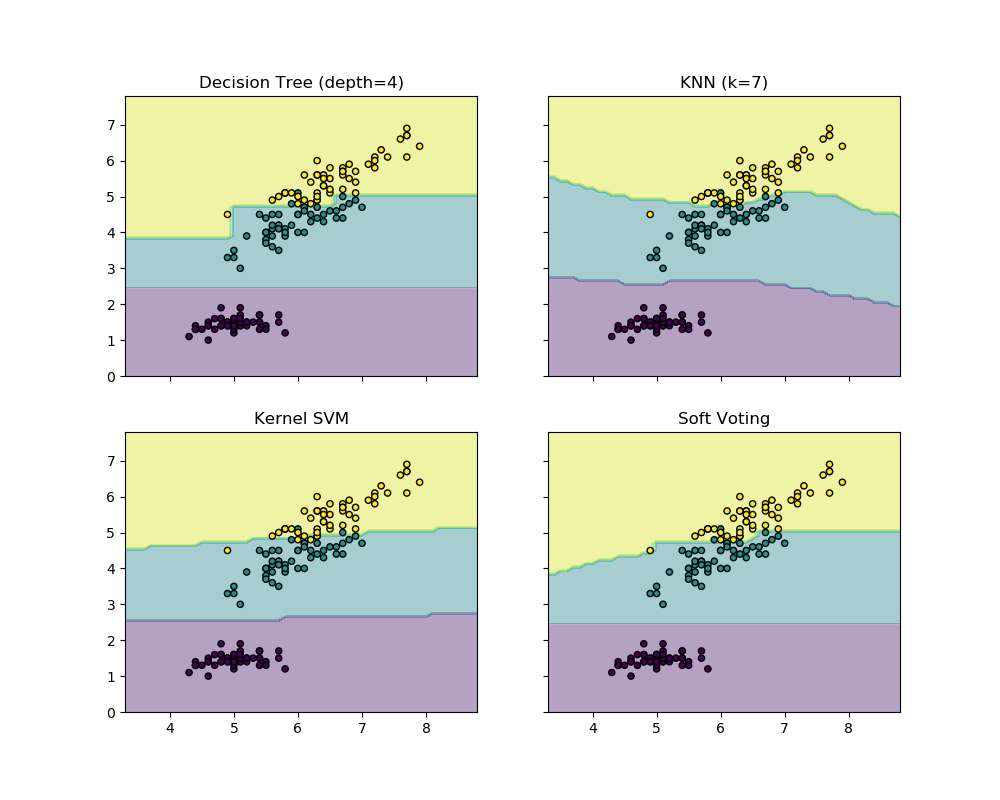
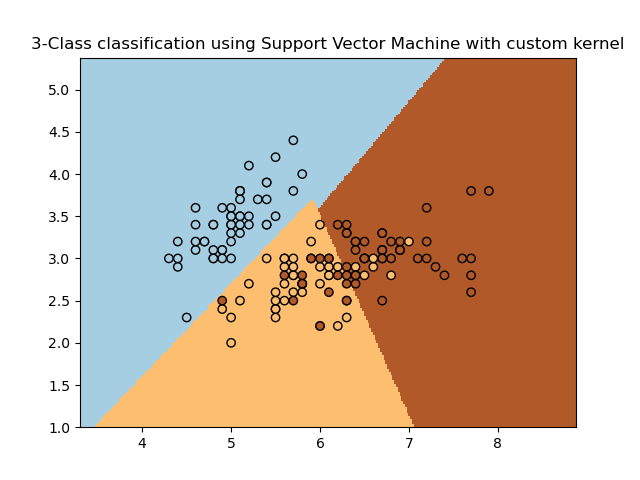
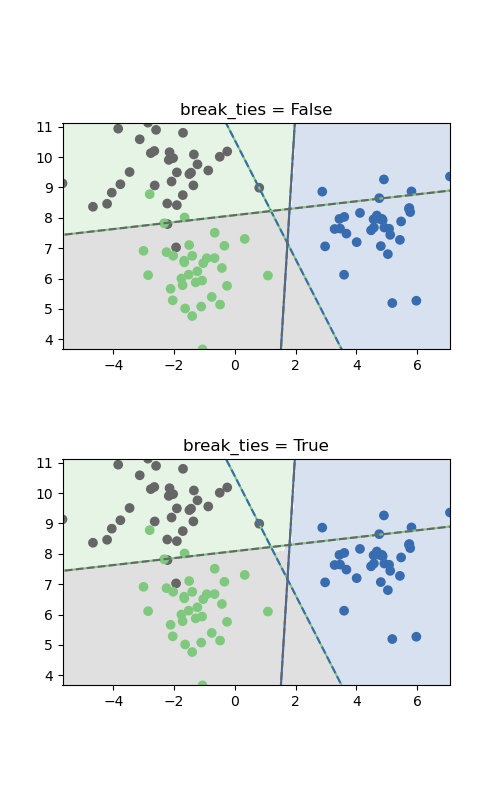
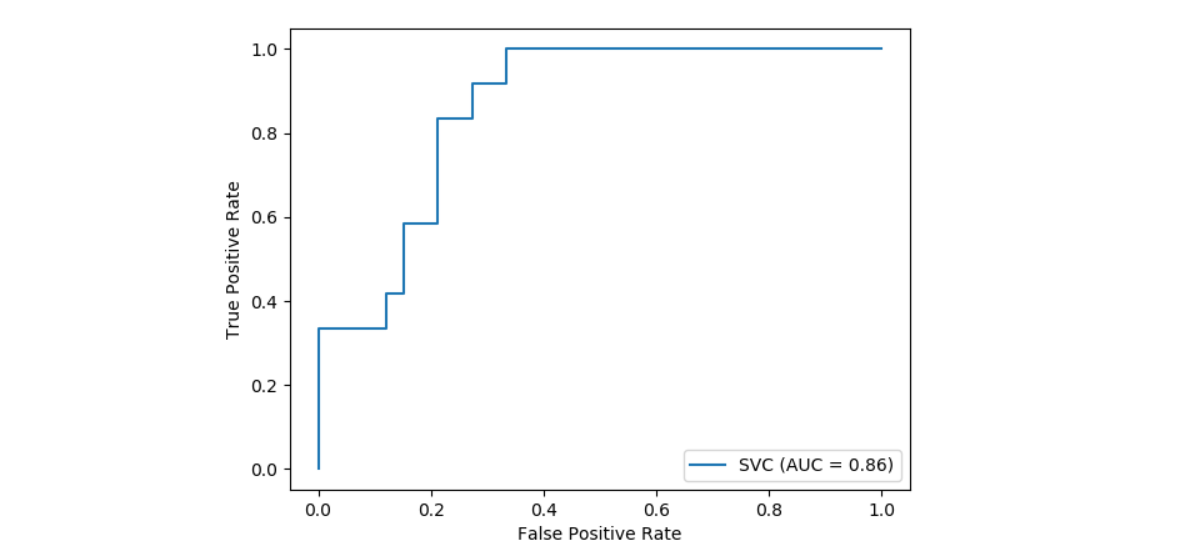
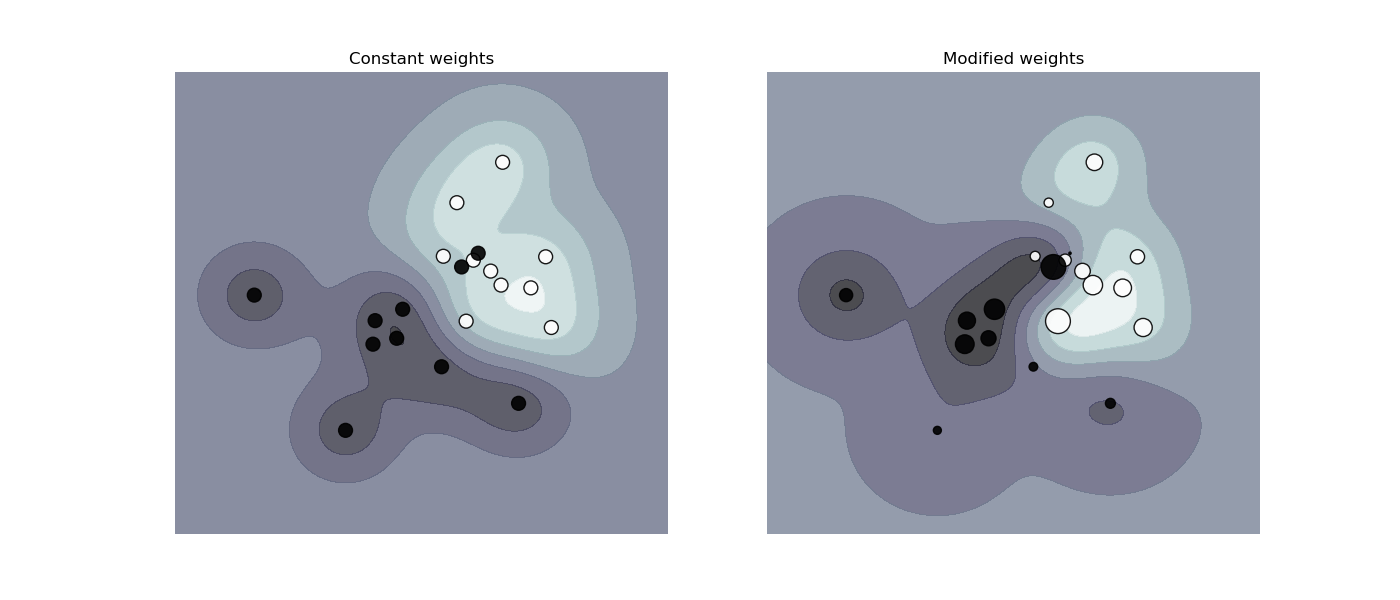
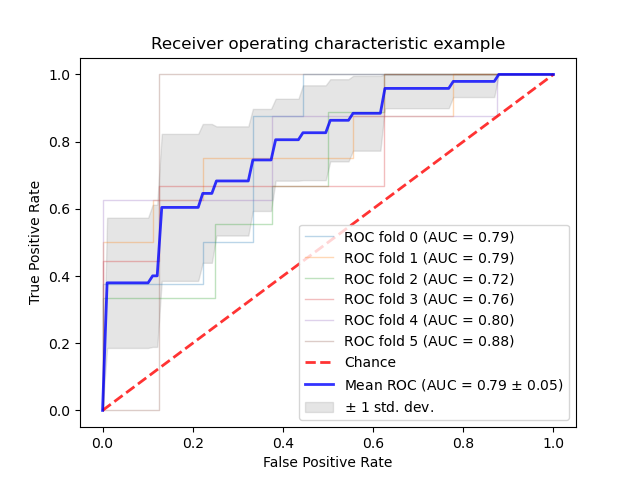
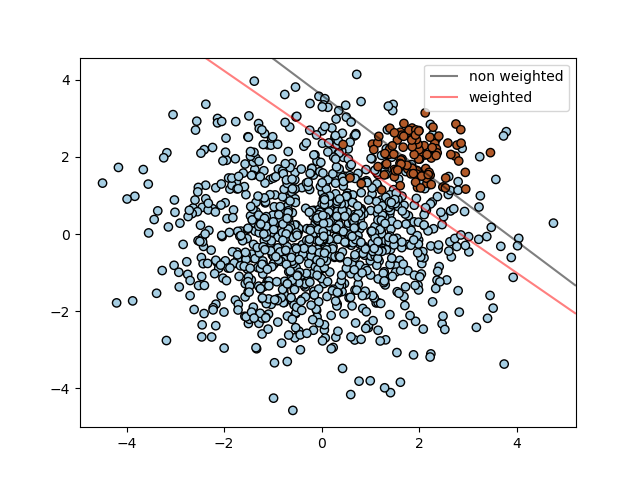
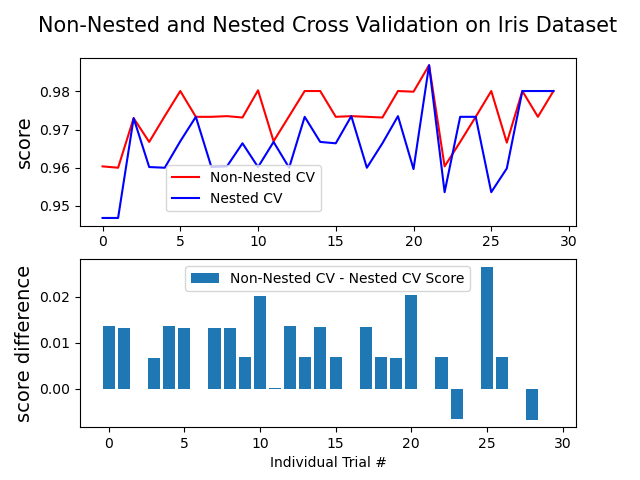
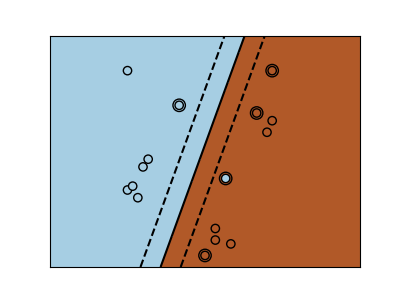
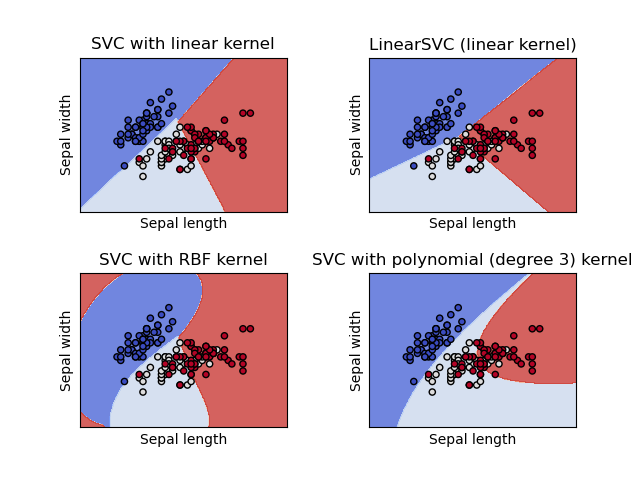
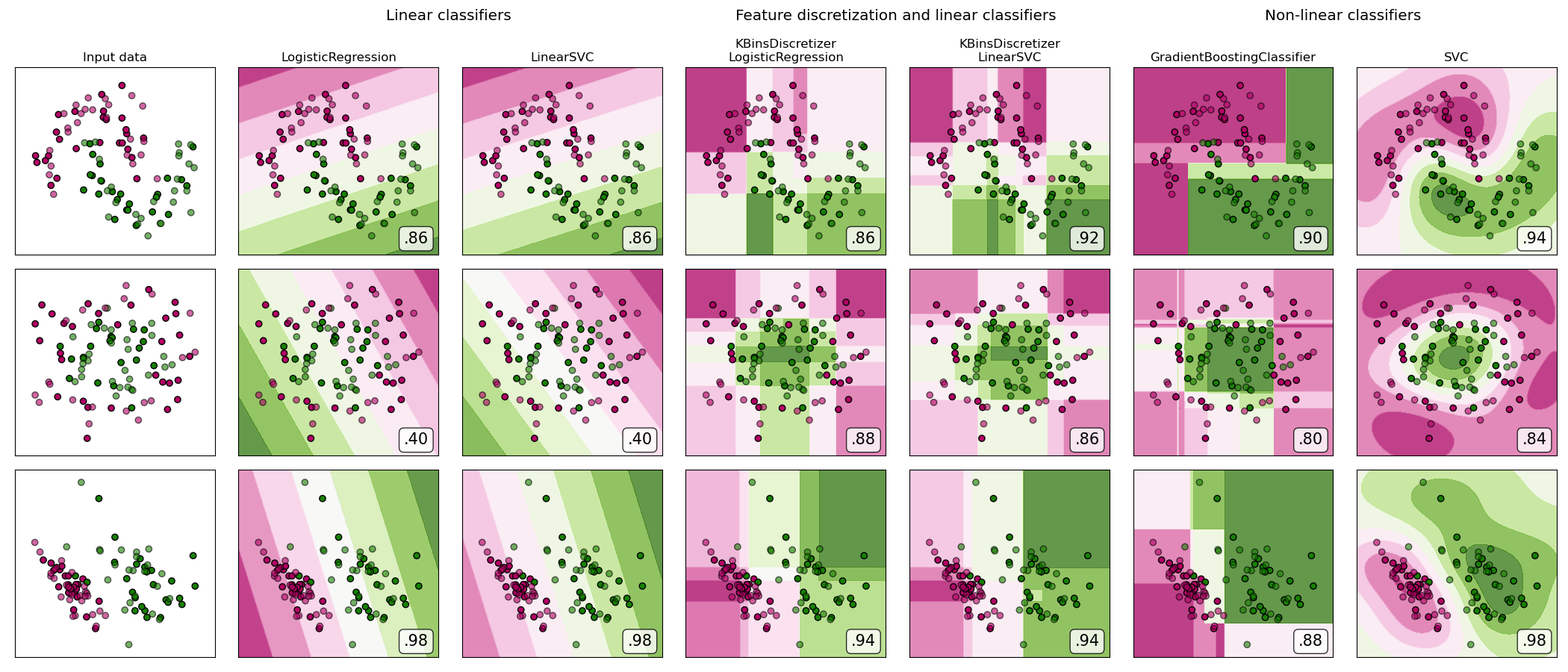
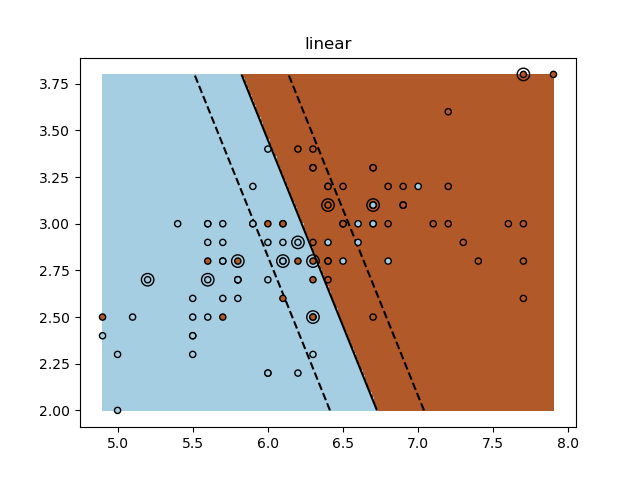
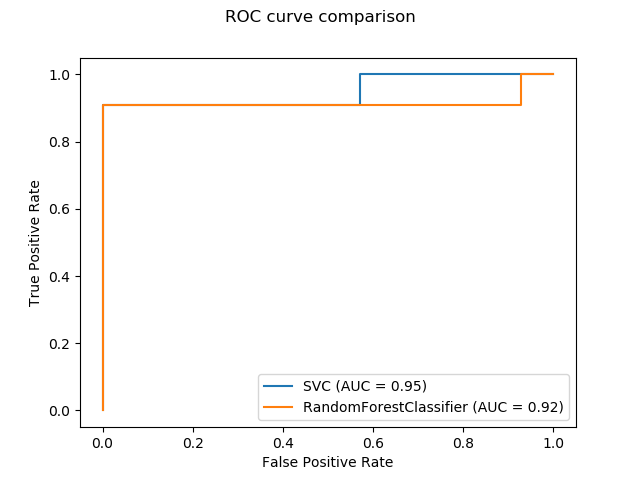
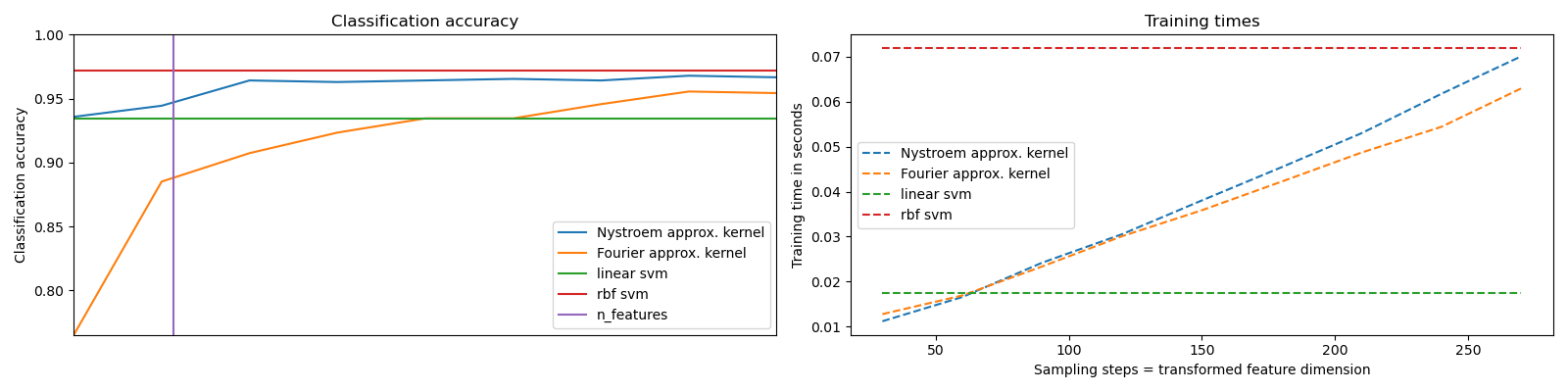
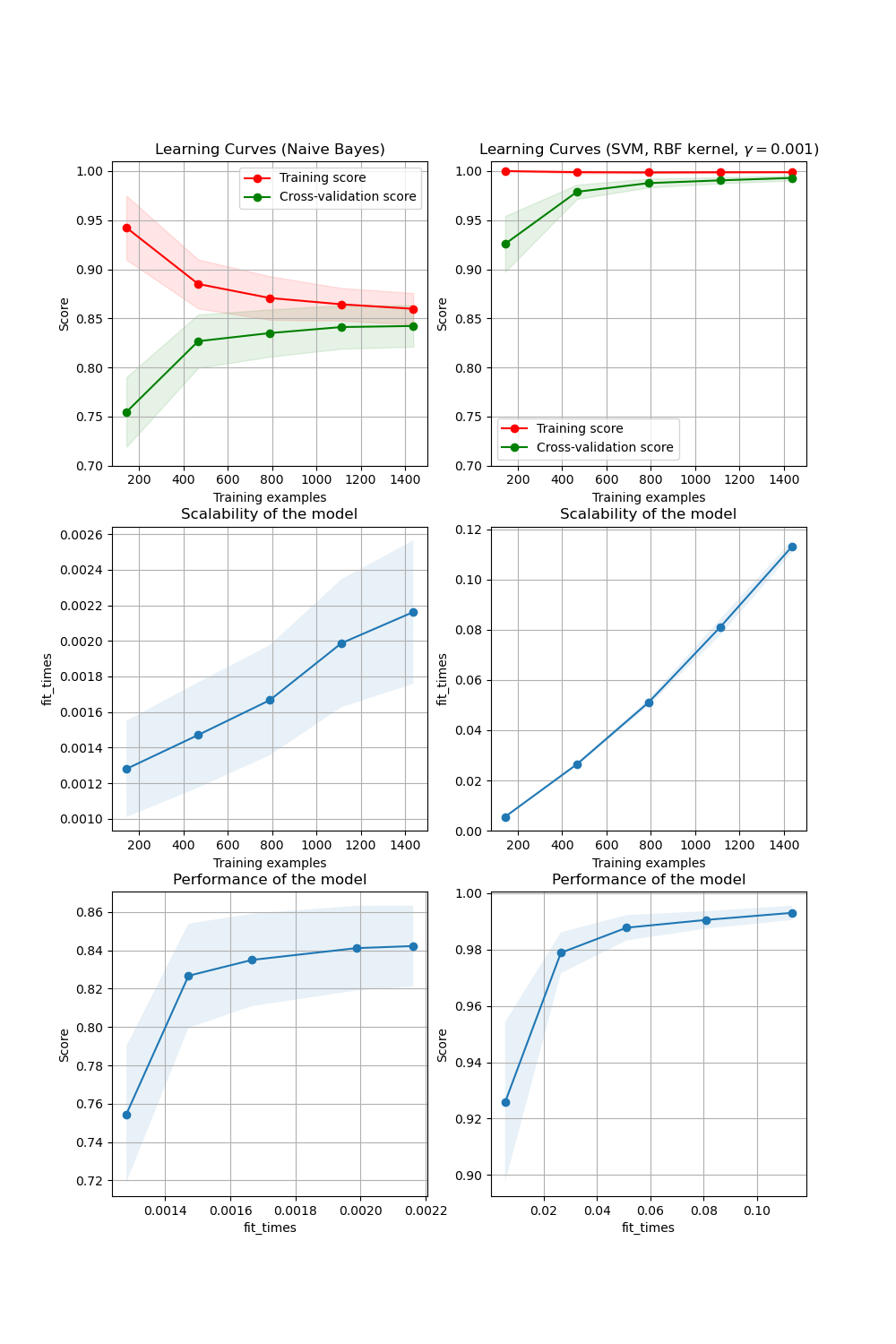
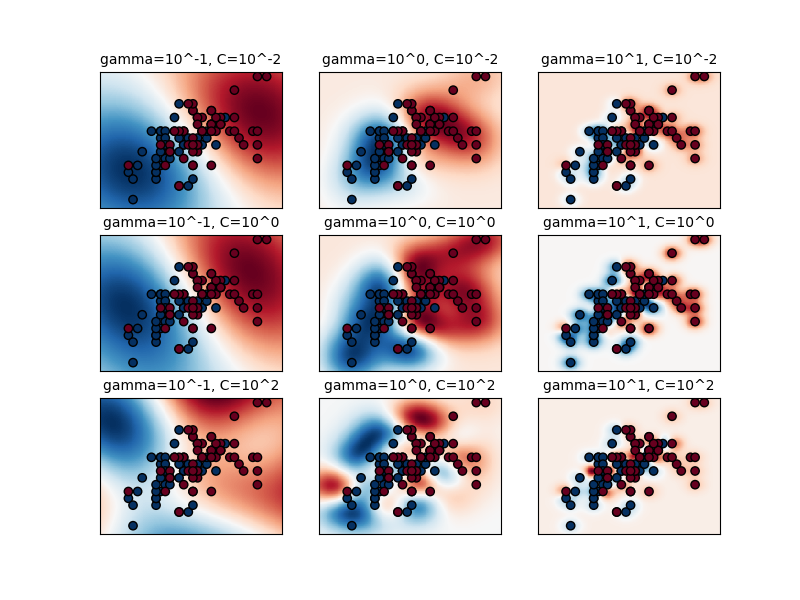
sklearn.svm.SVC?
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
C支持向量分類。
該實現基于libsvm。擬合時間至少與樣本數量成二次關系,如果樣本數量超過數萬個,擬合時間可能不現實。對于大數據集,可以考慮在使用了 sklearn.kernel_approximation.Nystroem 后,用 sklearn.svm.LinearSVC 或sklearn.linear_model.SGDClassifier 替代。
