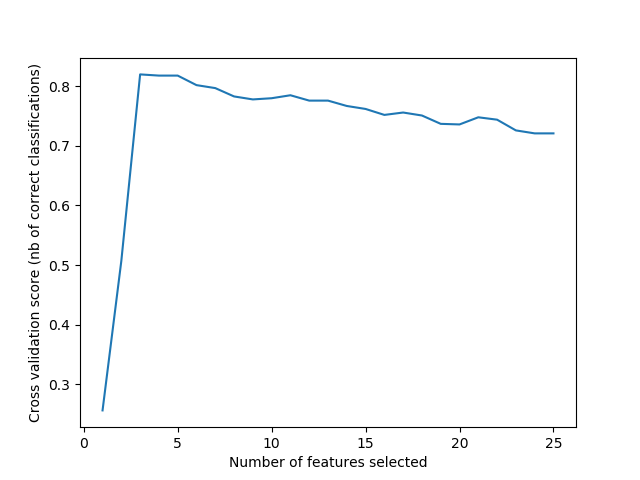
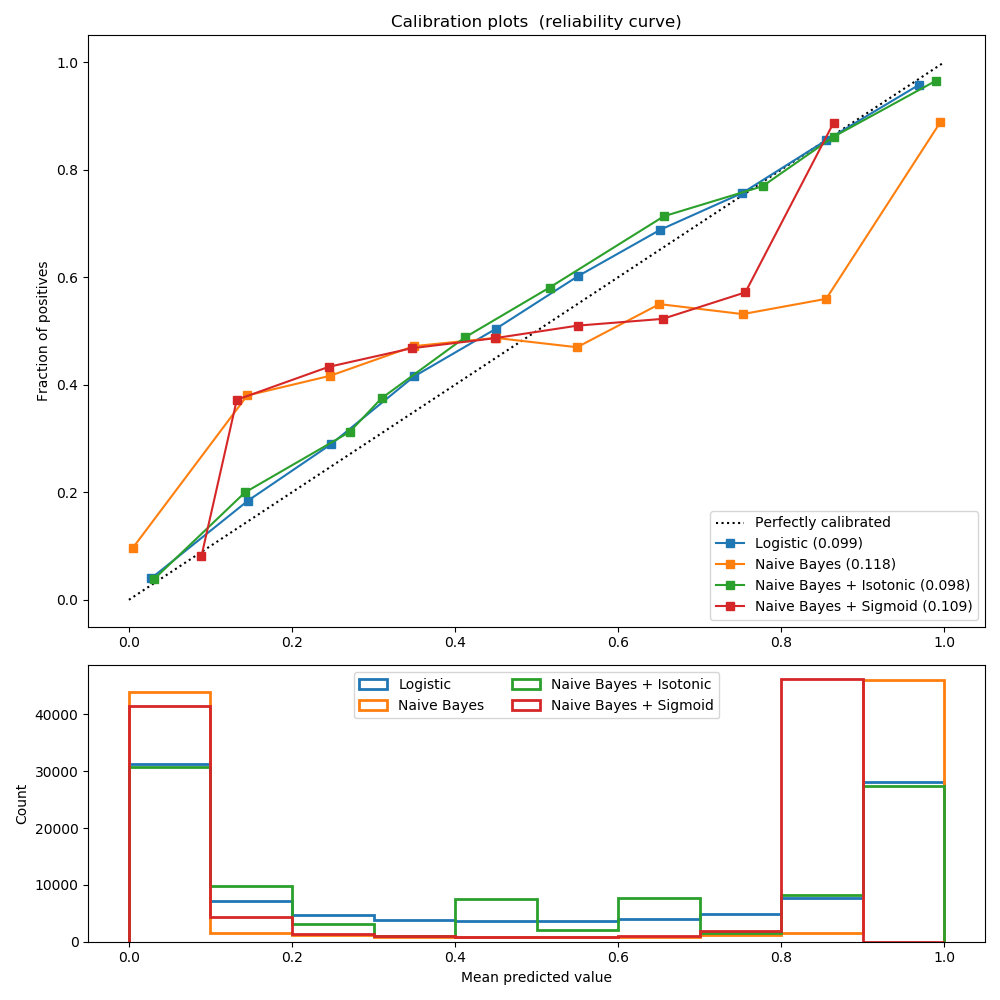
