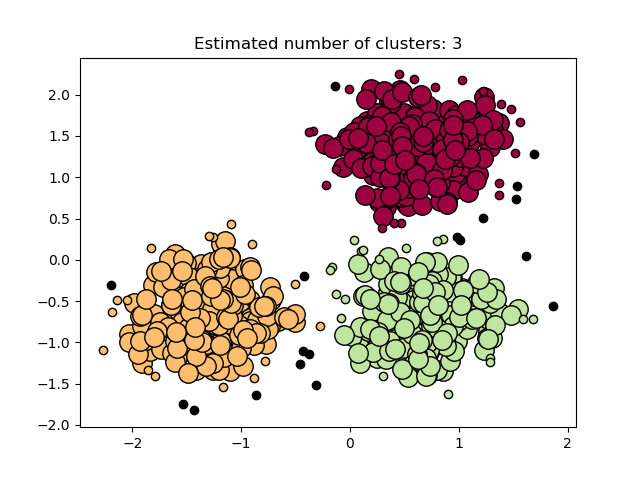
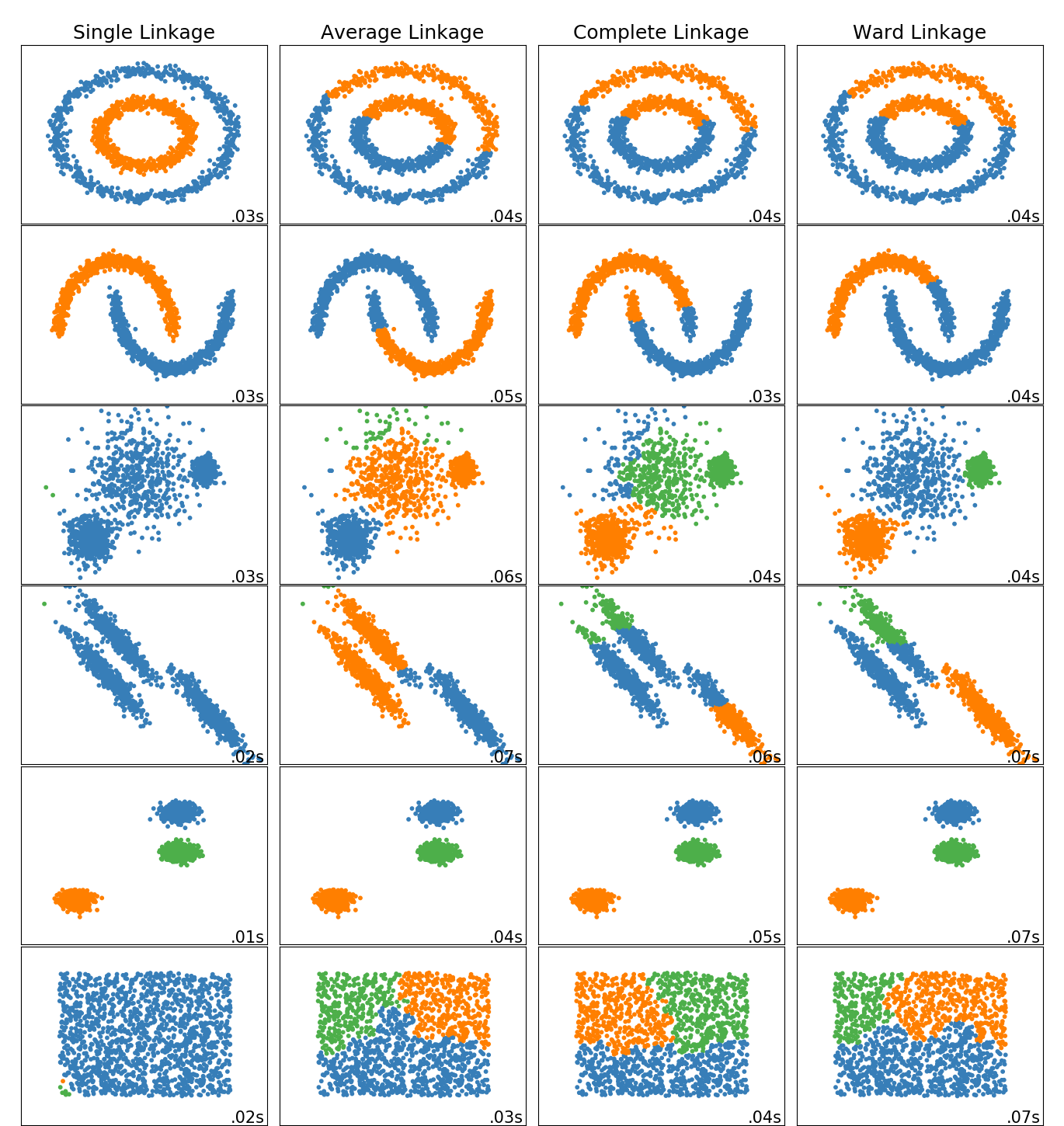
sklearn.datasets.make_blobs?
sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None, return_centers=False)
生成各向同性的高斯Blob進行聚類。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| n_samples | int or array-like, optional (default=100) 如果為int,則為在簇之間平均分配的點總數。如果為陣列狀,則序列的每個元素表示每個簇的樣本數。 v0.20版中進行了更改:現在可以將類似數組的參數傳遞給n_samples參數 |
| n_features | int, optional (default=2) 每個樣本的特征數量。 |
| centers | int or array of shape [n_centers, n_features], optional (default=None)要生成的中心數或固定的中心位置。如果n_samples是一個int且center為None,則生成3個中心。如果n_samples類似于數組,則中心必須為None或長度等于n_samples長度的數組。 |
| cluster_std | float or sequence of floats, optional (default=1.0) 群集的標準偏差。 |
| center_box | pair of floats (min, max), optional (default=(-10.0, 10.0)) 隨機生成中心時每個聚類中心的邊界框。 |
| shuffle | boolean, optional (default=True) shuffle樣本 |
| random_state | int, RandomState instance, default=None 確定用于生成數據集的隨機數生成。為多個函數調用傳遞可重復輸出的int值。請參閱詞匯表。 |
| return_centers | bool, optional (default=False) 如果為True,則返回每個群集的中心 0.23版中的新功能。 |
| 返回值 | 說明 |
|---|---|
| X | array of shape [n_samples, n_features] 生成的樣本。 |
| y | array of shape [n_samples] 每個樣本的群集成員的整數標簽。 |
| centers | array, shape [n_centers, n_features] 每個群集的中心。 僅在return_centers = True時返回。 |
另見
更復雜的變體
示例
>>> from sklearn.datasets import make_blobs
>>> X, y = make_blobs(n_samples=10, centers=3, n_features=2,
... random_state=0)
>>> print(X.shape)
(10, 2)
>>> y
array([0, 0, 1, 0, 2, 2, 2, 1, 1, 0])
>>> X, y = make_blobs(n_samples=[3, 3, 4], centers=None, n_features=2,
... random_state=0)
>>> print(X.shape)
(10, 2)
>>> y
array([0, 1, 2, 0, 2, 2, 2, 1, 1, 0])