多類支持是根據one vs-one方案處理的。
關于提供的核函數的精確數學公式以及gamma、coef0和degree如何相互影響的詳細信息,請參閱敘述文檔中的相應章節: Kernel functions。
更多信息請參閱 使用指南.
| 參數 | 說明 |
|---|---|
| C | 浮點數,默認= 1.0 正則化參數。正則化的強度與C成反比。必須嚴格為正。此懲罰系數是l2懲罰系數的平方 |
| kernel | {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, 默認=’rbf’ 指定算法中使用的內核類型。它必須是“linear”,“poly”,“rbf”,“sigmoid”,“precomputed”或者“callable”中的一個。如果沒有給出,將默認使用“rbf”。如果給定了一個可調用函數,則用它來預先計算核矩陣。該矩陣應為形狀數組 (n_samples,n_samples) |
| degree | 整數型,默認=3 多項式核函數的次數(' poly ')。將會被其他內核忽略。 |
| gamma | 浮點數或者{‘scale’, ‘auto’} , 默認=’scale’ 核系數包含‘rbf’, ‘poly’ 和‘sigmoid’ 如果gamma='scale'(默認),則它使用1 / (n_features * X.var())作為gamma的值,如果是auto,則使用1 / n_features。 在0.22版本有改動:默認的gamma從“auto”改為“scale”。 |
| coef0 | 浮點數,默認=0.0 核函數中的獨立項。它只在' poly '和' sigmoid '中有意義。 |
| shrinking | 布爾值,默認=True 是否使用縮小啟發式,參見使用指南 |
| probability | 布爾值,默認=False 是否啟用概率估計。必須在調用fit之前啟用此參數,因為該方法內部使用5折交叉驗證,因此會減慢該方法的速度,并且predict_proba可能與dict不一致。更多信息請閱讀使用指南 |
