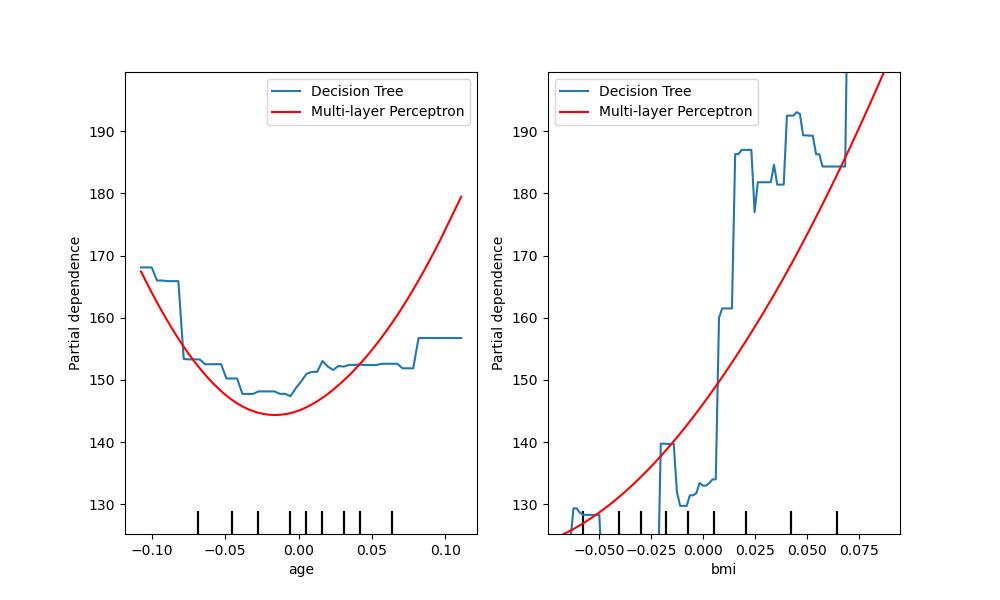
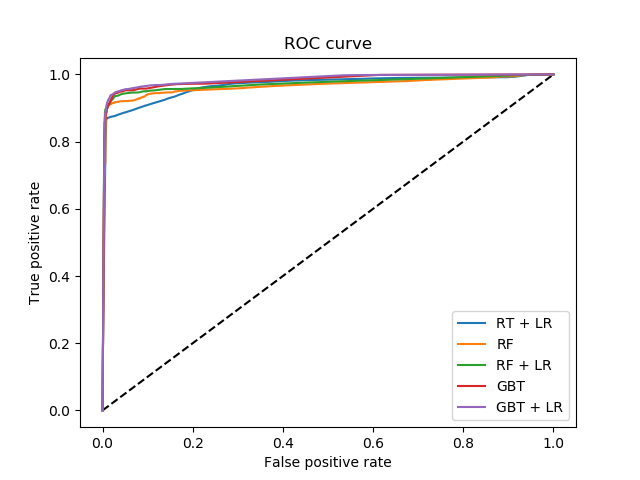
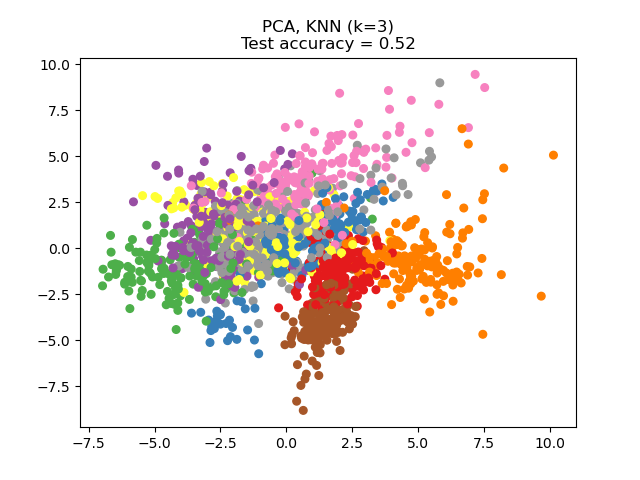
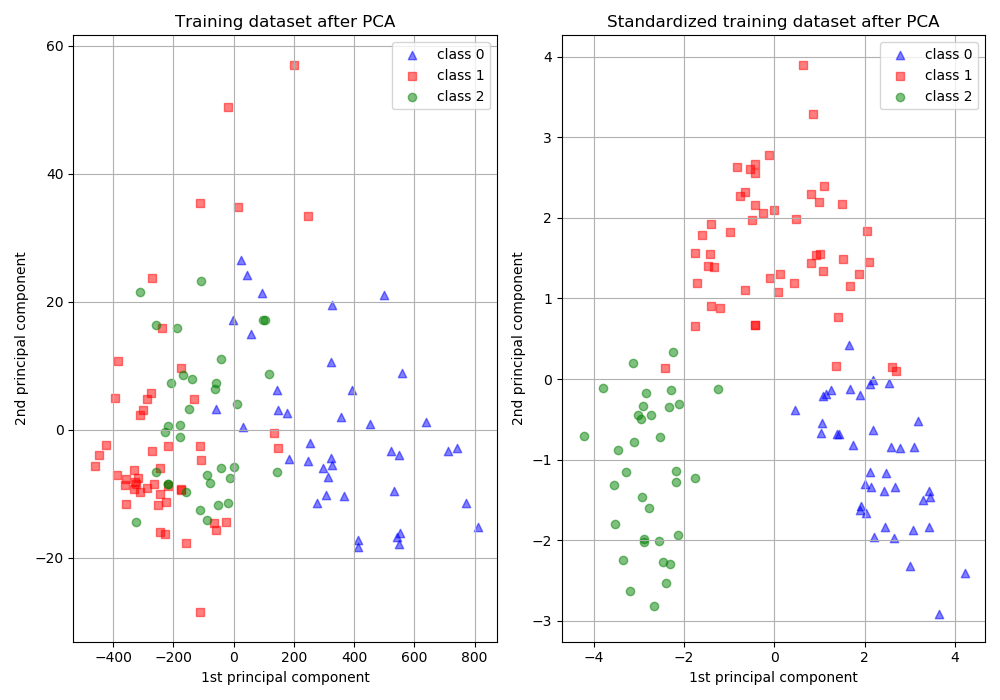
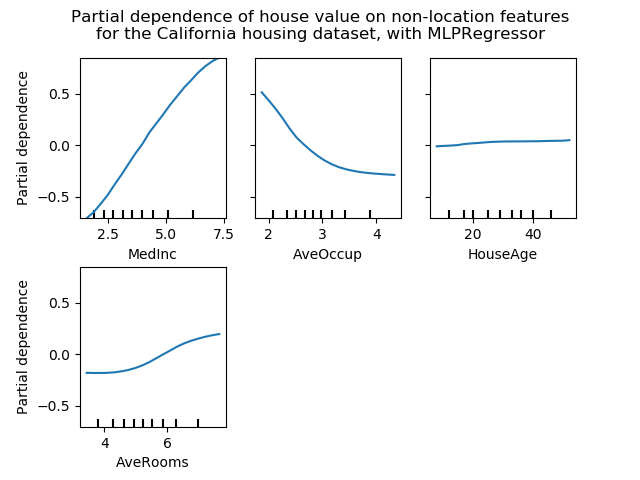
