2.7. 奇異值和異常值檢測?
許多應用程序要有能力判斷新觀測值是否與現有觀測值具有相同的分布(它是一個內點(inlier)),或者應該被認為是不同的(它是一個離群值)。通常,這種能力被用于清理實際數據集, 必須做出兩種重要區分:
| 離群點檢測: | 訓練數據包含離群點,這些離群點被定義為遠離其它內圍點的觀察值。因此,離群點檢測估計器會嘗試擬合出訓練數據中內圍點聚集的區域, 而忽略異常值觀察。 |
|---|---|
| 奇異值檢測: | 訓練數據沒有受到離群點污染,我們感興趣的是檢測一個新的觀測值是否為離群點。在這種情況下,離群點被認為是奇異值。 |
離群點檢測和奇異值檢測都用于異常檢測, 其中一項感興趣的是檢測異常或異常觀察。離群點檢測又被稱之為無監督異常檢測,奇異值檢測又被稱之為半監督異常檢測。 在。相反的,在奇異值檢測的背景下,奇異值/異常點只要位于訓練數據的低密度區域,是可以形成稠密聚類簇的,在此背景下被認為是正常的。
scikit-learn項目提供了一組機器學習工具,可用于新穎性或離群值檢測。通過以無監督的方式從數據中學習對象來實現此策略:
estimator.fit(X_train)
然后可以使用以下predict方法將新觀察值分類為離群點或內圍點 :
estimator.predict(X_test)
內圍點標記為1,而離群點標記為-1。預測方法利用了估計器計算的原始評分函數的閾值。通過該score_samples 可以訪問此評分函數,而閾值可以由contamination 參數控制。
decision_function還通過評分函數定義該方法,以使負值是離群點,而非負值不是離群點:
estimator.decision_function(X_test)
請注意 neighbors.LocalOutlierFactor 類默認不支持 predict, decision_function 和 score_samples 方法,而只支持 fit_predict 方法, 因為這個估計器從本來就是被用到離群點檢測中去的。可以通過 negative_outlier_factor_屬性來獲取訓練樣本的異常性得分。
如果您真的想把neighbors.LocalOutlierFactor用于奇異值檢測,即預測新的樣本標簽或計算新的未知數據的異常分數,則可以在擬合估計器之前把novelty參數設置為True。在這種情況下,fit_predict不可用。
警告 :使用局部離群因子進行奇異值檢測
當
novelty參數設置為 True 時,在新的未見過的數據上,你只能使用predict,decision_function和score_samples,而不能用在訓練數據上, 因為會導致錯誤的結果。訓練樣本的異常性得分始終可以通過negative_outlier_factor_屬性獲取。
neighbors.LocalOutlierFactor下表中總結了離群點檢測和奇異值檢測中的行為。
| 方法 | 離群點檢測 | 新穎性檢測 |
|---|---|---|
fit_predict |
可用 | 無法使用 |
predict |
無法使用 | 僅用于新數據 |
decision_function |
無法使用 | 僅用于新數據 |
score_samples |
采用 negative_outlier_factor_ |
僅用于新數據 |
