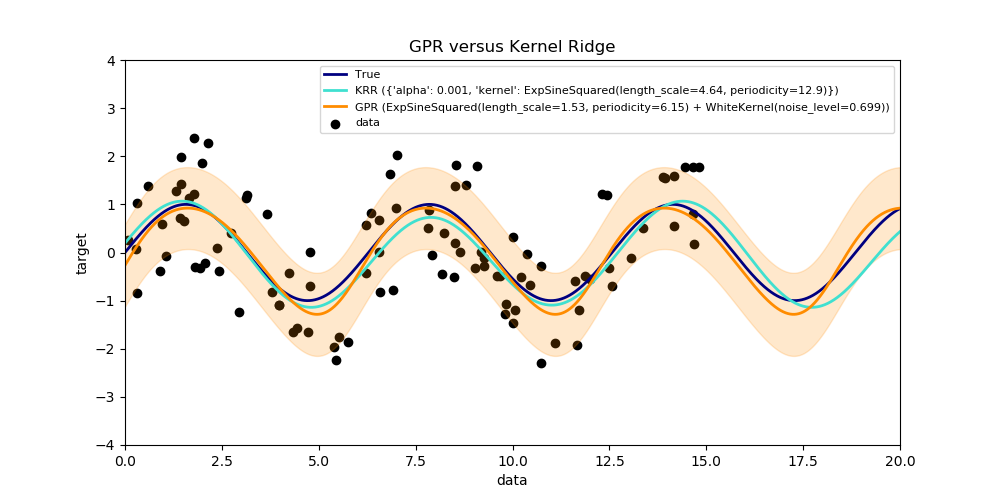
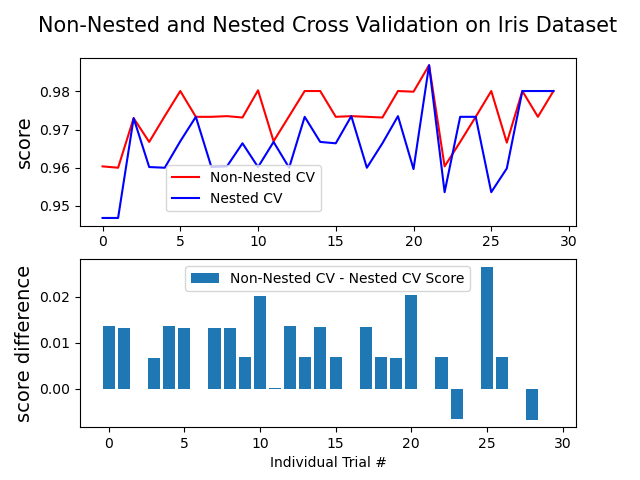