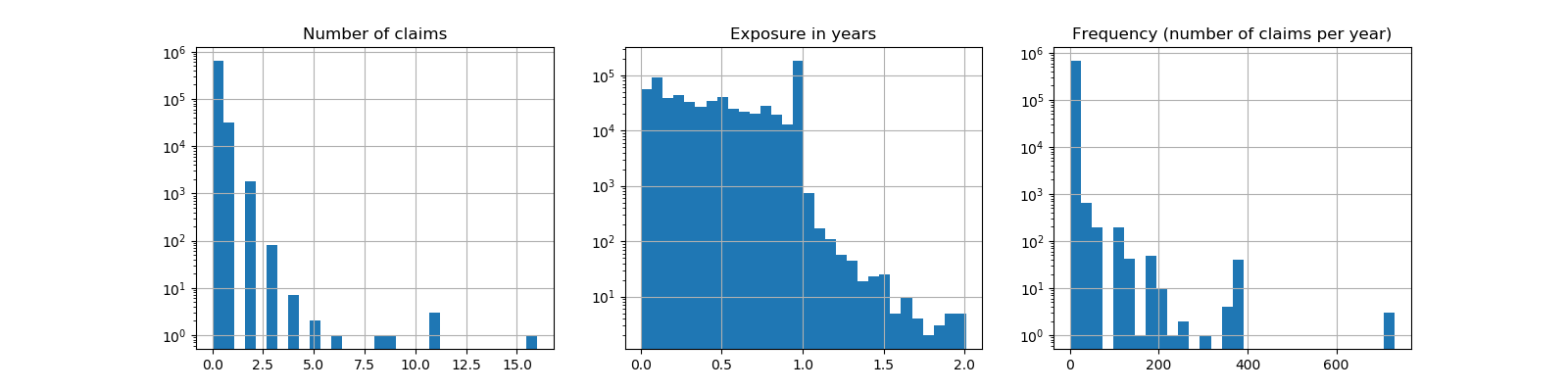
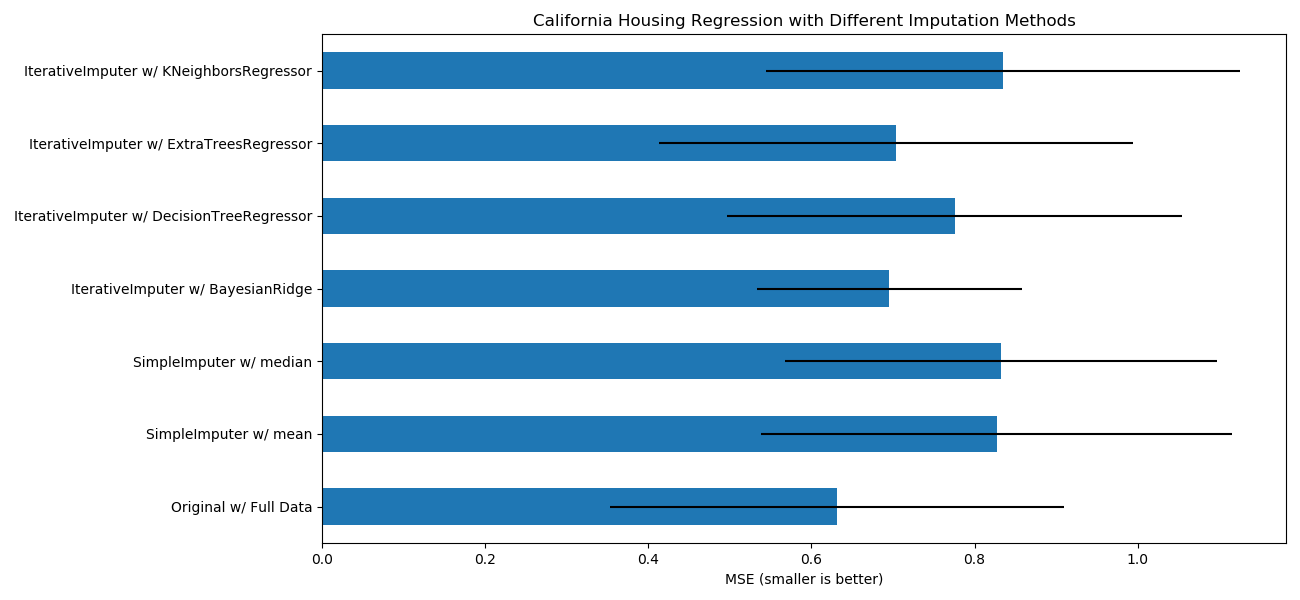
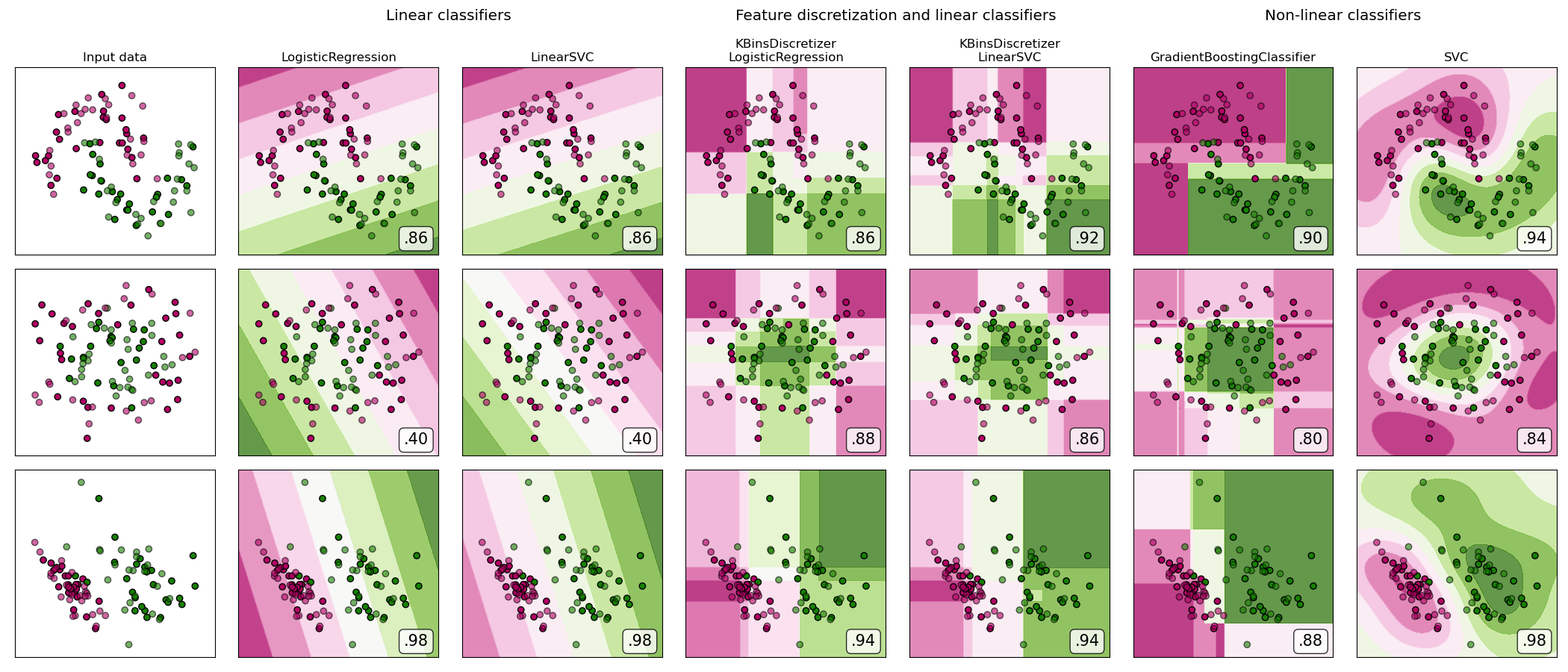
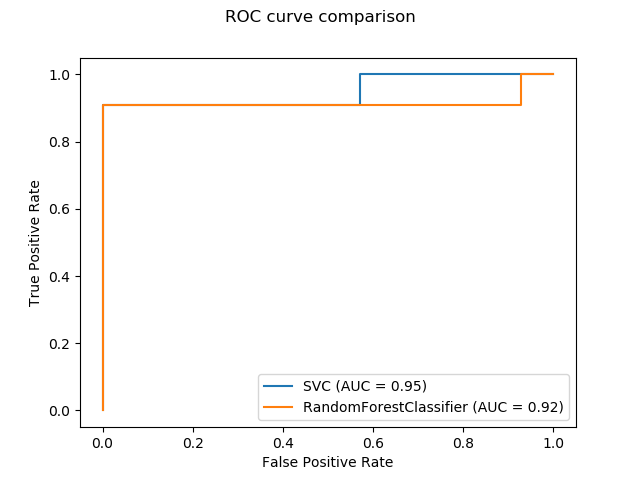
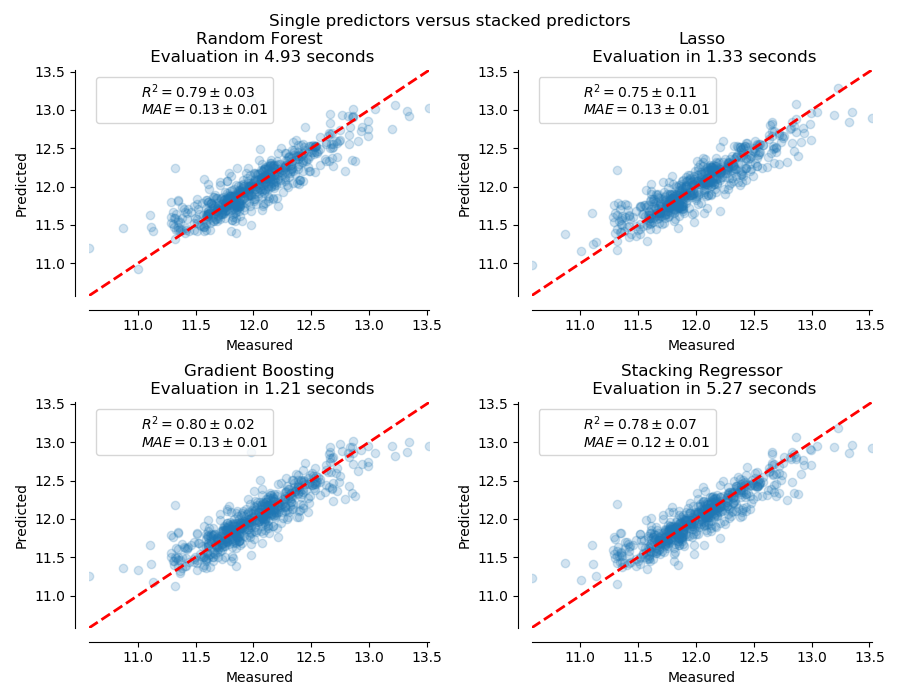
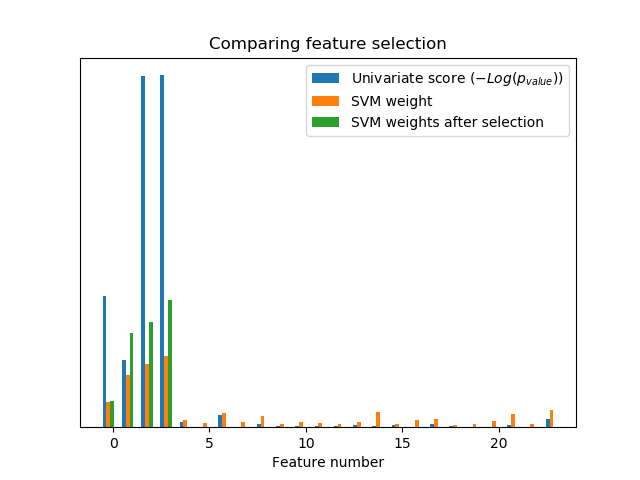