2.7.1. 離群點檢測方法一覽
比較scikit-learn中的離群點檢測算法。局部離群點因子(Local Outlier Factor, LOF)并沒有顯示黑色的決策邊界,因為當它用于離群點檢測時,它沒有適用于新數據的 predict 方法。
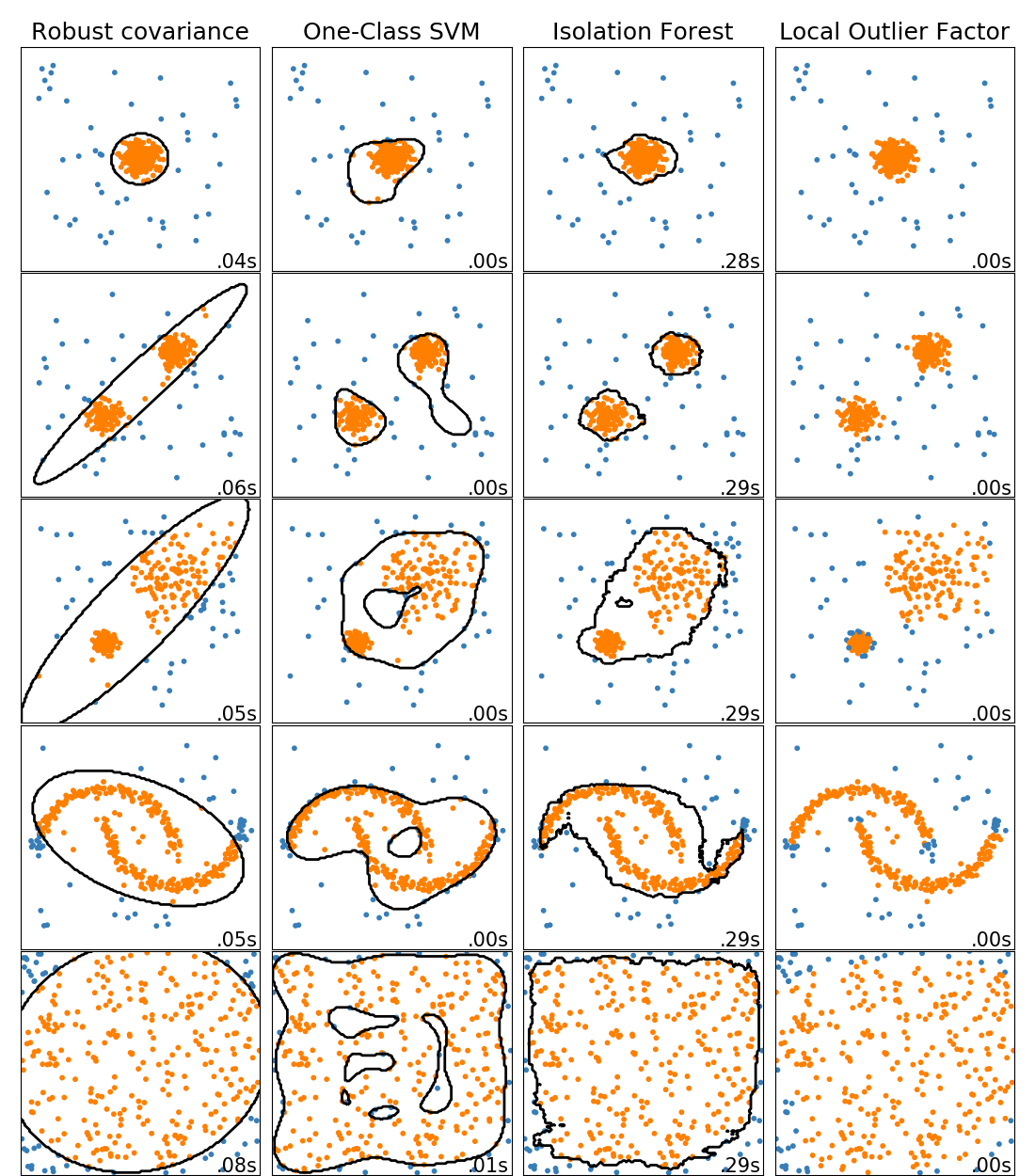
ensemble.IsolationForest和neighbors.LocalOutlierFactor 在此處用到的數據集上表現很好。svm.OneClassSVM被認為對離群點敏感并因此對離群點檢測執行的不是很好。最后, covariance.EllipticEnvelope假設數據服從高斯分布并學習一個橢圓。有關不同估計器的更多詳細信息,請參閱示例 玩具數據集異常檢測算法的比較研究以及以下各節。
示例:
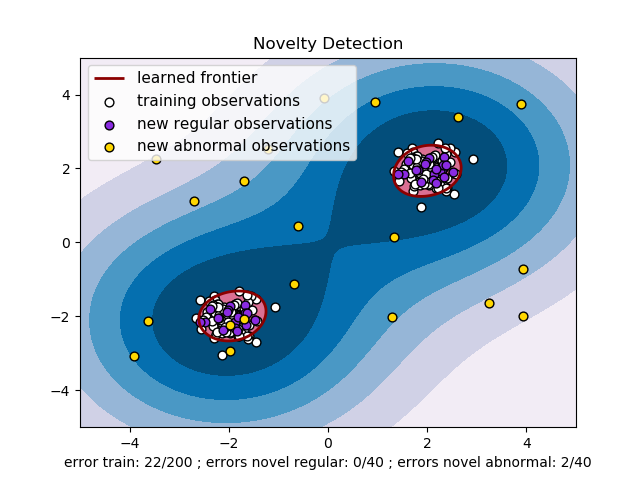
2.7.2. Novelty Detection(奇異值檢測)
考慮一個由 個特征描述的相同分布的 個觀測的數據集。 現在考慮我們在這個數據集中再增加一個觀測值。 這個新觀測是否與其他的觀測值有很大差異,我們就可以懷疑它是否是常規值 (即它否來自相同的分布?)或者相反,如果新觀測與原有觀測非常相似以至于我們就無法將其與原有觀測值分開? 這是奇異值檢測工具和方法所解決的問題。
一般來說,它是要學習出一個粗略的、封閉的邊界劃定出初始觀測分布的輪廓,繪制在嵌入的 維空間中。然后,如果進一步的觀測值位于這個邊界劃分的子空間內,則認為它們來自與初始觀測值來自同一處。 否則,如果它們位于邊界之外,我們就可以說根據我們評估給定的置信度而言,它們是異常的。
Sch?lkopf 等人已經采用One-Class SVM(單類支持向量機)來實現新奇檢測,并在屬于 支持向量機 模塊的 svm.OneClassSVM 對象中實現。 它需要選擇一個 kernel 和 scalar 參數來定義邊界。 雖然沒有精確的公式或算法來設置RBF核的帶寬參數,但通常選擇RBF核。這是scikit-learn實現中的默認設置。參數 ,也稱為單類支持向量機的邊沿,對應于在邊界之外找到新的但常規的觀測值的概率。
參考資料:
Estimating the support of a high-dimensional distribution Sch?lkopf, Bernhard, et al. Neural computation 13.7 (2001): 1443-1471. 示例:
參考 一類非線性核支持向量機(RBF) ,通過 svm.OneClassSVM對象學習一些數據來將邊界可視化。物種分布模型
2.7.3. Outlier Detection(離群點檢測)
離群點檢測與新奇性檢測類似,其目的是將常規觀測的核心數據與被稱為離群點的污染數據分離開來。然而,在離群點檢測的情況下,我們沒有一個清晰的數據集來表示常規觀測的總體,這些數據集可以用來訓練任何工具。
2.7.3.1. Fitting an elliptic envelope(橢圓模型擬合)
執行離群值檢測的一種常見方法是假設常規數據來自一個已知分布(例如數據是高斯分布的)。根據這一假設,我們一般嘗試定義數據的“形狀”,并可以將邊緣觀測定義為距離擬合形狀足夠遠的觀測值。