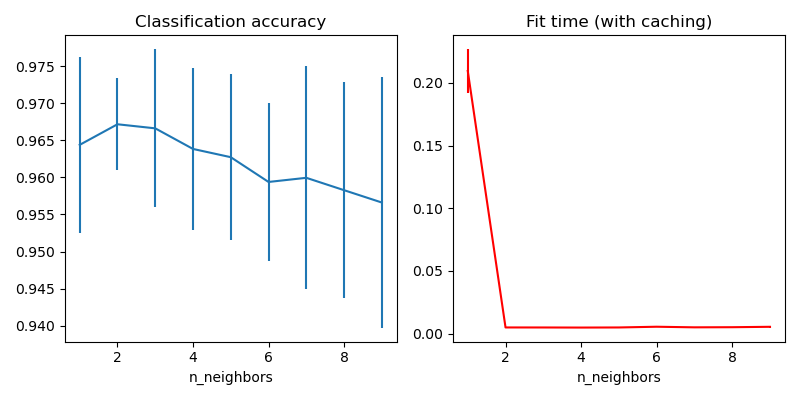
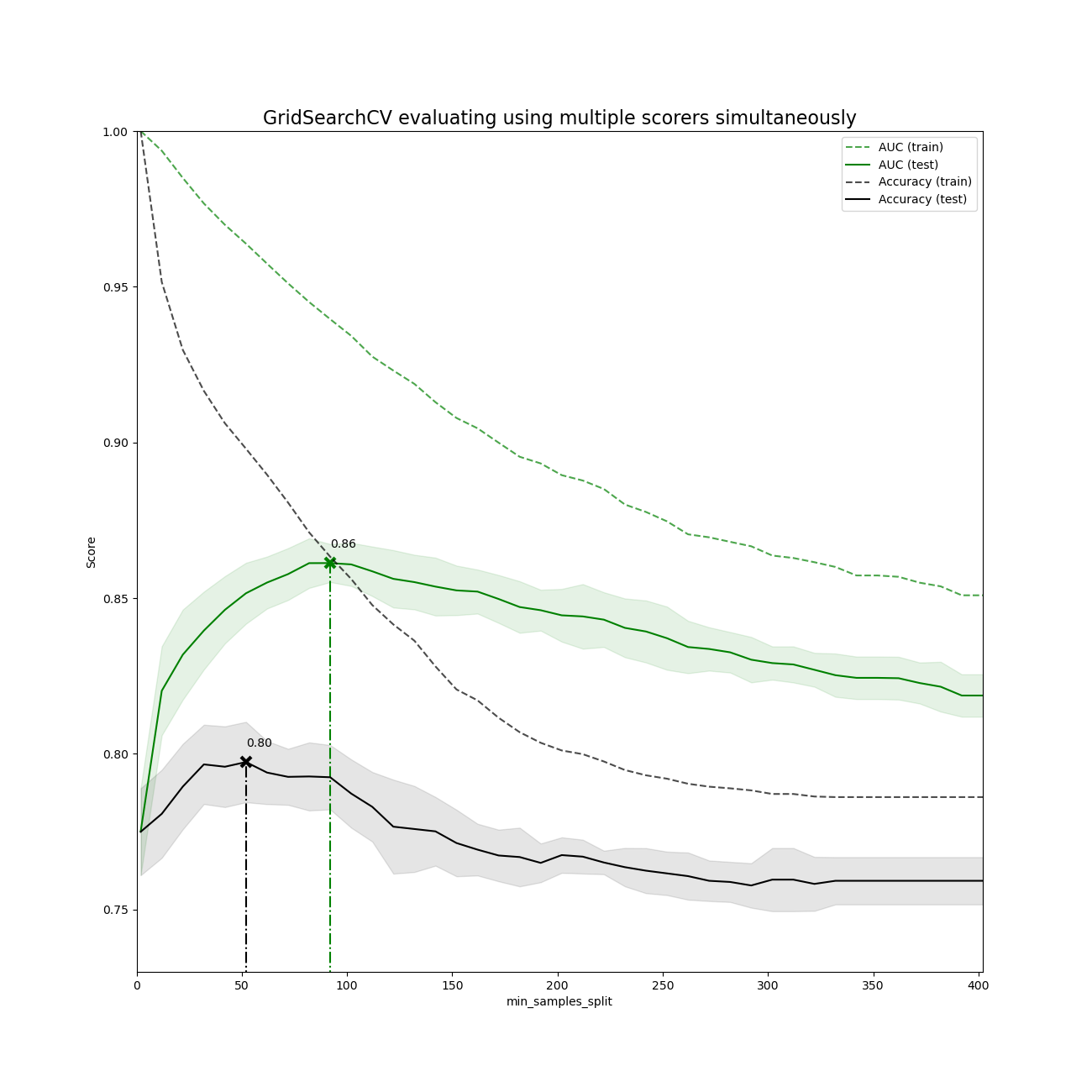
sklearn.model_selection.GridSearchCV?