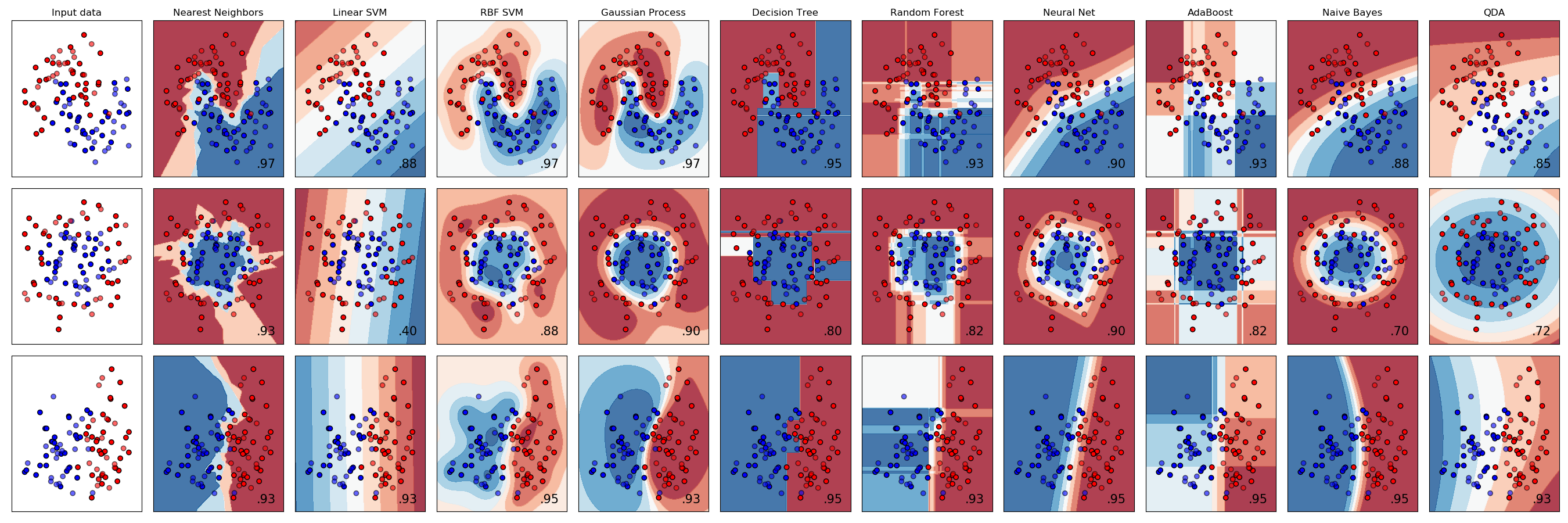
