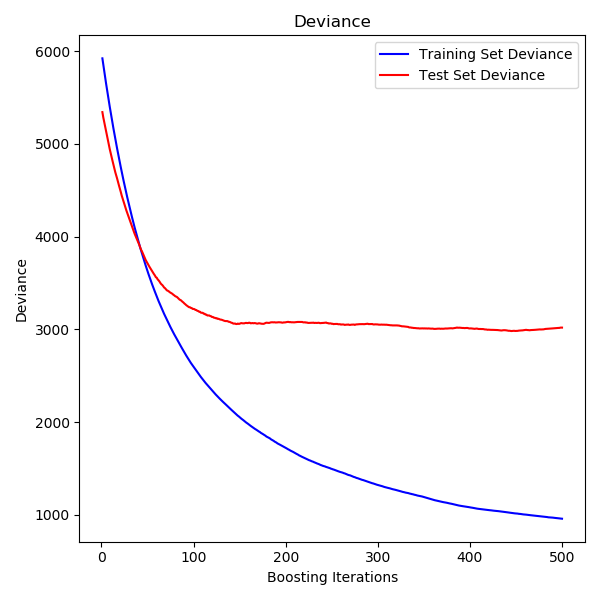
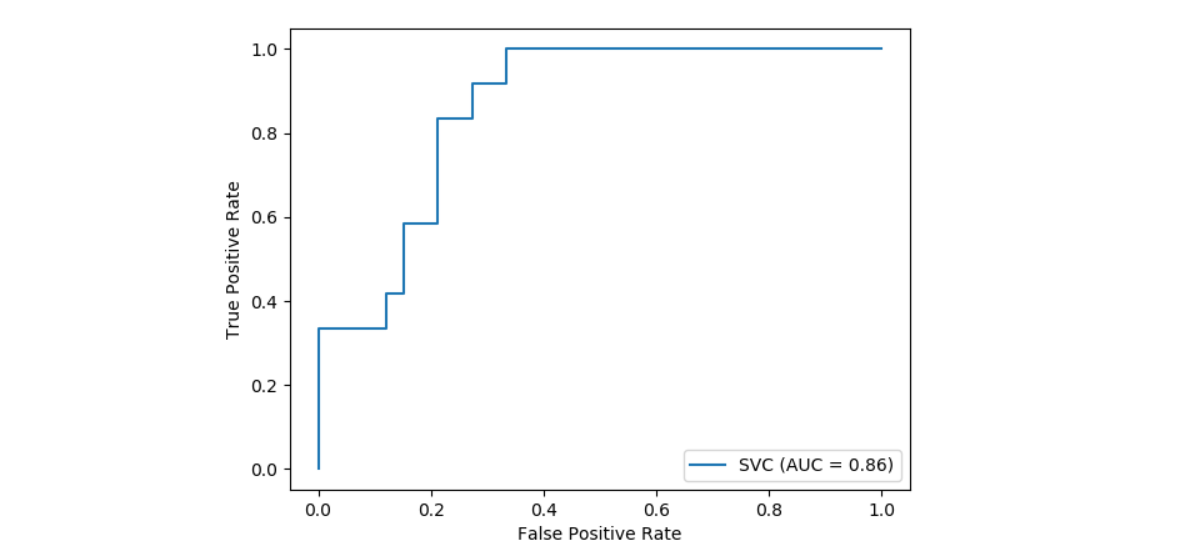
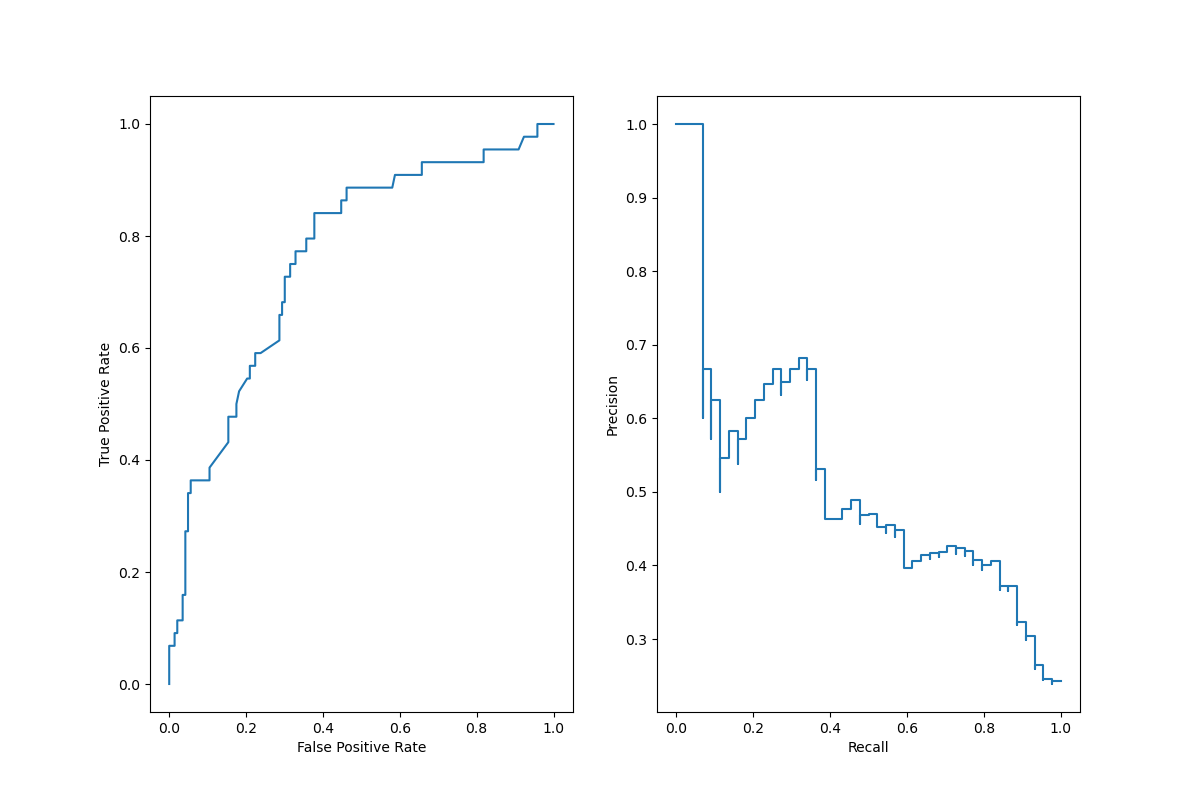
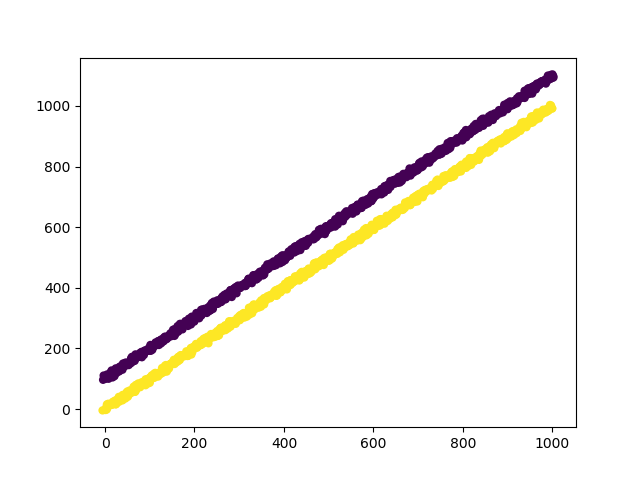
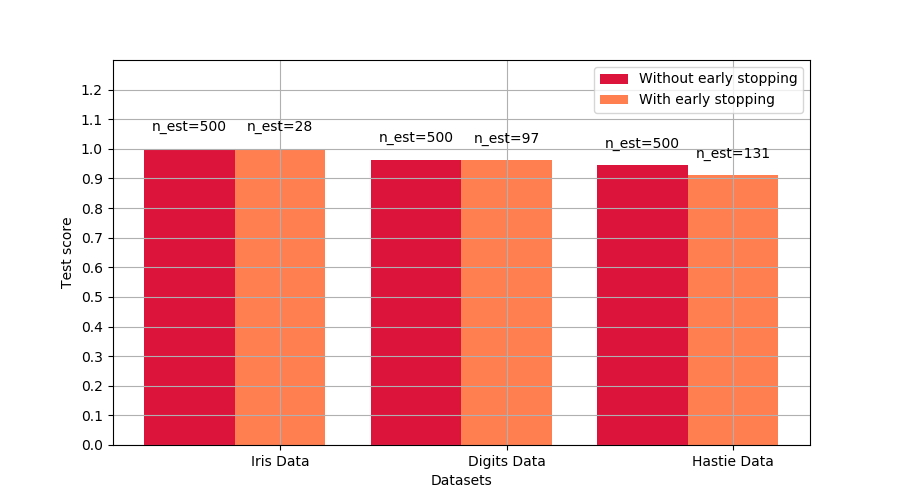
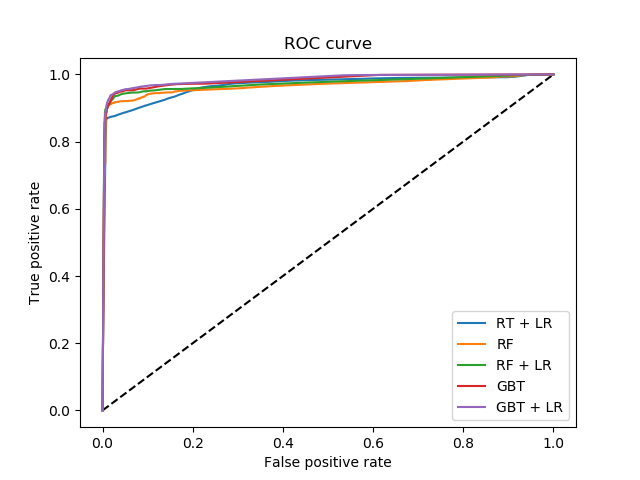