| tol | 浮點數,默認=1e-3 殘差收斂條件。 |
| cache_size | 浮點數,默認=200 指定內核緩存的大小(以MB為單位)。 |
| class_weight | {dict, ‘balanced’}, 默認=None 在SVC中,將類i的參數C設置為class_weight [i] * C。如果沒有給出值,則所有類都將設置為單位權重。“balanced”模式使用y的值自動將權重與類頻率成反比地調整為 n_samples / (n_classes * np.bincount(y)) |
| verbose | 布爾值,默認=False 是否啟用詳細輸出。請注意,此參數針對liblinear中運行每個進程時設置,如果啟用,則可能無法在多線程上下文中正常工作。 |
| max_iter | 整數型,默認=-1 對求解器內的迭代進行硬性限制,或者為-1(無限制時)。 |
| decision_function_shape | {‘ovo’, ‘ovr’}, 默認=’ovr’ 是否要將返回形狀為(n_samples, n_classes)的one-vs-rest (‘ovr’)決策函數應用于其他所有分類器,而在多類別劃分中始終使用one-vs-one (‘ovo’),對于二進制分類,將忽略該參數。 在版本0.19中進行了更改:默認情況下Decision_function_shape為ovr。 0.17版中的新功能:推薦使用Decision_function_shape ='ovr'。 在0.17版中進行了更改:不建議使用Decision_function_shape ='ovo'和None。 |
| break_ties | bool, default=False 如果為true,decision_function_shape ='ovr',并且類數> 2,則預測將根據Decision_function的置信度值打破平局;否則,返回綁定類中的第一類。請注意,與簡單的預測相比,打破平局的計算成本較高。 這是0.22版中的新功能。 |