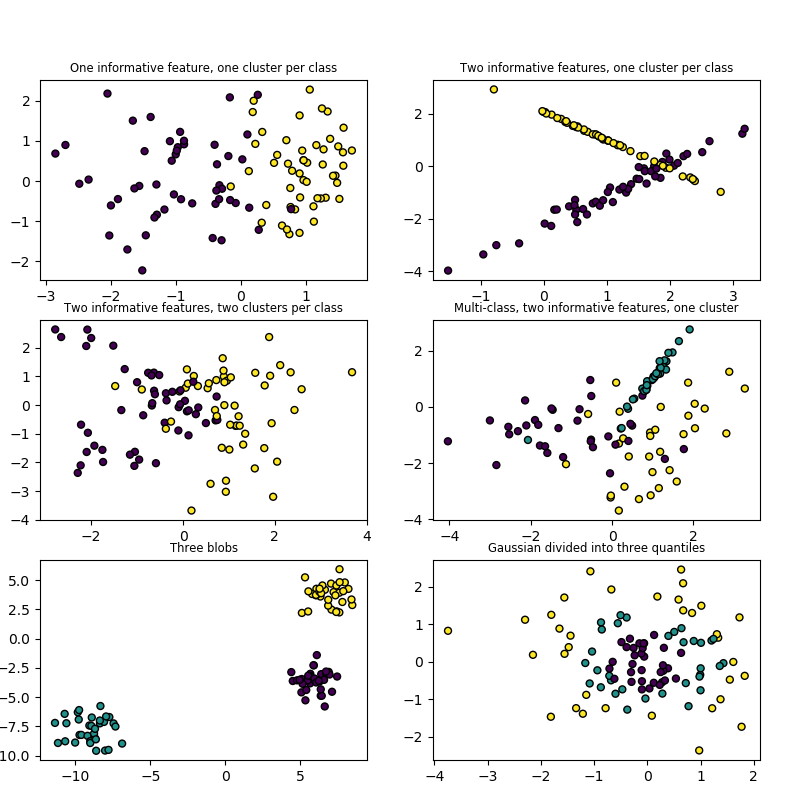
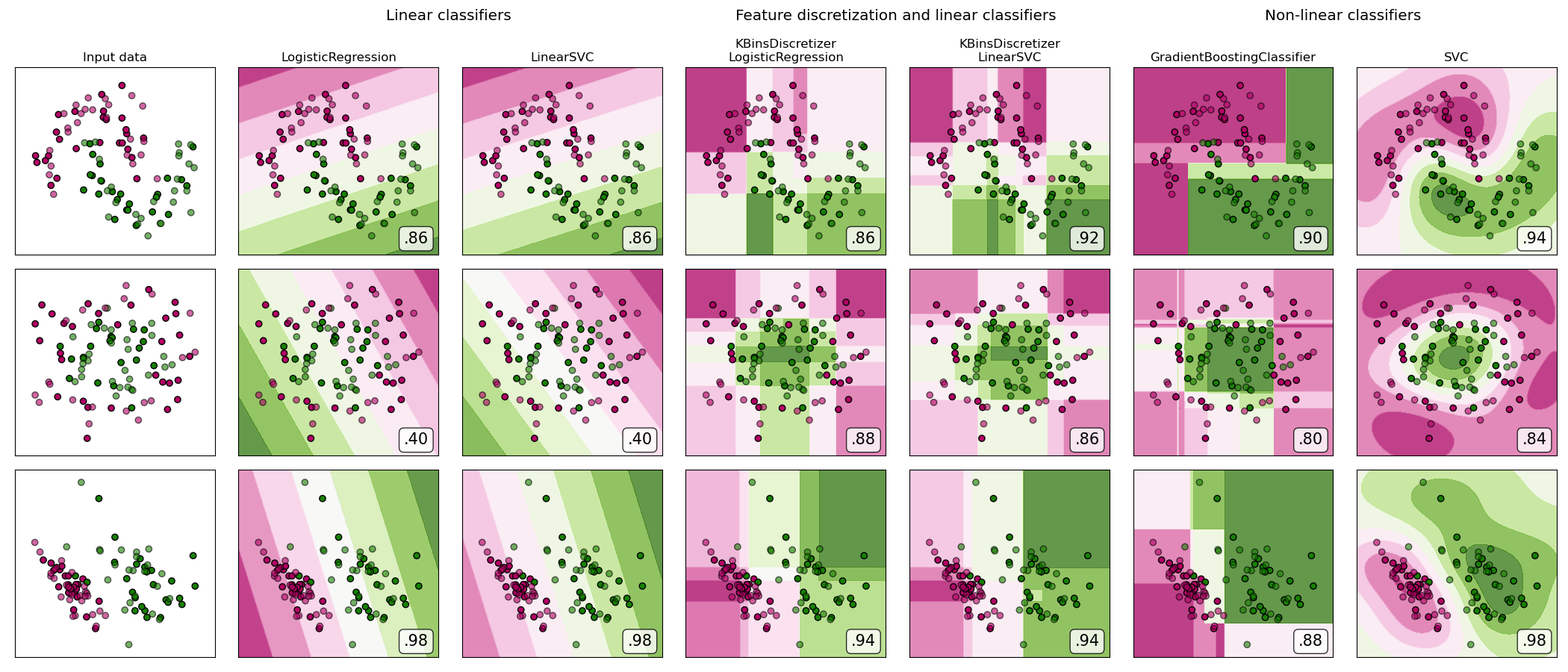