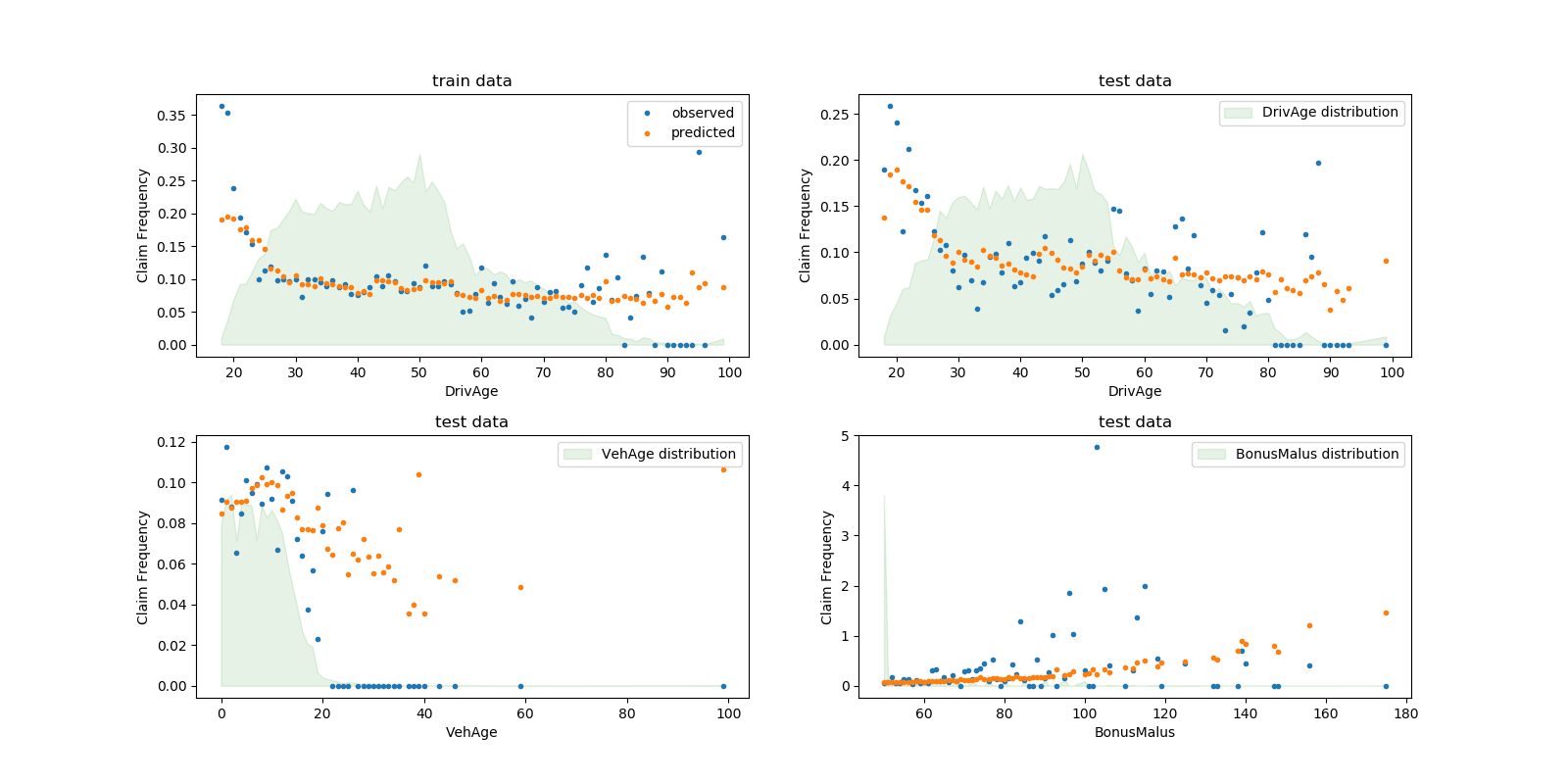
sklearn.pipeline.make_pipeline?
sklearn.pipeline.make_pipeline(*steps, **kwargs)
[源碼]
根據給定的估計器構造管道。
這是Pipeline構造函數的簡寫;它不需要也不允許命名估計器。而是將其名稱自動設置為其類型的小寫字母。
| 參數 | 說明 |
|---|---|
| *steps | list of estimators. |
| memory | str or object with the joblib.Memory interface, default=None 用于緩存管道中擬合的轉換器。默認情況下,不執行緩存。如果給定一個字符串,它就是到緩存目錄的路徑。啟用緩存會在擬合前觸發轉換器的克隆。因此,不能直接檢查提供給管道的轉換器實例。可以使用屬性 named_steps或steps檢查管道中的估計器。當擬合耗時時,緩存轉換器是有利的。 |
| verbose | bool, default=False 如果為True,則在完成每個step時會打印經過的時間。 |
| 返回值 | 說明 |
|---|---|
| p | Pipeline |
另見:
sklearn.pipeline.Pipeline用于使用最后一個估計器創建轉換管道的類。
示例
>>> from sklearn.naive_bayes import GaussianNB
>>> from sklearn.preprocessing import StandardScaler
>>> make_pipeline(StandardScaler(), GaussianNB(priors=None))
Pipeline(steps=[('standardscaler', StandardScaler()),
('gaussiannb', GaussianNB())])