scikit-learn 提供了 covariance.EllipticEnvelope對象,橢圓包絡線,它對數據進行穩健的協方差估計,從而對中心數據點進行擬合出一個橢圓,忽略中心模式之外的點。
例如,假設內部數據是高斯分布的,它將以一種可靠的方式(即不受離群值的影響)估算離群位置和協方差。從這個估計值得到的馬氏距離用來得出離群度的度量。這個策略如下所示。
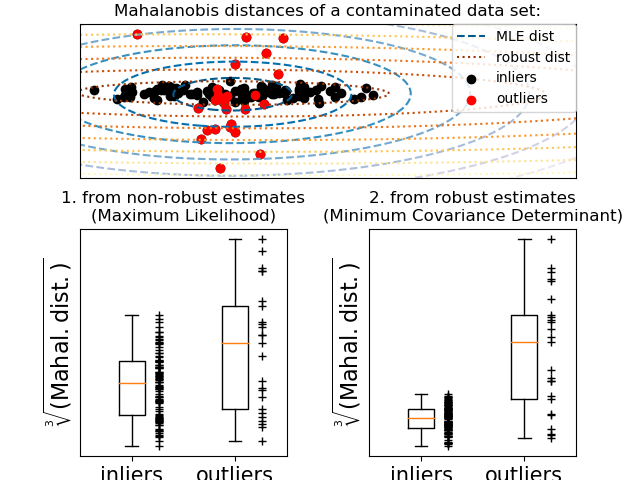
示例:
參考 魯棒協方差估計與馬氏距離相關性 說明對位置和協方差使用標準估計 ( covariance.EmpiricalCovariance) 或穩健估計 (covariance.MinCovDet) 來度量觀測值的偏遠性差異。參考資料:
Rousseeuw, P.J., Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator” Technometrics 41(3), 212 (1999)
2.7.3.2. Isolation Forest
在高維數據集中實現離群點檢測的一種有效方法是使用隨機森林。ensemble.IsolationForest 通過隨機選擇一個特征,然后隨機選擇一個被選擇特征的最大值和最小值之間的分割值來“隔離”觀察結果。
由于遞歸劃分可以由樹形結構表示,因此隔離樣本所需的分割次數等于從根節點到終止節點的路徑長度。
在這樣的隨機樹的森林中取平均值就是這條路徑的長度,是對數據正態性和我們的決策函數的一種度量。
隨機劃分能為異常觀測產生明顯的更短路徑。 因此,當隨機樹的森林為特定樣本共同產生較短的路徑長度時,他們很可能是異常的。
ensemble.IsolationForest的實現,是基于tree.ExtraTreeRegressor全體。按照Isolation Forest原始,每棵樹的最大深度設置為,其中n是構建樹所用的樣本數量(詳見:(Liu et al., 2008) )
該算法如下圖所示。

ensemble.IsolationForest支持warm_start=True,可以讓你添加更多的樹到已擬合好的模型中:
>>> from sklearn.ensemble import IsolationForest
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [0, 0], [-20, 50], [3, 5]])
>>> clf = IsolationForest(n_estimators=10, warm_start=True)
>>> clf.fit(X) # fit 10 trees
>>> clf.set_params(n_estimators=20) # add 10 more trees
>>> clf.fit(X) # fit the added trees
Examples:
有關 IsolationForest 的說明,請參考 IsolationForest示例 。 References:
Liu, Fei Tony, Ting, Kai Ming and Zhou, Zhi-Hua. “Isolation forest.” Data Mining, 2008. ICDM’08. Eighth IEEE International Conference on.