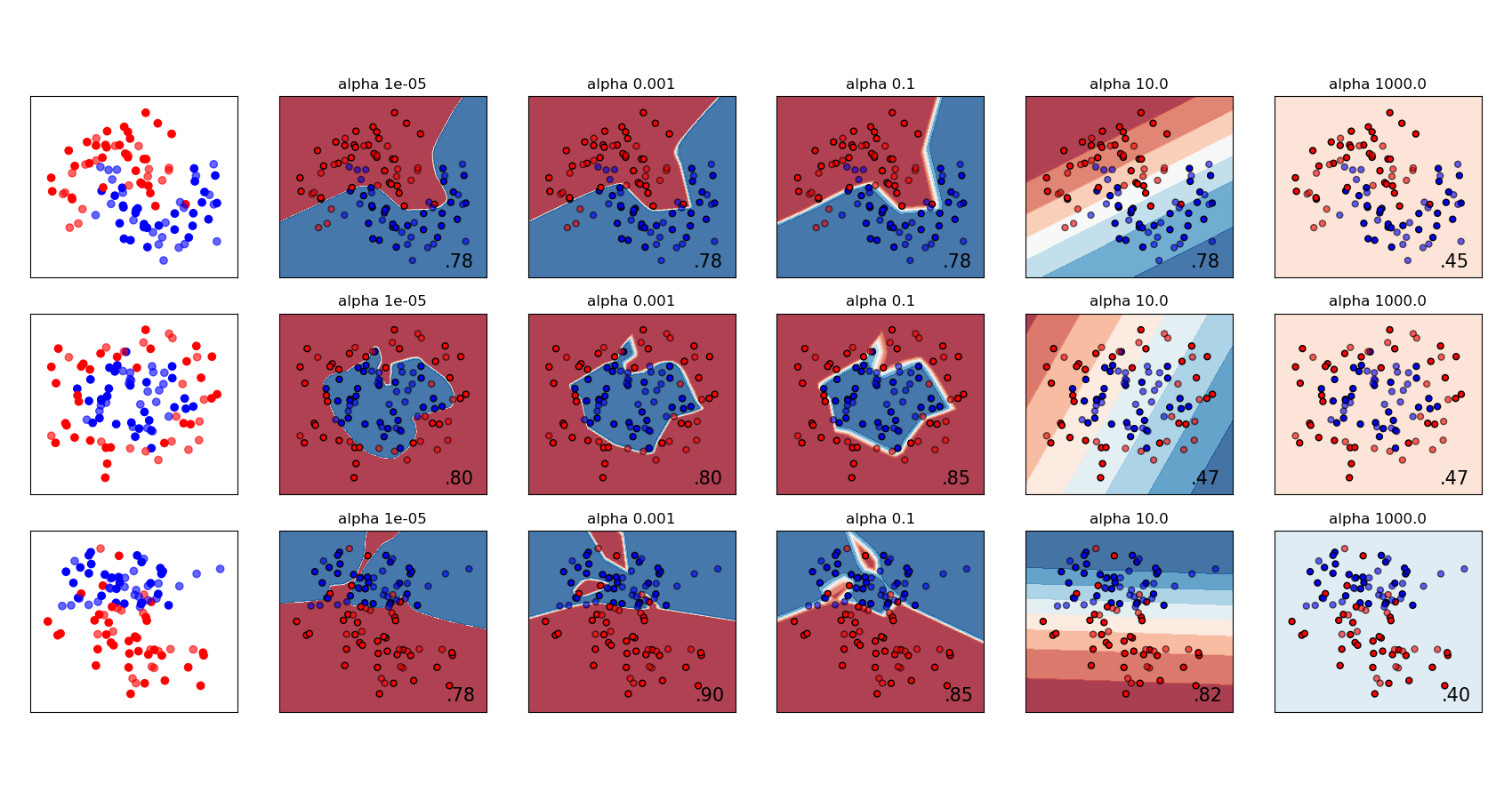
sklearn.datasets.make_classification?