class sklearn.model_selection.GridSearchCV(estimator, param_grid, *, scoring=None, n_jobs=None, iid='deprecated', refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)
[源碼]
詳盡搜索估計器的指定參數值。
重要的成員被擬合,可以預測。
GridSearchCV實現“擬合”和“得分”方法。如果在所使用的估計器中實現了“predict”,“predict_proba”,“decision_function”,“transform”和“inverse_transform” if the”,則還可以實現它們。
通過在參數網格上進行交叉驗證的網格搜索,優化了用于應用這些方法的估計器的參數。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| estimator | estimator object 假定這樣做是為了實現scikit-learn估計器接口。估計器需要提供 score功能,或者必須通過scoring。 |
| param_grid | dict or list of dictionaries 以參數名稱( str)作為鍵,將參數設置列表嘗試作為值的字典,或此類字典的列表,在這種情況下,將探索列表中每個字典所跨越的網格。這樣可以搜索任何順序的參數設置。 |
| scoring | str, callable, list/tuple or dict, default=None 單個str(請參閱評分參數:定義模型評估規則)或可調用項(請參閱從度量函數定義評分策略),用于評估測試集上的預測。 要評估多個指標,請給出(唯一的)字符串列表或以名稱為鍵,可調用項為值的字典。 注意,使用自定義評分器時,每個評分器應返回一個值。返回值列表或數組的度量函數可以包裝到多個評分器中,每個評分器都返回一個值。 有關示例,請參閱指定多個度量進行評估。 如果為None,則使用估計器的評分方法。 |
| n_jobs | int, default=None 要并行運行的CPU內核數。 None除非在joblib.parallel_backend環境中,否則表示1 。 -1表示使用所有處理器。有關 更多詳細信息,請參見詞匯表。v0.20版中的更改: n_jobs默認從1更改為None |
| pre_dispatch | int, or str, default=n_jobs 控制在并行執行期間分派的CPU內核數。當調度的CPU內核數量超過CPU的處理能力時,減少此數量可能有助于避免內存消耗激增。該參數可以是: - None,在這種情況下,所有CPU內核都將立即創建并產生,使它進行輕量級和快速運行的任務,以避免因按需生成作業而造成延遲 -int,給出所產生的總CPU內核數的確切數量 -str,根據n_jobs給出表達式,如'2*n_jobs' |
| iid | bool, default=False 如果為True,則按折數返回平均得分,并按每個測試集中的樣本數加權。在這種情況下,假定數據在折疊上分布相同,并且最小化的損失是每個樣品的總損失,而不是折疊的平均損失。 從版本0.22開始 iid不推薦使用*:*參數在0.22中不再推薦使用,并將在0.24中刪除 |
| cv | int, cross-validation generator or an iterable, default=None 確定交叉驗證切分策略。可以輸入: -None,默認使用5折交叉驗證 -integer,用于指定在 (Stratified)KFold中的折疊次數-CV splitter -一個輸出訓練集和測試集切分為索引數組的迭代。 對于integer或None,如果估計器是分類器,并且 y是二分類或多分類,使用StratifiedKFold。在所有其他情況下,使用KFold。有關可在此處使用的各種交叉驗證策略,請參閱用戶指南。 在0.22版本中: cv為“None”時,默認值從3折更改為5折 |
| refit | bool, str, or callable, default=True 使用在整個數據集中找到的最優參數重新擬合估計器。 對于多指標評估,這需要是一個表示評分器的 str,該評分器將為最終重新擬合估計器找到最優參數。如果在選擇最優估計值時除了考慮最大得分外,還需要考慮其他因素,可以將 refit設置為返回所選best_index_給定cv_results_的函數。在這種情況下,best_estimator_和best_params_將根據返回的best_index_進行設置,而best_score_ 屬性將不可用。重新擬合的估計器在 best_estimator_ 屬性上可用,并允許predict直接在GridSearchCV實例上使用。同樣對于多指標評估, best_index_, best_score_和best_params_屬性僅在設置refit時可用,并且都將根據這個特定的評分器來決定。請參閱 scoring參數以了解有關多指標評估的更多信息。在0.20版中:添加了對Callable的支持。 |
| verbose | integer 控制詳細程度:越高,消息越多。 |