2.7.3.3. Local Outlier Factor(局部離群因子)
對中等高維數據集(即維數勉強算是高維)執行離群點檢測的另一種有效方法是使用局部離群因子(LOF)算法。
neighbors.LocalOutlierFactor LocalOutlierFactor (LOF)算法計算一個反映觀測異常程度的得分(稱為局部離群因子)。 它測量給定數據點相對于相鄰數據點的局部密度偏差。這樣做的目的是為了檢測出那些比近鄰的密度低得多的樣本。
實際應用中,局部密度從 k 個最近鄰求得的。 觀測數據的 LOF 得分等于其 k 個最近鄰的平均局部密度與其本身密度的比值:正常數據集預計與其近鄰有著相似的局部密度,而異常數據則預計比近鄰的局部密度要小得多。
k個近鄰數(別名參數 n_neighbors )通常選擇 1) 大于一個聚類簇必須包含的最小數量的對象,所以其它對象可以成為該聚類簇的局部離散點,并且 ,2) 小于可能成為聚類簇對象的最大數量, 減少這K個近鄰成為離群點的可能性。在實踐中,這樣的信息通常不可用,并且使 n_neighbors = 20 似乎都能使算法有很好的表現。 當離群點的比例較高時(大于 10% 時,如下面的示例),n_neighbors 應該較大(在下面的示例中,n_neighbors = 35)。
LOF 算法的優點是考慮到數據集的局部和全局屬性:即使在具有不同潛在密度的離群點數據集中,它也能夠表現得很好。 問題不在于樣本是如何被分離的,而是樣本與周圍近鄰的分離程度有多大。
在使用 LOF 進行離群點檢測時,不能使用 predict, decisionfunction 和 score_samples 方法, 只能用 fit_predict 方法。訓練樣本的異常性得分可通過 negative_outlier_factor 屬性來獲得。 注意當使用LOF算法進行奇異值檢測的時候(novelty 設為 True), predict, decision_function 和 score_samples 函數可被用于新的未知數據。請查看具有局部離群因子(LOF)的新穎性檢測.
該策略如下所示。
示例:
neighbors.LocalOutlierFactor的使用說明請參考 使用局部離群因子(LOF)進行離群檢測 。
參考資料:
Breunig, Kriegel, Ng, and Sander (2000) LOF: identifying density-based local outliers. Proc. ACM SIGMOD
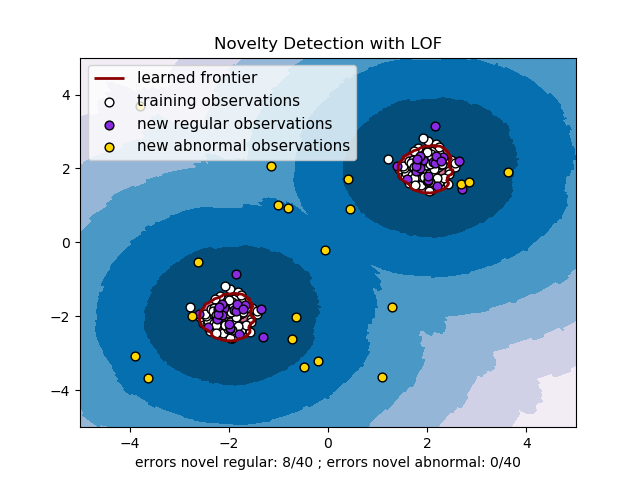
2.7.4. 使用LOF進行奇異值檢測
為了使用 neighbors.LocalOutlierFactor 進行奇異值檢測, 即對新的未見過的樣本預測其標簽或計算異常性得分,在擬合之前,你必須在實例化估計器時, 將novelty參數設為 True:
lof = LocalOutlierFactor(novelty=True)
lof.fit(X_train)Copy
請注意此情況下fit_predict 不再適用。
警告 :使用局部離群因子(Local Outlier Factor,LOF)進行奇異值檢測
要注意,在新的未見過的數據上,當
novelty參數被設為 True 時只能使用predict,decision_function和score_samples,不能把這幾個函數用在訓練數據上, 否則會導致錯誤的結果。訓練樣本的異常性得分可以通過negative_outlier_factor_屬性來訪問獲取。
使用局部離群因子進行奇異值檢測的示例見下圖: