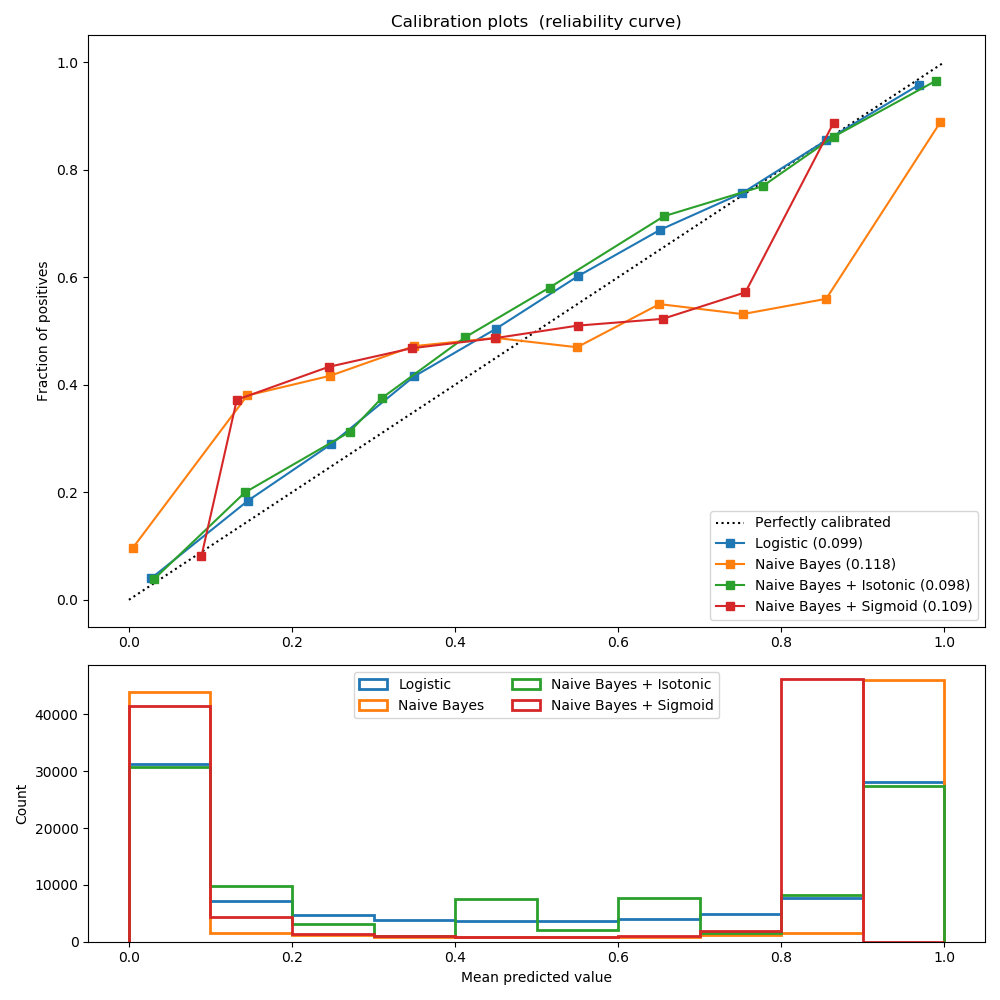
sklearn.naive_bayes.GaussianNB?