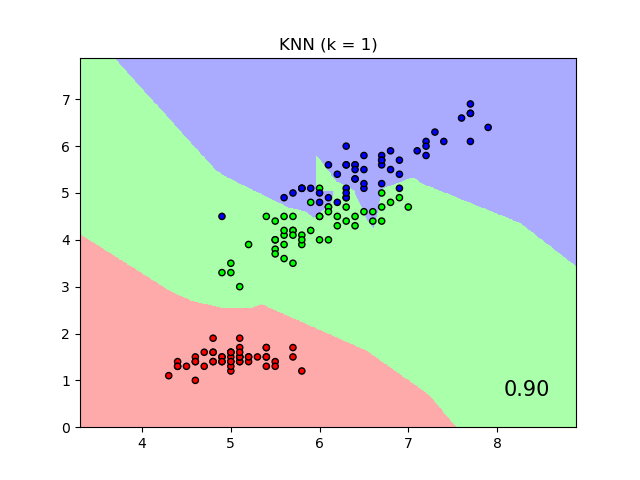
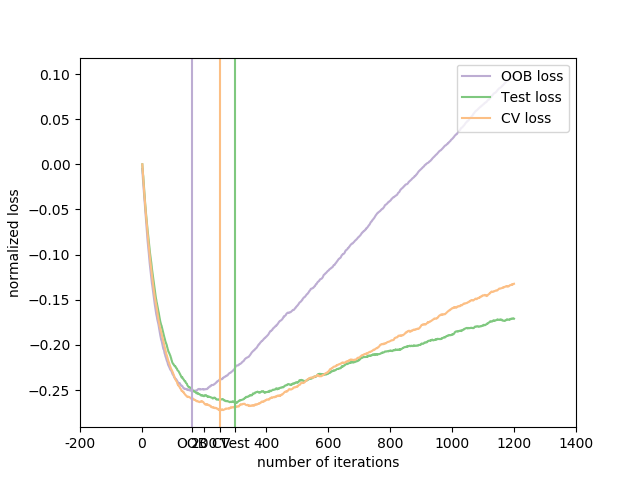
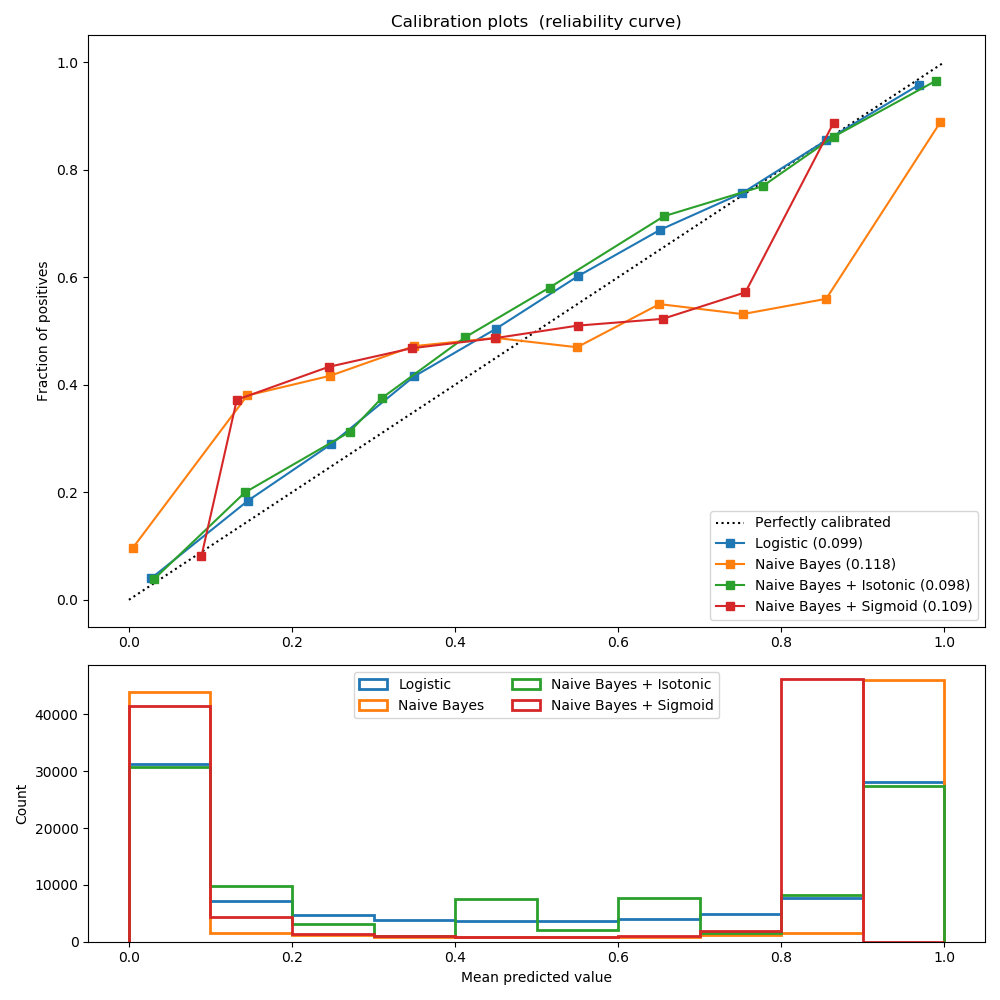
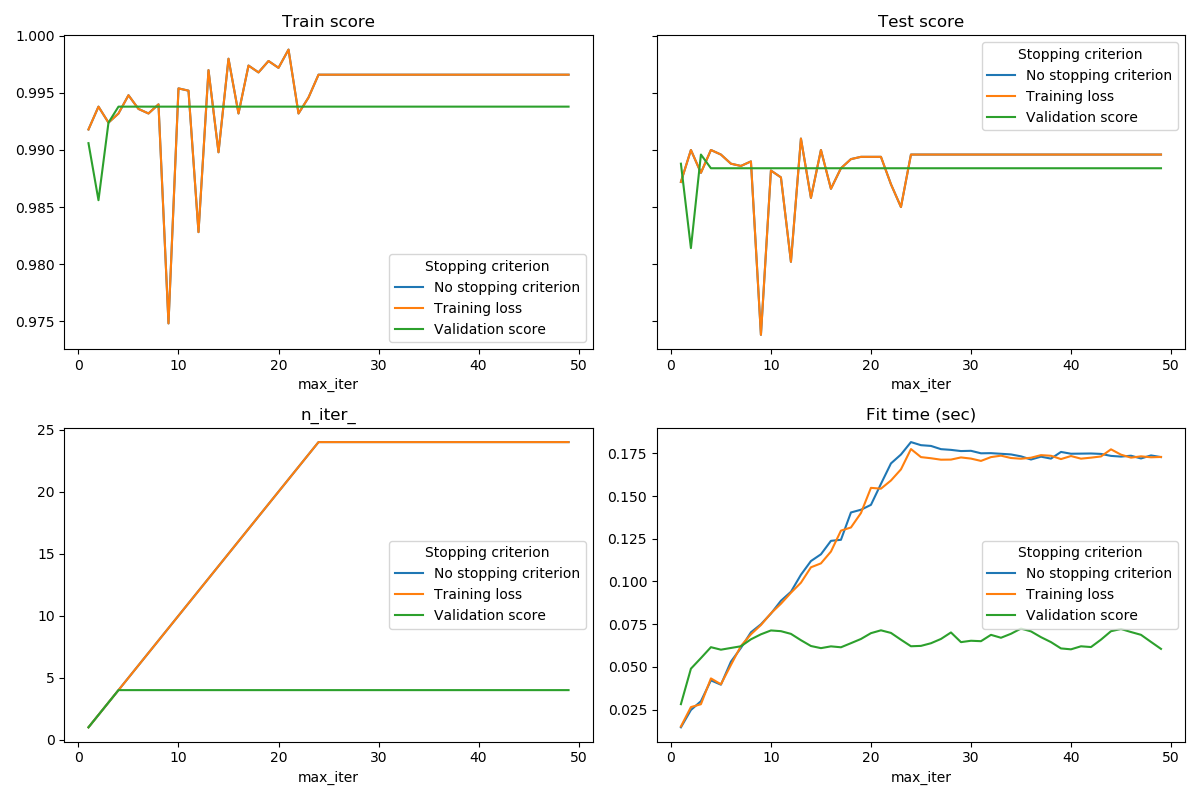
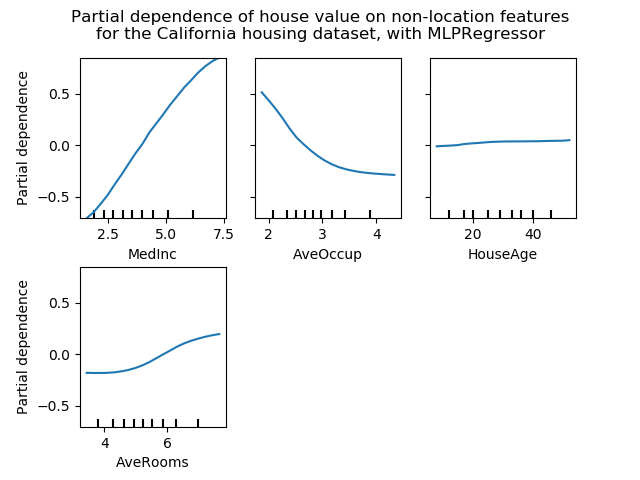
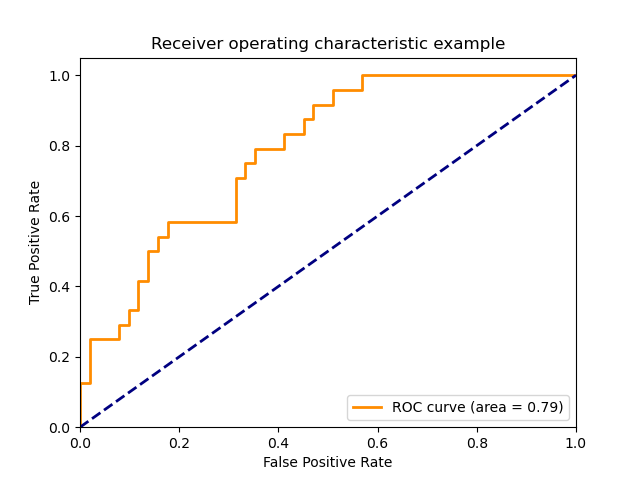
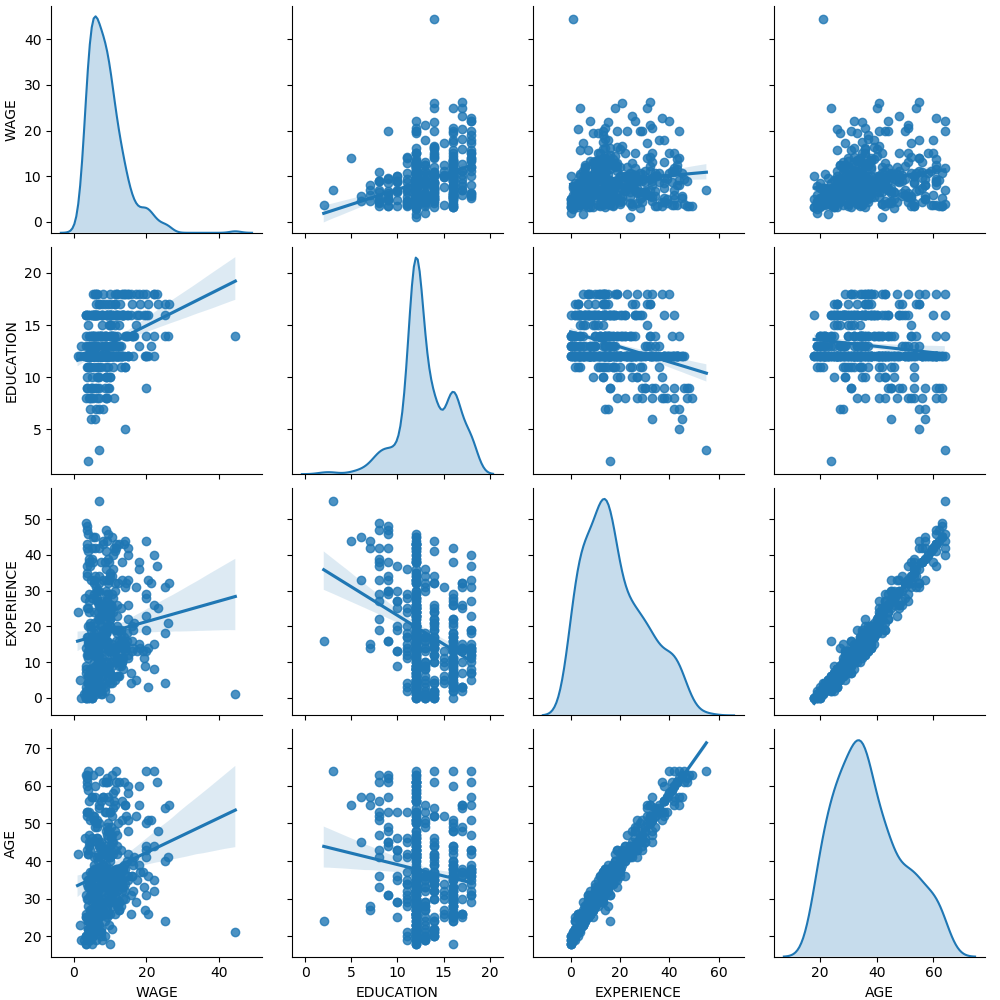
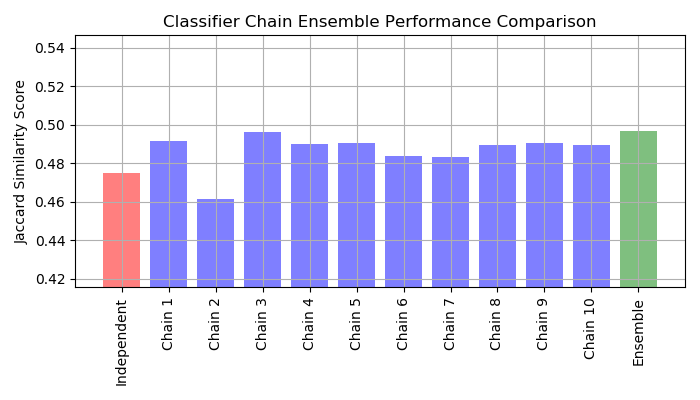
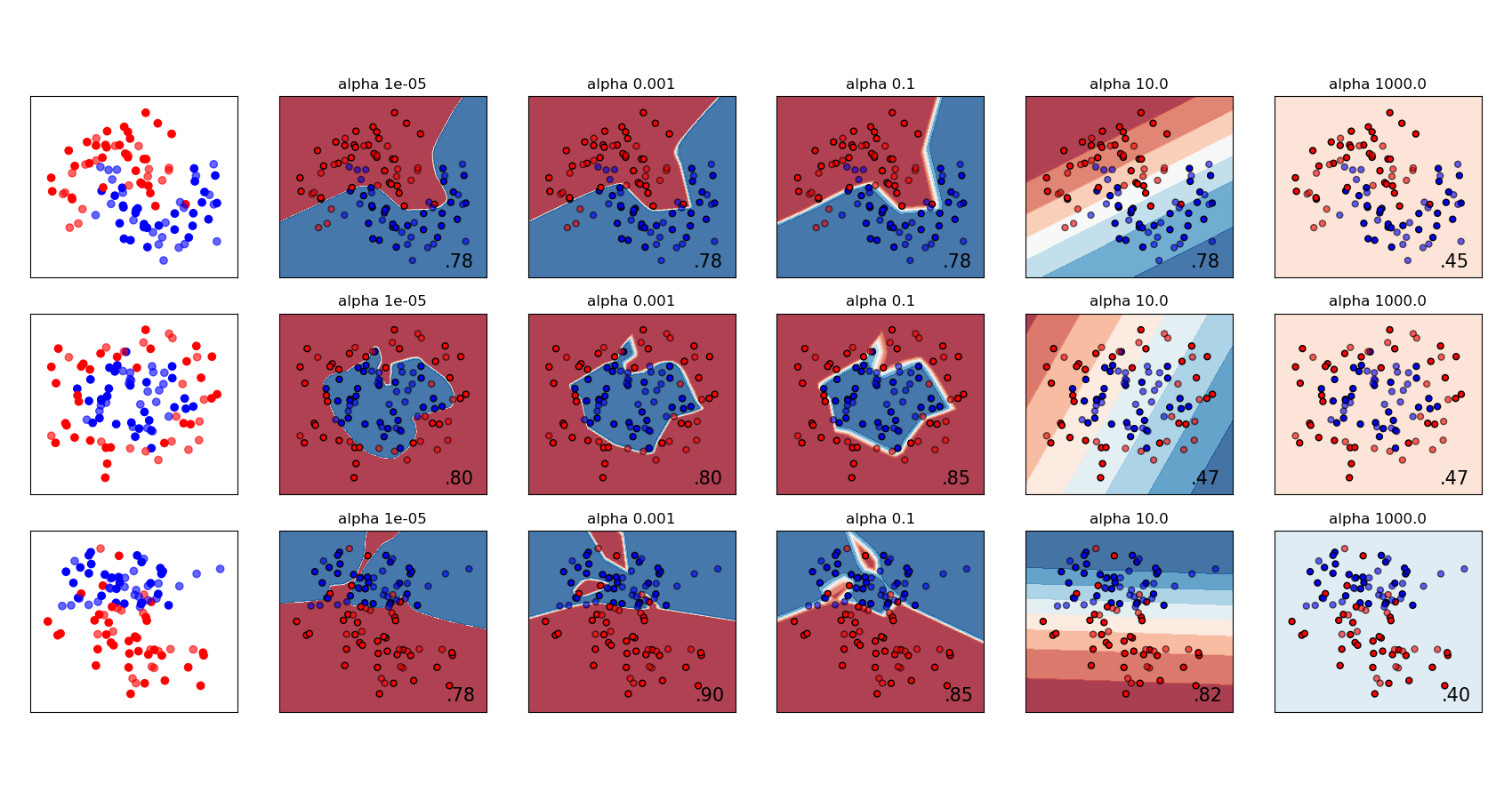
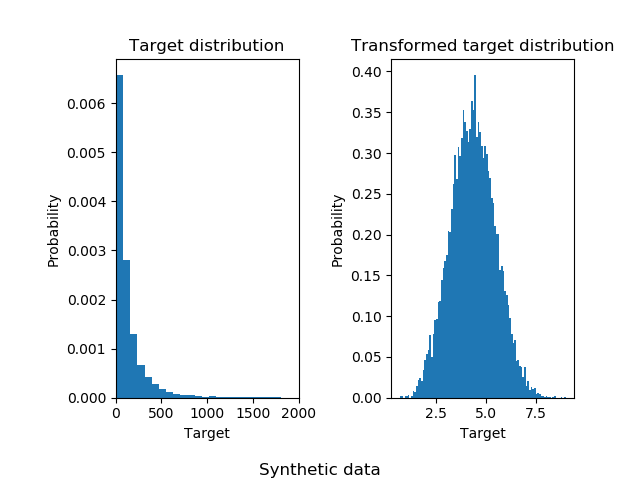
sklearn.model_selection.train_test_split?
sklearn.model_selection.train_test_split(* arrays,** options )
將數組或矩陣切分為隨機訓練和測試子集。