| random_state | 整數型或RandomState的實例,默認=None 控制用于數據抽取時的偽隨機數生成。當 probability為False時將忽略該參數。在多個函數調用之間傳遞可重復輸出的整數值。請參閱詞匯表。 |
| 屬性 | 說明 |
|---|---|
| support_ | 形如(n_SV,)的數組 支持向量的指標。 |
| support_vectors_ | 形如(n_SV, n_features)的數組 支持向量 |
| n_support_ | 形如(n_class)的數組,dtype=int32 每個類別的支持向量數量。 |
| dual_coef_ | 形如(n_class-1, n_SV)的數組 決策函數中支持向量的對偶系數(請參見數學公式)。對于多類別,為所有1-vs-1分類器的系數。在多類情況下,系數的布局有些微不足道。有關詳細信息,請參見multi-class section of the User Guide。 |
| coef_ | 形如(n_class * (n_class-1) / 2, n_features)的數組 分配給特征的權重(原始問題的系數),僅在線性內核的情況下可用。 coef_是一個繼承自raw_coef_的只讀屬性,它遵循liblinear的內部存儲器布局。 |
| intercept_ | 形如(n_class * (n_class-1) / 2,)的數組 決策函數中的常量。 |
| fit_status_ | 整數型 如果擬合無誤,則為0;如果算法未收斂,則為1。 |
| classes_ | 形如(n_classes,)的數組 不重復類別標簽 |
| probA_ | 形如(n_class * (n_class-1) / 2,)的數組 |
| probB_ | 形如(n_class * (n_class-1) / 2,)的數組 如果 probability=True,則它對應于在普拉特縮放中學習的參數,以根據決策值產生概率估計。如果probability=False,則為空數組。普拉特定標使用邏輯函數1 /(1 + exp(decision_value * probA_ + probB_)),其中從數據集[2]了解probA_和probB_。有關多類案件和培訓程序的更多信息,請參見[1]的第8節。 |