| error_score | ‘raise’ or numeric, default=np.nan 如果估計器擬合出現錯誤,將值分配給分數。如果設置為“ raise”,則會引發錯誤。如果給出數值,則引發FitFailedWarning。此參數不會影響重新擬合步驟,這將總是引發錯誤。 |
| return_train_score | bool, default=False 如果為 False,則cv_results_屬性將不包括訓練集分數。計算訓練集分數用于了解不同的參數設置如何影響過擬合或欠擬合的權衡。但是,在訓練集上計算分數可能在計算上很耗時,并且不嚴格要求選擇產生最優泛化性能的參數。版本0.19中的新功能。 在版本0.21中:默認值將 True更改為False |
| 屬性 | 說明 |
|---|---|
| cv_results_ | dict of numpy (masked) ndarrays 可以將鍵作為列標題和值作為列的字典導入pandas DataFrame。例如下面給定的表  用一個 用一個cv_results_字典表示: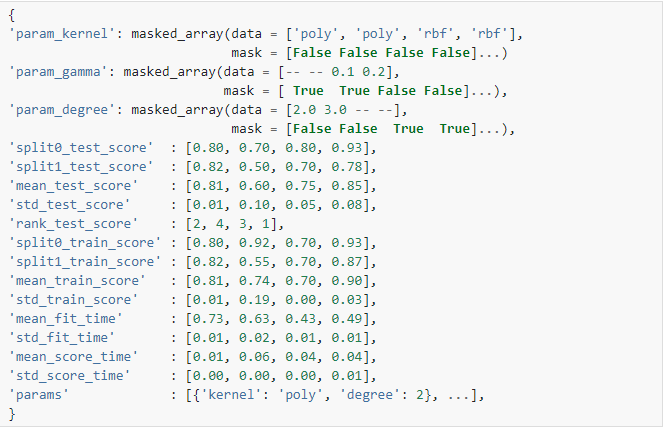 注意 注意'params'鍵用于存儲所有候選參數的參數設置字典列表。mean_fit_time,std_fit_time,mean_score_time和 std_score_time的單位都是秒。對于多指標評估,所有評分器的得分都可以在 cv_results_字典中以評分器的名字('_<scorer_name>')結尾的鍵獲得,而不是'_score'上面顯示的。(“ split0_test_precision”,“ mean_train_precision”等) |
| best_estimator_ | estimator 搜索選擇的估計器,例如,對剩余數據給出最高分(或最小損失是否指定)的估計量。如果設置 refit=False則不可用。有關 refit允許值的更多信息,請參見參數。 |
| best_score_ | float best_estimator的平均交叉驗證得分 對于多指標評估,只有在 refit指定時才存在。如果 refit為函數,則此屬性不可用。 |
| best_params_ | dict 參數設置可使保留數據獲得最優結果。 對于多指標評估,只有在 refit指定時才存在。 |
| best_index_ | search.cv_results_['params'][search.best_index_]的字典給出了最優模型的參數設置,該模型給出最高平均得分(search.best_score_)。對于多指標評估,只有在 refit指定時才存在。 |
| scorer_ | function or a dict 在保留的數據上使用評分器功能為模型選擇最優參數。 對于多指標評估,此屬性保存已驗證的 scoring字典,該字典將評分器鍵映射到可調用的評分器。 |
| n_splits_ | int 交叉驗證切分(或折疊、迭代)的數量。 |
| refit_time_ | float 用于在整個數據集中重新擬合最優模型的秒數。 僅當 refit不是False 時才存在。0.20版中的新功能。 |
另見:
ParameterGrid生成超參數網格的所有組合。
sklearn.model_selection.train_test_split用于將數據切分為可用于擬合GridSearchCV實例的開發集和用于最終評估的驗證集的實用程序功能。
sklearn.metrics.make_scorer根據績效指標或損失函數確定評分器。
注
所選擇的參數是那些保留數據中得分最大的參數,除非傳遞了一個顯式得分,在這種情況下使用它。
如果將n_jobs設置為大于1的值,則將為網格中的每個點(而不是n_jobs時間)復制數據。如果單個任務所花費的時間很少,那么這樣做是為了提高效率,但是如果數據集很大且沒有足夠的可用內存,則可能會引發錯誤。在這種情況下,解決方法是設置pre_dispatch。然后,僅復制內存 pre_dispatch多次。pre_dispatch的合理值是2 * n_jobs。
示例
>>> from sklearn import svm, datasets
>>> from sklearn.model_selection import GridSearchCV
>>> iris = datasets.load_iris()
>>> parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
>>> svc = svm.SVC()
>>> clf = GridSearchCV(svc, parameters)
>>> clf.fit(iris.data, iris.target)
GridSearchCV(estimator=SVC(),
param_grid={'C': [1, 10], 'kernel': ('linear', 'rbf')})
>>> sorted(clf.cv_results_.keys())
['mean_fit_time', 'mean_score_time', 'mean_test_score',...
'param_C', 'param_kernel', 'params',...
'rank_test_score', 'split0_test_score',...
'split2_test_score', ...