這個快速實用程序封裝了輸入驗證和next(ShuffleSplit().split(X, y))以及應用程序,以便將數據輸入到單個調用中,在oneliner中對數據進行切分(或選擇性的進行二次采樣)。
在用戶指南中閱讀更多內容。
| 參數 | 說明 |
|---|---|
| *arrays | sequence of indexables with same length / shape[0] 允許的輸入是列表,numpy數組,稀疏矩陣或padas中的DataFrame。 |
| test_size | float or int, default=None 如果為float,則應在0.0到1.0之間,表示要包括在測試集切分中的數據集的比例。如果為int,則表示測試集樣本的絕對數量。如果為None,則將值設置為訓練集大小的補集。如果 train_size也是None,則將其設置為0.25。 |
| train_size | float or int, default=None 如果為float,則應在0.0到1.0之間,并表示要包含在訓練集切分中的數據集的比例。如果為int,則表示訓練集樣本的絕對數量。如果為None,則該值將自動設置為測試集大小的補集。 |
| random_state | int or RandomState instance, default=None 在應用切分之前,控制應用于數據的無序處理。為多個函數調用傳遞可重復輸出的int值。請參閱詞匯表。 |
| shuffle | bool, default=True 切分前是否對數據進行打亂。如果shuffle = False,則stratify必須為None。 |
| stratify | array-like, default=None 如果不為None,則以分層方式切分數據,并將其用作類標簽。 |
| 返回值 | 說明 |
|---|---|
| splitting | list, length=2 * len(arrays) 列表包含切分后的訓練集和測試集 版本0.16中的新功能:如果輸入稀疏,則輸出將為 scipy.sparse.csr_matrix 。否則,輸出類型與輸入類型相同。 |
示例
>>> from sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> list(y)
[0, 1, 2, 3, 4]
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.33, random_state=42)
...
>>> X_train
array([[4, 5],
[0, 1],
[6, 7]])
>>> y_train
[2, 0, 3]
>>> X_test
array([[2, 3],
[8, 9]])
>>> y_test
[1, 4]
>>> train_test_split(y, shuffle=False)
[[0, 1, 2], [3, 4]]