| class_weight_ | 形如(n_class,)的數組 每個類的參數C的乘數。根據 class_weight參數進行計算。 |
| shape_fit_ | 形如(n_dimensions_of_X,)的整數型元祖 訓練向量 X的數組維度 |
另見:
支持向量機使用libsvm實現。
可擴展線性支持向量機使用liblinear進行分類。
參考文獻:
示例:
>>> import numpy as np
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
>>> y = np.array([1, 1, 2, 2])
>>> from sklearn.svm import SVC
>>> clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))
>>> clf.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('svc', SVC(gamma='auto'))])
>>> print(clf.predict([[-0.8, -1]]))
[1]
方法:
decision_function(X) |
計算X中樣本的決策函數。 |
|---|---|
fit(X, y[, sample_weight]) |
根據給定的訓練數據擬合支持向量機模型。 |
get_params([deep]) |
獲取這個估計器的參數。 |
predict(X) |
在X中對樣本進行分類 |
score(X, y[, sample_weight]) |
返回給定測試數據和標簽的平均精度。 |
set_params(**params) |
設置這個估計器的參數。 |
__init__(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
初始化self。請參閱help(type(self)獲取準確的說明。
計算X中樣本的決策函數。
| 參數 | 說明 |
|---|---|
| X | 形如(n_samples, n_features)的數組 |
| 返回值 | 說明 |
|---|---|
| X | 形如 (n_samples, n_classes * (n_classes-1) / 2)的數組 返回模型中每個類的樣本決策函數。如果decision_function_shape =“ ovr”,則形狀為(n_samples,n_classes)。 |
注:
若decision_function_shape= ' ovo ',則函數值與樣本X到分離超平面的距離成正比。如果需要精確的距離,用函數值除以權值向量的范數(coef_)。更多細節請參見 這個問題 。若decision_function_shape= ' ovr ',則該決策函數是ovo決策函數的單調變換。
fit(X, y, sample_weight=None)
根據給定的訓練數據擬合支持向量機模型。
| 參數 | 說明 |
|---|---|
| X | 形如(n_samples, n_features) 或者 (n_samples, n_samples)的數組或者稀疏矩陣 訓練向量,其中n_samples為樣本數量,n_features為特征數量。對于kernel= " precomputed ", X的期望形狀為(n_samples, n_samples)。 |
| y | 形如(n_samples,)的數組 目標值(分類中的類標簽,回歸中的實數) |
| sample_weight | 形如(n_samples,)的數組,默認=None 樣本的權重。每個樣品重新定標C。較高的權重將使分類器更加注重這些樣本點。 |
| 返回值 | 說明 |
|---|---|
| self | object |
注:
如果X和y不是C-ordered,并且np.float64和X的連續數組不是scipy.sparse.csr_matrix,則可以復制X或y。