'std_fit_time', 'std_score_time', 'std_test_score']
方法
| 方法 | 說明 |
|---|---|
decision_function(self, X) |
使用找到的最優參數在估計器上調用Decision_function。 |
fit(self, X[, y, groups]) |
擬合所有參數組合。 |
get_params(self[, deep]) |
獲取此估計器的參數。 |
inverse_transform(self, Xt) |
用找到的最優參數在估計器上調用inverse_transform。 |
predict(self, X) |
使用找到的最優參數在估計器上調用預測。 |
predict_log_proba(self, X) |
使用找到的最優參數在估計器上調用predict_log_proba。 |
predict_proba(self, X) |
使用找到的最優參數在估計器上調用predict_proba。 |
score(self, X[, y]) |
如果估計器已調整,則返回給定數據的分數。 |
set_params(self, **params) |
設置此估計器的參數。 |
transform(self, X) |
使用找到的最優參數在估計器上調用transform。 |
__init__(self,estimator,param_grid,*,scoring = None,n_jobs = None,iid ='deprecated',refit = True,cv = None,verbose = 0,pre_dispatch ='2 * n_jobs',error_score = nan,return_train_score = False )
[源碼]
初始化self。詳情可參閱 type(self)的幫助。
decision_function(self, X)
[源碼]
使用找到的最優參數在估計器上調用Decision_function。
僅在refit=True且基礎估計器支持時 可用decision_function。
| 參數 | 說明 |
|---|---|
| X | indexable, length n_samples 必須滿足基礎估算器的輸入假設。 |
fit(self,X,y = None,*,groups = None,** fit_params )
[源碼]
擬合所有參數組合。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 用于訓練的向量,其中n_samples是樣本數量,n_features是特征數量。 |
| y | array-like of shape (n_samples, n_output) or (n_samples,), default=None 用于分類或回歸的X對應的標簽;無監督學習為None。 |
| groups | array-like of shape (n_samples,), default=None 將數據集切分為訓練集或測試集時使用的樣本的分組標簽。僅與“ Group” cv 實例(例如 GroupKFold)結合使用。 |
| **fit_params | dict of str -> object 傳遞給 fit估計器方法的參數 |
get_params(self,deep = True )
[源碼]
獲取估計器的參數。
| 參數 | 說明 |
|---|---|
| deep | bool, default=True 如果為True,則將返回估計器的參數和估計器包含的子對象。 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名稱映射到其值。 |
inverse_transform(self, Xt)
[源碼]
用找到的最優參數在估計器上調用inverse_transform。
僅在基礎估計器實現inverse_transform和 refit=True時可用。
| 參數 | 說明 |
|---|---|
| Xt | indexable, length n_samples 必須滿足基礎估算器的輸入假設。 |
predict(self, X)
[源碼]
使用找到的最優參數在估計器上調用predict。
僅在refit=True且基礎估計器支持predict時可用。
| 參數 | 說明 |
|---|---|
| X | indexable, length n_samples 必須滿足基礎估算器的輸入假設。 |
predict_log_proba(self, X)
[源碼]
使用找到的最優參數在估計器上調用predict_log_proba。
僅在refit=True且基礎估計器支持predict_log_proba時可用。
| 參數 | 說明 |
|---|---|
| X | indexable, length n_samples 必須滿足基礎估算器的輸入假設。 |
predict_proba(self, X)
[源碼]
使用找到的最優參數在估計器上調用predict_proba。
僅在refit=True且基礎估計器支持predict_proba時可用。
| 參數 | 說明 |
|---|---|
| X | indexable, length n_samples 必須滿足基礎估算器的輸入假設。 |
score(self,X,y = None )
[源碼]
如果估計器已調整,則返回給定數據的分數。
這將使用scoring提供的位置定義的分數,best_estimator_.score否則使用 方法。
| 參數 | 說明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 輸入數據,其中n_samples是樣本數量,n_features是特征數量。 |
| y | array-like of shape (n_samples, n_output) or (n_samples,), default=None 用于分類或回歸的X對應的標簽;無監督學習為None。 |
| 返回值 | 說明 |
|---|---|
| score | float |
set_params(self, **params)
[源碼]
設置估計器的參數。
該方法適用于簡單的估計器以及嵌套對象(例如pipelines)。后者具有形式參數 <component>__<parameter>以便可以更新嵌套對象的每個組件。
| 參數 | 說明 |
|---|---|
| **params | dict 估算器參數。 |
| 返回值 | 說明 |
|---|---|
| self | object 估算器實例。 |
transform(self, X)
[源碼]
使用找到的最優參數在估計器上調用transform。
僅在基礎估計器支持transform和refit=True時可用。
| 參數 | 說明 |
|---|---|
| X | indexable, length n_samples 必須滿足基礎估算器的輸入假設。 |