class sklearn.naive_bayes.GaussianNB(*, priors=None, var_smoothing=1e-09)
[源碼]
高斯樸素貝葉斯(GaussianNB)
可以在線更新模型參數partial_fit。有關用于在線更新特征均值和方差的算法的詳細信息,請參閱Chan,Golub和LeVeque撰寫的Stanford CS技術報告STAN-CS-79-773:
http://i.stanford.edu/pub/cstr/reports/cs/tr/79/773/CS-TR-79-773.pdf
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| priors | array-like of shape (n_classes,) 類別的先驗概率。一經指定,不會根據數據進行調整。 |
| var_smoothing | float, default=1e-9 所有特征的最大方差部分,添加到方差中用于提高計算穩定性。 0.20版中的新功能。 |
| 屬性 | 說明 |
|---|---|
| class_count_ | ndarray of shape (n_classes,) 每個類別中保留的訓練樣本數量。 |
| class_prior_ | ndarray of shape (n_classes,) 每個類別的概率。 |
| classes_ | ndarray of shape (n_classes,) 分類器已知的類別標簽 |
| epsilon_ | float 方差的絕對相加值 |
| sigma_ | ndarray of shape (n_classes, n_features) 每個類中每個特征的方差 |
| theta_ | ndarray of shape (n_classes, n_features) 每個類中每個特征的均值 |
示例
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> Y = np.array([1, 1, 1, 2, 2, 2])
>>> from sklearn.naive_bayes import GaussianNB
>>> clf = GaussianNB()
>>> clf.fit(X, Y)
GaussianNB()
>>> print(clf.predict([[-0.8, -1]]))
[1]
>>> clf_pf = GaussianNB()
>>> clf_pf.partial_fit(X, Y, np.unique(Y))
GaussianNB()
>>> print(clf_pf.predict([[-0.8, -1]]))
[1]
方法
| 方法 | 說明 |
|---|---|
fit(X, y[, sample_weight]) |
根據X,y擬合高斯樸素貝葉斯 |
get_params([deep]) |
獲取這個估計器的參數 |
partial_fit(X, y[, classes, sample_weight]) |
對一批樣本進行增量擬合 |
predict(X) |
對測試向量X進行分類。 |
predict_log_proba(X) |
返回針對測試向量X的對數概率估計 |
predict_proba(X) |
返回針對測試向量X的概率估計 |
score(X, y[, sample_weight]) |
返回給定測試數據和標簽上的平均準確率。 |
set_params(**params) |
為這個估計器設置參數 |
__init__(*, priors=None, var_smoothing=1e-09)
[源碼]
初始化self。詳情可參閱 type(self)的幫助。
fit(X, y, sample_weight=None)
[源碼]
根據X,y擬合高斯樸素貝葉斯
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 用于訓練的向量,其中n_samples是樣本數量,n_features是特征數量。 |
| y | array-like of shape (n_samples,) 目標值。 |
| sample_weight | array-like of shape (n_samples,), default=None 應用于單個樣本的權重(1.未加權)。 版本0.17中的新功能:高斯樸素貝葉斯支持使用sample_weight進行擬合。 |
| 返回值 | 說明 |
|---|---|
| self | object |
get_params(deep=True)
[源碼]
獲取這個估計器的參數
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回這個估計器的參數和所包含的估計器子對象。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名映射到其值 |
partial_fit(X, y, classes=None, sample_weight=None)
[源碼]
對一批樣本進行增量擬合
方法需要對數據集的不同塊連續調用多次,以實現核外學習或在線學習。
當整個數據集太大而無法立即放入內存擬合時,這個功能特別有用。
這個方法具有一些性能消耗,因此最好對盡可能大的數據塊(只要適合內存預算)調用partial_fit以隱藏消耗。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 用于訓練的向量,其中n_samples是樣本數量,n_features是特征數量。 |
| y | array-like of shape (n_samples,) 目標值。 |
| classes | array-like of shape (n_classes,), default=None y向量中可能出現的所有類別的列表。 必須在第一次調用partial_fit時提供,在隨后的調用中可以省略。 |
| sample_weight | array-like of shape (n_samples,), default=None 應用于單個樣本的權重(1.未加權)。 版本0.17中的新功能。 |
| 返回值 | 說明 |
|---|---|
| self | object |
predict(X)
[源碼]
對測試向量X進行分類。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) |
| 返回值 | 說明 |
|---|---|
| C | ndarray of shape (n_samples,) X的預測目標值 |
predict_log_proba(X)
[源碼]
返回針對測試向量X的對數概率估計
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) |
| 返回值 | 說明 |
|---|---|
| C | array-like of shape (n_samples, n_classes) 返回模型中每個類別的樣本的對數概率。這些列按照排序順序對應于類別,就像它們出現在屬性classes_中一樣。 |
predict_proba(X)
[源碼]
返回針對測試向量X的概率估計
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) |
| 返回值 | 說明 |
|---|---|
| C | array-like of shape (n_samples, n_classes) 返回模型中每個類別的樣本概率。這些列按照排序順序對應于類別,就像它們出現在屬性classes_中一樣。 |
score(X, y, sample_weight=None)
[源碼]
返回給定測試數據和標簽上的平均準確率。
在多標簽分類中,這是子集準確性,這是一個嚴格的指標,因為您需要為每個樣本正確預測每個標簽集。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 測試樣本 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真實標簽。 |
| sample_weight | array-like of shape (n_samples,), default=None 樣本權重 |
| 返回值 | 說明 |
|---|---|
| score | float self.predict(X)關于y的平均準確率 |
set_params(**params)
[源碼]
為這個估計器設置參數
該方法適用于簡單的估計器以及嵌套對象(例如pipelines)。后者具有形式參數<component>__<parameter>,以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估計器參數 |
| 返回值 | 說明 |
|---|---|
| self | object 估計器實例 |