如果X是一個連續數組,則其他方法將不支持將稀疏矩陣作為輸入。
get_params(deep=True)
| 參數 | 說明 |
|---|---|
| deep | bool, default = True 如果為真,則將返回此估計量和作為估計量的所包含子對象的參數 |
| 返回值 | 說明 |
|---|---|
| params | mapping of string to any 參數名被映射至他們的值 |
predict(X)
對X中的樣本執行分類。
對于返回值為+1或-1的one-class模型
| 參數 | 說明 |
|---|---|
| X | 形如(n_samples, n_features) 或者 (n_samples_test, n_samples_train)的數組或者稀疏矩陣 對于內核=“precomputed”,X的預期形狀為(n_samples_test,n_samples_train)。 |
| 返回值 | 說明 |
|---|---|
| y_pred | 形如(n_sample, )的數組 X中樣本的類別標簽。 |
property predict_log_proba
計算X中樣本的可能結果的對數概率。
該模型需要在訓練時計算概率信息:將屬性概率設置為True。
| 參數 | 說明 |
|---|---|
| X | 形如(n_samples, n_features) 或者 (n_samples_test, n_samples_train)的數組或者稀疏矩陣 對于內核=“precomputed”,X的預期形狀為(n_samples_test,n_samples_train)。 |
| 返回值 | 說明 |
|---|---|
| T | 形如(n_sample, n_classes)的數組 返回模型中每個類的樣本的對數概率。列與出現在屬性classes_中的類別按順序對應。 |
注:
概率模型是通過交叉驗證建立的,因此其結果可能與通過預測得到的結果略有不同。而且,它會在非常小的數據集上產生無意義的結果。