sklearn.datasets.make_classification(n_samples=100, n_features=20, *, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
生成隨機的n類分類問題。
最初,這將創建一個邊長為2 * class_sep的正態分布(std=1)在n_informative維超立方體的頂點周圍的點的聚類,并為每個類分配相等數量的聚類。它引入了這些功能之間的相互依賴性,并為數據增加了各種類型的進一步噪聲。
在不進行shuffle的情況下,X按以下順序水平堆疊特征:主要的n_informative特征,然后是n_redundant線性的信息特征組合,然后是n_repeated副本,從信息和冗余特征中隨機替換。其余功能充滿了隨機噪聲。因此,沒有shuffle時,所有有用的功能都包含在列X [:,:n_informative + n_redundant + n_repeated]中。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| n_samples | int, optional (default=100) 樣本數。 |
| n_features | int, optional (default=20) 功能總數。這些包括隨機繪制的n_informative信息特征,n_redundant冗余特征,n_repeated重復特征和n_features-n_informative-n_redundant-n_repeated無用特征。 |
| n_informative | int, optional (default=2) 信息特征的數量。每個類都由多個高斯簇組成,每個簇圍繞著超立方體的頂點位于n_informative維子空間中。對于每個聚類,獨立于N(0,1)繪制信息特征,然后在每個聚類內隨機線性組合以增加協方差。 然后將簇放置在超立方體的頂點上。 |
| n_redundant | int, optional (default=2) 冗余特征的數量。 這些特征是作為信息特征的隨機線性組合生成的。 |
| n_repeated | int, optional (default=0) 從信息性和冗余性特征中隨機抽取的重復性特征的數量。 |
| n_classes | int, optional (default=2) 分類問題的類(或標簽)數。 |
| n_clusters_per_class | int, optional (default=2) 每個類的簇數。 |
| weights | array-like of shape (n_classes,) or (n_classes - 1,), (default=None) 分配給每個類別的樣本比例。 如果為None,則類是平衡的。 請注意,如果len(weights)== n_classes-1,則自動推斷最后一個類的權重。如果weights之和超過1,則可能返回多于n_samples個樣本。 |
| flip_y | float, optional (default=0.01) 類別隨機分配的樣本比例。 較大的值會在標簽中引入噪音,并使分類任務更加困難。 請注意,在某些情況下,默認設置flip_y> 0可能導致y中的類少于n_class。 |
| class_sep | float, optional (default=1.0) 超立方體大小乘以的因子。 較大的值分散了群集/類,并使分類任務更加容易。 |
| hypercube | boolean, optional (default=True) 如果為True,則將簇放置在超立方體的頂點上。 如果為False,則將簇放置在隨機多面體的頂點上。 |
| shift | float, array of shape [n_features] or None, optional (default=0.0) 按指定值移動特征。 如果為None,則將特征移動[-class_sep,class_sep]中繪制的隨機值。 |
| scale | float, array of shape [n_features] or None, optional (default=1.0) 將特征乘以指定值。如果為None,則將按[1,100]中繪制的隨機值縮放要素。請注意,縮放發生在移位之后。 |
| shuffle | shuboolean, optional (default=True) shuffle樣本和特征。 |
| random_state | int, RandomState instance, default=None 確定用于生成數據集的隨機數生成。 為多個函數調用傳遞可重復輸出的int值。 請參閱詞匯表。 |
| 返回值 | 說明 |
|---|---|
| X | array of shape [n_samples, n_features] 生成的樣本。 |
| y | array of shape [n_samples] 每個樣本的類成員的整數標簽。 |
另見
簡化變體
make_multilabel_classification
多標簽任務的無關生成器
注
該算法改編自Guyon [1],旨在生成“ Madelon”數據集。
參考
I. Guyon, “Design of experiments for the NIPS 2003 variable selection benchmark”, 2003.