property predict_proba
計算X中樣本可能出現結果的概率。
模型需要在訓練時計算出概率信息:將屬性概率設置為True。
| 參數 | 說明 |
|---|---|
| X | 形如(n_samples, n_features)的數組 對于內核=“precomputed”,X的預期形狀為(n_samples_test,n_samples_train)。 |
| 返回值 | 說明 |
|---|---|
| T | 形如(n_sample, n_classes)的數組 返回模型中每個類的樣本的概率。列與出現在屬性classes_中的類別按順序對應。 |
注:
概率模型是通過交叉驗證建立的,因此其結果可能與通過預測得到的結果略有不同。而且,它會在非常小的數據集上產生無意義的結果。
score(X, y, sample_weight=None)
返回給定測試數據和標簽上的平均準確度。
在多標簽分類中,這是子集精度,這是一個苛刻的指標,因為你需要對每個樣本正確預測每個標簽集。
| 參數 | 說明 |
|---|---|
| X | 形如 (n_samples, nfeatures)的數組 測試樣本 |
| y | 形如 (n_sample, ) 或者 (n_samples, n_outputs)的數組 X中結果為真的標簽 |
| sample_weight | 形如(n_samples,)的數組,默認=None 樣本的權重 |
| 返回值 | 說明 |
|---|---|
| score | 浮點型 self.predict(X) wrt. y.的平均精度 |
set_params(self, **params)
設置當前估計量的參數。
該方法適用于簡單估計量和嵌套對象(如pipline)。后者具有形式為<component>_<parameter>的參數,這樣就讓更新嵌套對象的每個組件成為了可能。
| 參數 | 說明 |
|---|---|
| **f_params | dict 估計量參數 |
| 返回值 | 說明 |
|---|---|
| self | object 估計器實例 |